AWS Big Data Blog
Category: Amazon EMR

Tune Hadoop and Spark performance with Dr. Elephant and Sparklens on Amazon EMR
This post demonstrates how to install Dr. Elephant and Sparklens on an Amazon EMR cluster and run workloads to demonstrate these tools’ capabilities. Amazon EMR is a managed Hadoop service offered by AWS to easily and cost-effectively run Hadoop and other open-source frameworks on AWS.
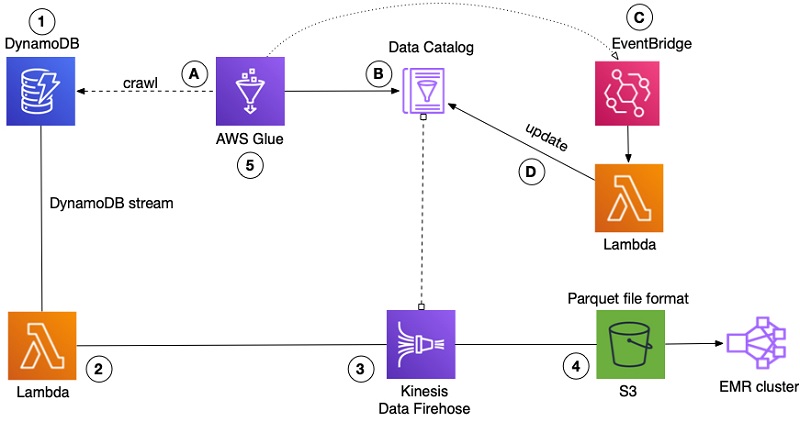
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions […]

How Verizon Media Group migrated from on-premises Apache Hadoop and Spark to Amazon EMR
This is a guest post by Verizon Media Group. At Verizon Media Group (VMG), one of the major problems we faced was the inability to scale out computing capacity in a required amount of time—hardware acquisitions often took months to complete. Scaling and upgrading hardware to accommodate workload changes was not economically viable, and upgrading […]
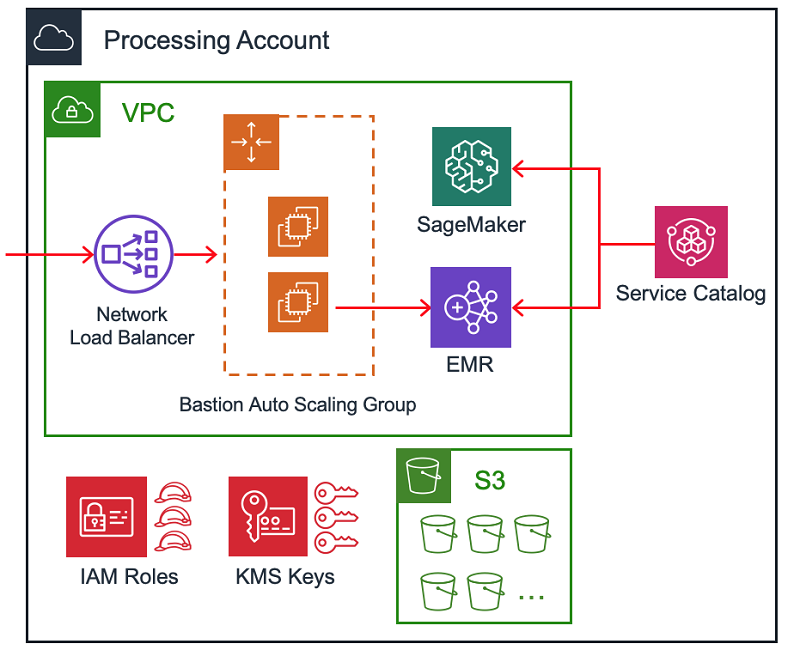
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation). We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.

Amazon EMR introduces EMR runtime for Apache Spark
Amazon EMR is happy to announce Amazon EMR runtime for Apache Spark, a performance-optimized runtime environment for Apache Spark that is active by default on Amazon EMR clusters. EMR runtime for Spark is up to 32 times faster than EMR 5.16, with 100% API compatibility with open-source Spark. This means that your workloads run faster, […]
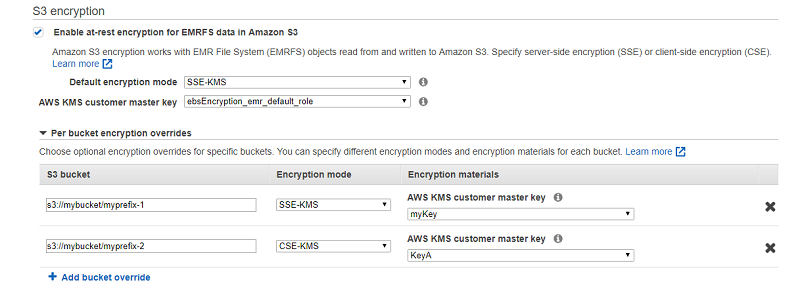
Secure your data on Amazon EMR using native EBS and per bucket S3 encryption options
This post provides a detailed walkthrough of two new encryption options to help you secure your EMR cluster that handles sensitive data. The first option is native EBS encryption to encrypt volumes attached to EMR clusters. The second option is an Amazon S3 encryption that allows you to use different encryption modes and customer master keys (CMKs) for individual S3 buckets with Amazon EMR.

Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 2
In Part 1 of this post series, you learned how to use Apache Airflow, Genie, and Amazon EMR to manage big data workflows. This post guides you through deploying the AWS CloudFormation templates, configuring Genie, and running an example workflow authored in Apache Airflow.
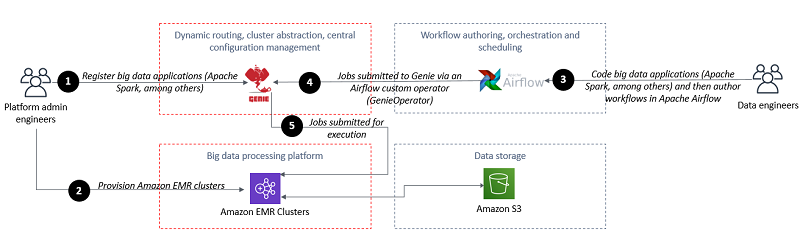
Orchestrate big data workflows with Apache Airflow, Genie, and Amazon EMR: Part 1
This post introduces an architecture that helps centralized platform teams maintain a big data platform to service thousands of concurrent ETL workflows, and simplifies the operational tasks required to accomplish that.
Install Python libraries on a running cluster with EMR Notebooks
This post discusses installing notebook-scoped libraries on a running cluster directly via an EMR Notebook. Before this feature, you had to rely on bootstrap actions or use custom AMI to install additional libraries that are not pre-packaged with the EMR AMI when you provision the cluster. This post also discusses how to use the pre-installed Python libraries available locally within EMR Notebooks to analyze and plot your results. This capability is useful in scenarios in which you don’t have access to a PyPI repository but need to analyze and visualize a dataset.

Secure your Amazon EMR cluster from unintentional network exposure with Block Public Access configuration
This post discusses a new account level feature called Block Public Access (BPA) configuration that helps administrators enforce a common public access rule across all of their EMR clusters in a region.