AWS Big Data Blog
Category: Amazon EMR

Optimize Amazon EMR costs with idle checks and automatic resource termination using advanced Amazon CloudWatch metrics and AWS Lambda
Many customers use Amazon EMR to run big data workloads, such as Apache Spark and Apache Hive queries, in their development environment. Data analysts and data scientists frequently use these types of clusters, known as analytics EMR clusters. Users often forget to terminate the clusters after their work is done. This leads to idle running […]
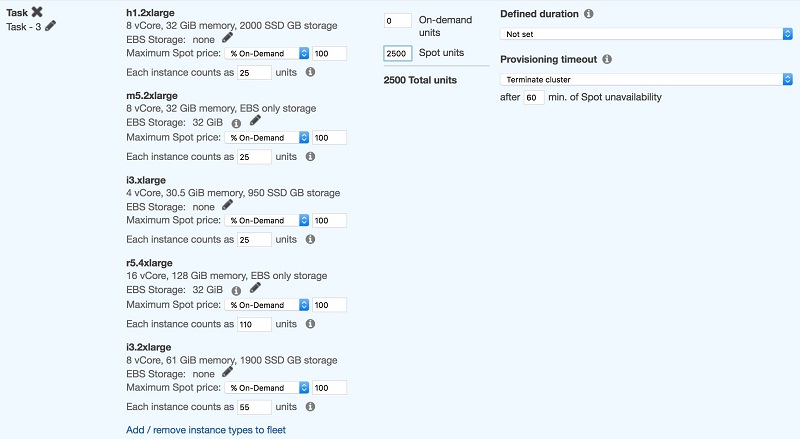
Best practices for running Apache Spark applications using Amazon EC2 Spot Instances with Amazon EMR
In this blog post, we are going to focus on cost-optimizing and efficiently running Spark applications on Amazon EMR by using Spot Instances. We recommend several best practices to increase the fault tolerance of your Spark applications and use Spot Instances. These work without compromising availability or having a large impact on performance or the length of your jobs.

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]

Spark enhancements for elasticity and resiliency on Amazon EMR
This blog post provides an overview of the issues with how open-source Spark handles node loss and the improvements in Amazon EMR to address the issues.
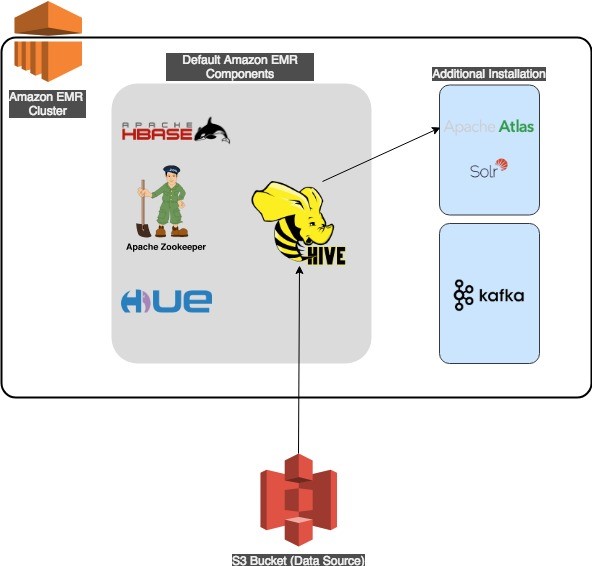
Metadata classification, lineage, and discovery using Apache Atlas on Amazon EMR
This blog post was last reviewed and updated April, 2022. The code repositories used in this blog have been reviewed and updated to fix the solution With the ever-evolving and growing role of data in today’s world, data governance is an essential aspect of effective data management. Many organizations use a data lake as a […]
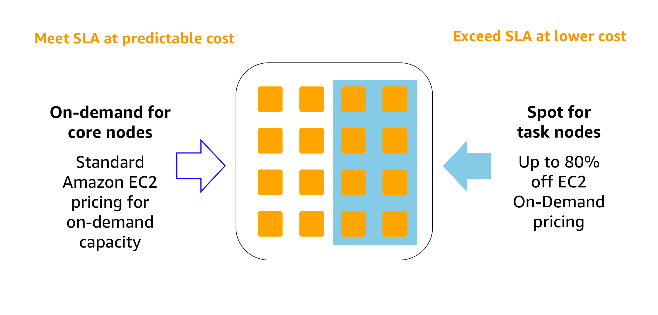
Reduce costs by migrating Apache Spark and Hadoop to Amazon EMR
Apache Spark and Hadoop are popular frameworks to process data for analytics, often at a fraction of the cost of legacy approaches, yet at scale they may still become expensive propositions. This blog post discusses ways to reduce your total costs of ownership, while also improving staff productivity at the same time. This can be […]
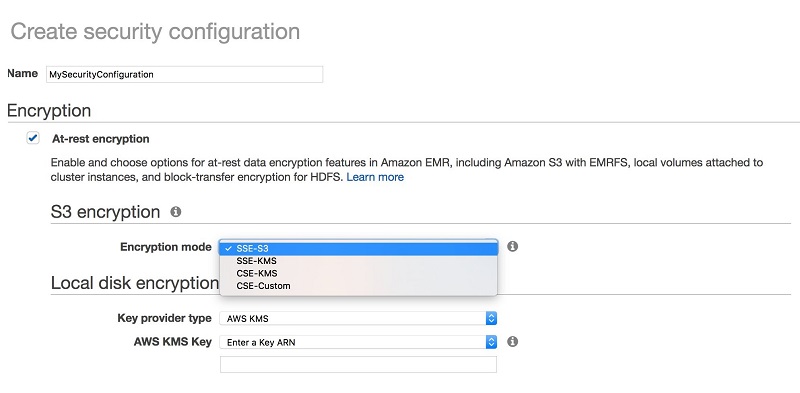
Best Practices for Securing Amazon EMR
This post walks you through some of the principles of Amazon EMR security. It also describes features that you can use in Amazon EMR to help you meet the security and compliance objectives for your business. We cover some common security best practices that we see used. We also show some sample configurations to get you started.
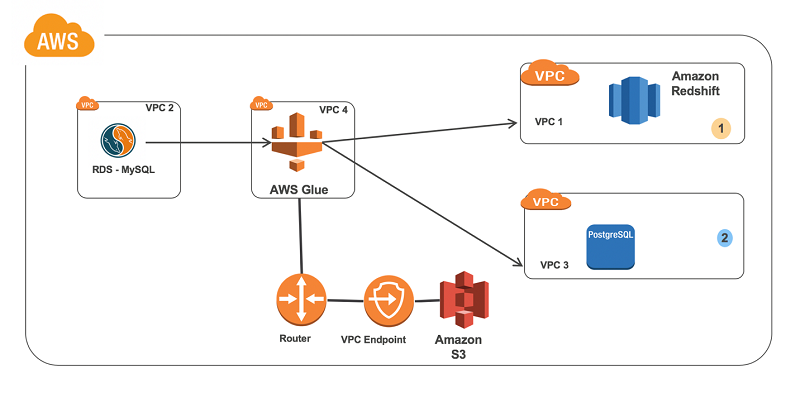
Connect to and run ETL jobs across multiple VPCs using a dedicated AWS Glue VPC
In this blog post, we’ll go through the steps needed to build an ETL pipeline that consumes from one source in one VPC and outputs it to another source in a different VPC. We’ll set up in multiple VPCs to reproduce a situation where your database instances are in multiple VPCs for isolation related to security, audit, or other purposes.
Dynamically scale up storage on Amazon EMR clusters
This post was last reviewed and updated July, 2022 with a new bootstrap action script and log instructions. In a managed Apache Hadoop environment—like an Amazon EMR cluster—when the storage capacity on your cluster fills up, there is no convenient solution to deal with it. This situation occurs because you set up Amazon Elastic Block […]

Migrate to Apache HBase on Amazon S3 on Amazon EMR: Guidelines and Best Practices
This whitepaper walks you through the stages of a migration. It also helps you determine when to choose Apache HBase on Amazon S3 on Amazon EMR, plan for platform security, tune Apache HBase and EMRFS to support your application SLA, identify options to migrate and restore your data, and manage your cluster in production.