AWS Big Data Blog
Category: Amazon Athena

Building AWS Data Lake visualizations with Amazon Athena and Tableau
July 2023: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze data in a data lake using standard SQL. One of the key elements of Athena is that you only pay for the queries you run. This is an attractive feature because there is no […]

How EMX reduced data pipeline costs by 85% with Amazon Athena
This is a guest blog post by Gary Bouton and Louis Ashner from EMX. In their own words, “ENGINE Media Exchange (EMX) is a leading marketing technology company, leveraging a patented, end-to-end tech stack purpose-built to meet the demands of today’s digital marketplace. The company creates both open- and closed-loop solutions designed to unify advertisers, […]

Detecting anomalous values by invoking the Amazon Athena machine learning inference function
Amazon Athena has released a new feature that allows you to easily invoke machine learning (ML) models for inference directly from your SQL queries. Inference is the stage in which a trained model is used to infer and predict the testing samples and comprises a similar forward pass as training to predict the values. Unlike […]
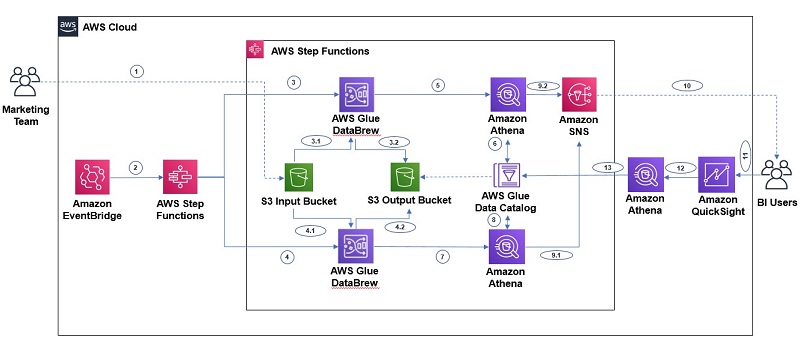
Orchestrating an AWS Glue DataBrew job and Amazon Athena query with AWS Step Functions
As the industry grows with more data volume, big data analytics is becoming a common requirement in data analytics and machine learning (ML) use cases. Also, as we start building complex data engineering or data analytics pipelines, we look for a simpler orchestration mechanism with graphical user interface-based ETL (extract, transform, load) tools. Recently, AWS […]

Accessing and visualizing data from multiple data sources with Amazon Athena and Amazon QuickSight
Amazon Athena now supports federated query, a feature that allows you to query data in sources other than Amazon Simple Storage Service (Amazon S3). You can use federated queries in Athena to query the data in place or build pipelines that extract data from multiple data sources and store them in Amazon S3. With Athena […]
Dream11’s journey to building their Data Highway on AWS
This is a guest post co-authored by Pradip Thoke of Dream11. In their own words, “Dream11, the flagship brand of Dream Sports, is India’s biggest fantasy sports platform, with more than 100 million users. We have infused the latest technologies of analytics, machine learning, social networks, and media technologies to enhance our users’ experience. Dream11 […]

Boosting your data lake insights using the Amazon Athena Query Federation SDK
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially […]

Keeping your data lake clean and compliant with Amazon Athena
June 2025: This post has been reviewed for accuracy and the following updates have been made: added new function to retrieve SQL query in the Lambda code; upgraded Python’s run time and version of sqlparse in the Lambda deployment package; added and removed actions in the Lambda policy; updated the CloudFormation template to reflect policy […]

Auditing, inspecting, and visualizing Amazon Athena usage and cost
Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. It’s a serverless platform with no need to set up or manage infrastructure. Athena scales automatically—running queries in parallel—so results are fast, even with large datasets and complex queries. You […]
Managing COVID-19 exposure with crowd tracing
This is a guest blog post by AWS partner Aspire Ventures As we enter winter, with fewer options to be outdoors, our personal choices can impact our risk of contracting the COVID-19 virus even more. The New England Journal of Medicine publication showed real-world examples of the effectiveness of masks and social distancing in mitigating […]