AWS Big Data Blog
Category: Amazon EMR

Building complex workflows with Amazon MWAA, AWS Step Functions, AWS Glue, and Amazon EMR
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that makes it easy to run open-source versions of Apache Airflow on AWS and build workflows to run your extract, transform, and load (ETL) jobs and data pipelines. You can use AWS Step Functions as a serverless function orchestrator to build scalable […]
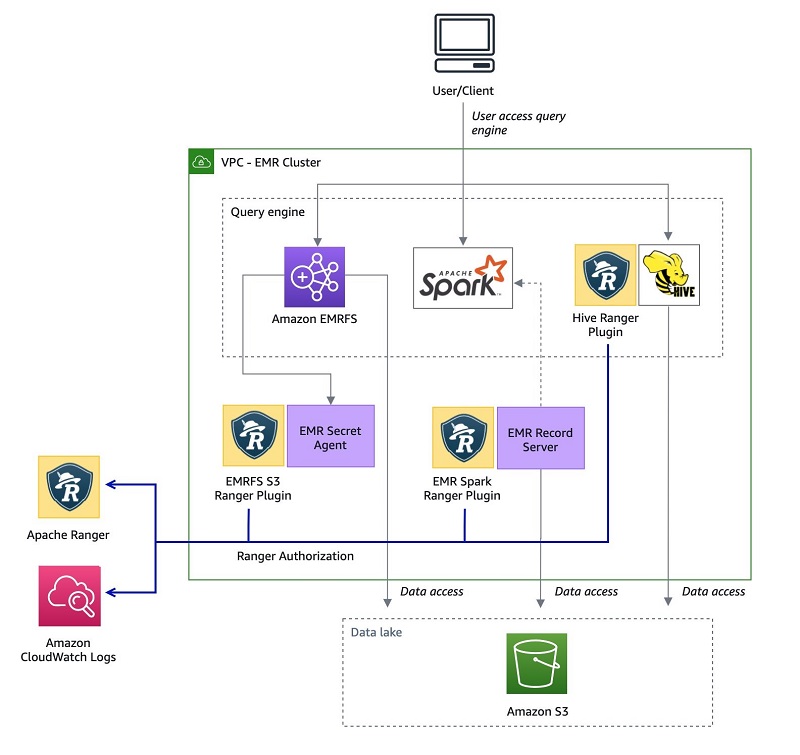
Introducing Amazon EMR integration with Apache Ranger
This post was last updated July 2022. Data security is an important pillar in data governance. It includes authentication, authorization , encryption and audit. Amazon EMR enables you to set up and run clusters of Amazon Elastic Compute Cloud (Amazon EC2) instances with open-source big data applications like Apache Spark, Apache Hive, Apache Flink, and Presto. You may […]
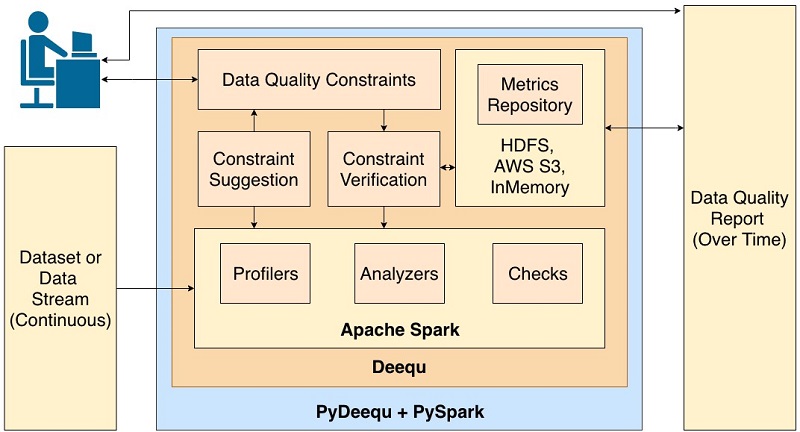
Testing data quality at scale with PyDeequ
June 2024: This post was reviewed and updated to add instructions for using PyDeequ with Amazon SageMaker Notebook, SageMaker Studio, EMR, and updated the examples against a new dataset. March 2023: You can now use AWS Glue Data Quality to measure and manage the quality of your data. AWS Glue Data Quality is built on Deequ […]
Dream11’s journey to building their Data Highway on AWS
This is a guest post co-authored by Pradip Thoke of Dream11. In their own words, “Dream11, the flagship brand of Dream Sports, is India’s biggest fantasy sports platform, with more than 100 million users. We have infused the latest technologies of analytics, machine learning, social networks, and media technologies to enhance our users’ experience. Dream11 […]

Amazon EMR Studio (Preview): A new notebook-first IDE experience with Amazon EMR
We’re happy to announce Amazon EMR Studio (Preview), an integrated development environment (IDE) that makes it easy for data scientists and data engineers to develop, visualize, and debug applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools like Spark UI and YARN Timeline Service to simplify debugging. […]

How the Allen Institute uses Amazon EMR and AWS Step Functions to process extremely wide transcriptomic datasets
This is a guest post by Gautham Acharya, Software Engineer III at the Allen Institute for Brain Science, in partnership with AWS Data Lab Solutions Architect Ranjit Rajan, and AWS Sr. Enterprise Account Executive Arif Khan. The human brain is one of the most complex structures in the universe. Billions of neurons and trillions of […]
Amazon EMR now provides up to 30% lower cost and up to 15% improved performance for Spark workloads on Graviton2-based instances
Amazon EMR now supports M6g, C6g and R6g instances with Amazon EMR versions 6.1.0, 5.31.0 and later. These instances are powered by AWS Graviton2 processors that are custom designed by AWS using 64-bit Arm Neoverse cores to deliver the best price performance for cloud workloads running in Amazon Elastic Compute Cloud (Amazon EC2). On Graviton2 […]

Data preprocessing for machine learning on Amazon EMR made easy with AWS Glue DataBrew
The machine learning (ML) lifecycle consists of several key phases: data collection, data preparation, feature engineering, model training, model evaluation, and model deployment. The data preparation and feature engineering phases ensure an ML model is given high-quality data that is relevant to the model’s purpose. Because most raw datasets require multiple cleaning steps (such as […]

Accessing and visualizing external tables in an Apache Hive metastore with Amazon Athena and Amazon QuickSight
Many organizations have an Apache Hive metastore that stores the schemas for their data lake. You can use Amazon Athena due to its serverless nature; Athena makes it easy for anyone with SQL skills to quickly analyze large-scale datasets. You may also want to reliably query the rich datasets in the lake, with their schemas […]

Orchestrating analytics jobs by running Amazon EMR Notebooks programmatically
Amazon EMR is a big data service offered by AWS to run Apache Spark and other open-source applications on AWS in a cost-effective manner. Amazon EMR Notebooks is a managed environment based on Jupyter Notebook that allows data scientists, analysts, and developers to prepare and visualize data, collaborate with peers, build applications, and perform interactive […]