AWS Big Data Blog
Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS
Today, the most successful and fastest growing companies are generally data-driven organizations. Taking advantage of data is pivotal to answering many pressing business problems; however, this can prove to be overwhelming and difficult to manage due to data’s increasing diversity, scale, and complexity. One of the most popular technologies that businesses use to overcome these challenges and harness the power of their growing data is Apache Spark.
Apache Spark is an open-source, distributed data processing framework capable of performing analytics on large-scale datasets, enabling businesses to derive insights from all of their data whether it is structured, semi-structured, or unstructured in nature.
You can flexibly deploy Spark applications in multiple ways within your AWS environment, including on the Amazon managed Kubernetes offering Amazon Elastic Kubernetes Service (Amazon EKS). With the release of Spark 2.3, Kubernetes became a new resource scheduler (in addition to YARN, Mesos, and Standalone) to provision and manage Spark workloads. Increasingly, it has become the new standard resource manager for new Spark projects, as we can tell from the popularity of the open-source project. With Spark 3.1, the Spark on Kubernetes project is officially production-ready and Generally Available. More data architecture and patterns are available for businesses to accelerate data-driven transitions. However, for organizations accustomed to SQL-based data management systems and tools, adapting to the modern data practice with Apache Spark may slow down the pace of innovation.
In this post, we address this challenge by using the open-source data processing framework Arc, which subscribes to the SQL-first design principle. Arc abstracts from Apache Spark and container technologies, in order to foster simplicity whilst maximizing efficiency. Arc is used as a publicly available example to prove the ETL architecture. It can be replaced by your own choice of in-house build or other data framework that supports the declarative ETL build and deployment pattern.
Why do we need to build a codeless and declarative data
pipeline?
Data platforms often repeatedly perform extract, transform, and load (ETL) jobs to achieve similar outputs and objectives. This can range from simple data operations, such as standardizing a date column, to performing complex change data capture processes (CDC) to track historical changes of a record. Although the outcomes are highly similar, the productivity and cost can vary heavily if not implemented suitably and efficiently.
A codeless data processing design pattern enables data personas to build reusable and performant ETL pipelines, without having to delve into the complexities of writing verbose Spark code. Writing your ETL pipeline in native Spark may not scale very well for organizations not familiar with maintaining code, especially when business requirements change frequently. The SQL-first approach provides a declarative harness towards building idempotent data pipelines that can be easily scaled and embedded within your continuous integration and continuous delivery (CI/CD) process.
The Arc declarative data framework simplifies ETL implementation in Spark and enables a wider audience of users ranging from business analysts to developers, who already have existing skills in SQL. It further accelerates users’ ability to develop efficient ETL pipelines to deliver higher business value.
For this post, we demonstrate how simple it is to use Arc to facilitate CDC to track incremental data changes from a source system.
Why adopt SQL to build Spark workloads?
When writing Spark applications, developers often opt for an imperative or procedural approach that involves explicitly defining the computational steps and the order of implementation.
A declarative approach involves the author defining the desired target state without describing the control flow. This is determined by the underlying engine or framework, which in this post will be determined by the Spark SQL engine.
Let’s explore a common data use case of masking columns in a table and how we can write our transformation code in these two paradigms.
The following code shows the imperative method (PySpark):
The following code shows the declarative method (Spark SQL):
The imperative approach dictates how to construct a representation of the customer table with a masked phone number column; whereas the declarative approach defines just the “what” or the desired target state, leaving the “how” for the underlying engine to manage.
As a result, the declarative approach is much simpler and yields code that is easier to read. Furthermore, in this context, it takes advantage of SQL—a declarative language and more widely adopted and known tool, which enables you to easily build data pipelines and achieve your analytical objectives quicker.
If the underlying ETL technology changes, the SQL script remains the same as long as business rules remain unchanged. However, with an imperative approach processing data, the code will most likely require a rewrite and regression testing, such as when organizations upgrade Python from version 2 to 3.
Why deploy Spark on Amazon EKS?
Amazon EKS is a fully managed offering that enables you to run containerized applications without needing to install or manage your own Kubernetes control plane or worker nodes. When you deploy Apache Spark on Amazon EKS, applications can inherit the underlying advantages of Kubernetes, improving the overall flexibility, availability, scalability, and security:
- Optimized resource isolation – Amazon EKS supports Kubernetes namespaces, network policies, and pods priority to provide isolation between workloads. In multi-tenant environments, its optimized resource allocation feature enables different personas such as IT engineers, data scientists, and business analysts to focus their attention towards innovation and delivery. They don’t need to worry about resource segregation and security.
- Simpler Spark cluster management – Spark applications can interact with the Amazon EKS API to automatically configure and provision Spark clusters based on your Spark submit request. Amazon EKS spins up a number of pods or containers accordingly for your data processing needs. If you turn on the Dynamic Resource Allocation feature in your application, the Spark cluster on Amazon EKS dynamically evolves based on workload. This significantly simplifies the Spark cluster management.
- Scale Spark applications seamlessly and efficiently – Spark on Amazon EKS follows a pod-centric architecture pattern. This means an isolated cluster of pods on Amazon EKS is dedicated to a single Spark ETL job. You can expand or shrink a Spark cluster per job in a matter of seconds in some cases. To better manage spikes, for example when training a machine learning model over a long period of time, Amazon EKS offers the elastic control through the Cluster Autoscaler at node level and the Horizontal pod Autoscaler at the pod level. Additionally, scaling Spark on Amazon EKS with the AWS Fargate launch type offers you a serverless ETL option with the least operational effort.
- Improved resiliency and cloud support – Kubernetes was introduced in 2018 as a native Spark resource scheduler. As adoption grew, this project became Generally Available with Spark 3.1 (2021), alongside better cloud support. A major update in this exciting release is the Graceful Executor Decommissioning, which makes Apache Spark more robust to Amazon Elastic Compute Cloud (Amazon EC2) Spot Instance interruption. As of this writing, the feature is only available in Kubernetes and Standalone mode.
Spark on Amazon EKS can use all of these features provided by the fully managed Kubernetes service for more optimal resource allocation, simpler deployment, and improved operational excellence.
Solution overview
This post comes with a ready-to-use blueprint, which automatically provisions the necessary infrastructure and spins up two web interfaces in Amazon EKS to support interactive ETL build and orchestration. Additionally, it enforces the best practice in data DevOps and CI/CD deployment.
The following diagram illustrates the solution architecture.
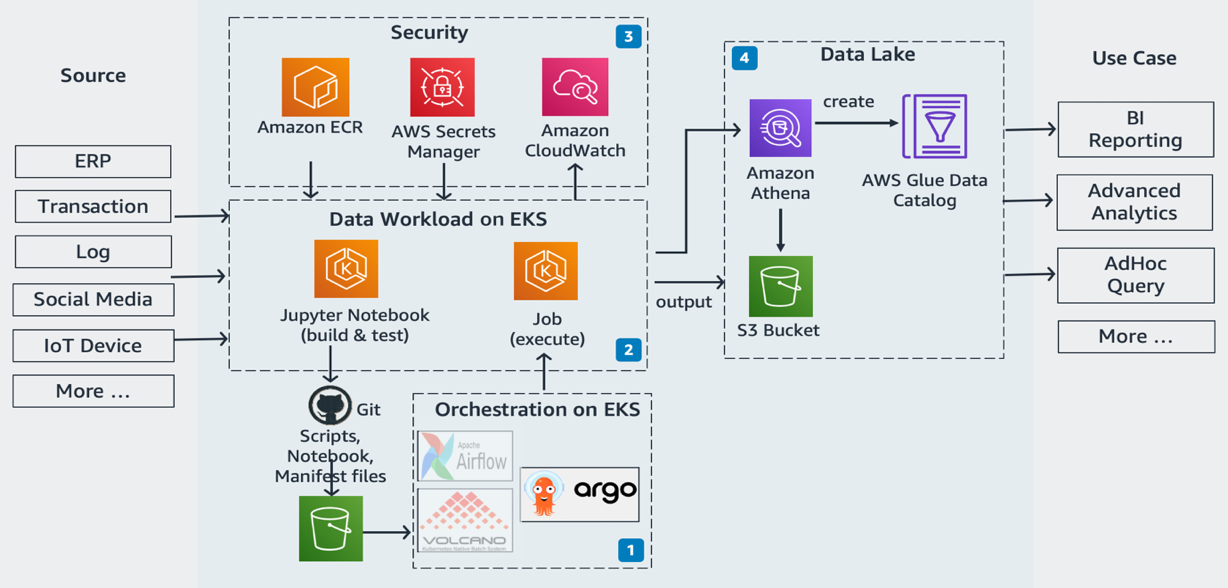
The architecture has four main components:
- Orchestration on Amazon EKS – The solution offers a highly pluggable workflow management layer. In this post, we use Argo Workflows to orchestrate ETL jobs in a declarative way. It’s consistent with the standard deployment method in Amazon EKS. Apache Airflow and other tools are also available to use.
- Data workload on Amazon EKS – This represents a workspace on the same Amazon EKS cluster, for you to build, test, and run ETL jobs interactively. It’s powered by Jupyter Notebooks with a custom kernel called Arc Jupyter. Its Git integration feature reinforces the best practice in CI/CD deployment operation. This means every notebook created on a Jupyter instance must check in to a Git repository for the standard source and version control. The Git repository should be your single source of truth for the ETL workload. When your Jupyter notebook files (job definition) and SQL scripts land to Git, followed by an Amazon Simple Storage Service (Amazon S3) upload, it runs your ETL automatically or based on a time schedule. The entire deployment process is seamless to prevent any unintentional human mistakes.
- Security – This layer secures Arc, Jupyter Docker images, and other sensitive information. The IAM roles for service accounts feature (IRSA) on Amazon EKS provides token authorization with fine-grained access control to other AWS services. In this solution, Amazon EKS integrates with Amazon Athena, AWS Glue, and S3 buckets securely, so you don’t need to maintain a long-lived AWS credential for your applications. We also use Amazon CloudWatch for collecting ETL application logs and monitoring Amazon EKS with the container insights
- Data lake – As an output of the solution, the data destination is an S3 bucket. You should be able to query the data directly in Athena, backed up by a Data Catalog in AWS Glue.
Prerequisites
To run the sample solution on a local machine, you should have the following prerequisites:
- Python 3.6 or later.
- The AWS Command Line Interface (AWS CLI) version 1. For Windows, use the MSI installer. For Linux, macOS, or Unix, use the bundled installer.
- The AWS CLI is configured to communicate with services in your deployment account. Otherwise, either set your profile by EXPORT AWS_PROFILE=<your_aws_profile> or run aws configure to set up your AWS account access.
If you don’t want to install anything on your computer, use AWS CloudShell, a browser-based shell that makes it easy to run scripts with the AWS CLI.
Download the project
Clone the sample code either to your computer or your AWS CloudShell console:
Deploy the infrastructure
The deployment process takes approximately 30 minutes to complete.
Launch the AWS CloudFormation template to deploy the solution. Follow the Customization instructions if you want to make a change or deploy to a different Region.
|
Region |
Launch Template |
| US East (N. Virginia) |  |
Deploy with the default settings (recommended). If you want to use your own username for the Jupyter login, update the parameter jhubuser. If performing ETL on your own data, update the parameter datalakebucket with your S3 bucket. The bucket must be in the same Region as the deployment Region.
Post-deployment
Run the script to install command tools:
Test the job in Jupyter
To test the job in Jupyter, complete the following steps:
- Log in with the details from the preceding script output. Or look it up from the Secrets Manager Console.
- For Server Options, select the default server size.
By following the best security practice, the notebook session times out if idle for 30 minutes. You may need to refresh your web browser and log in again.
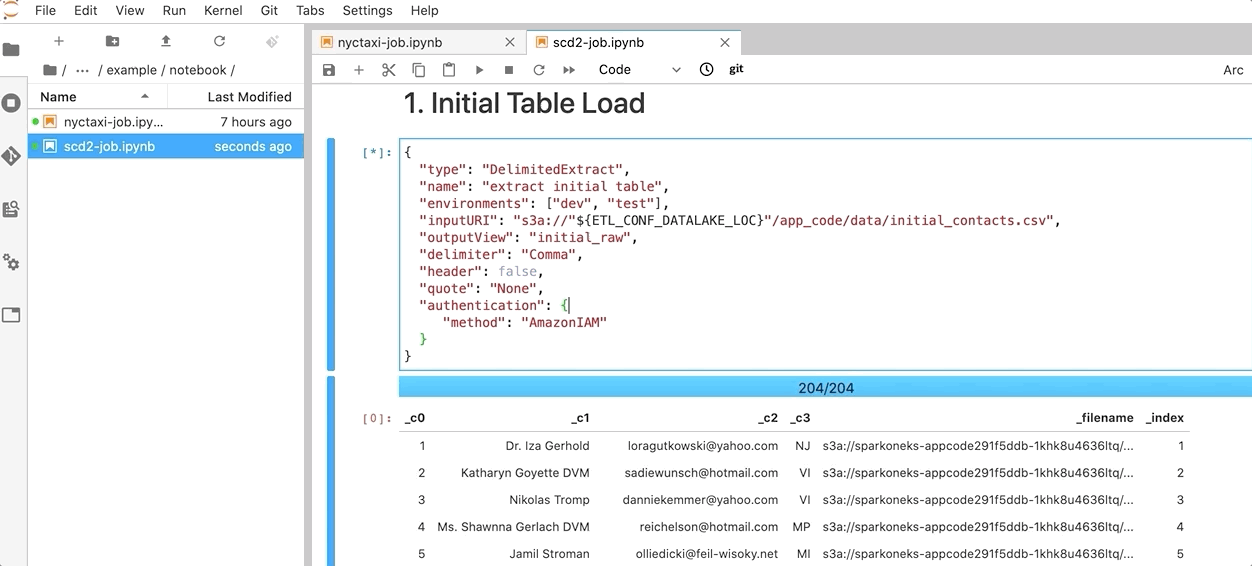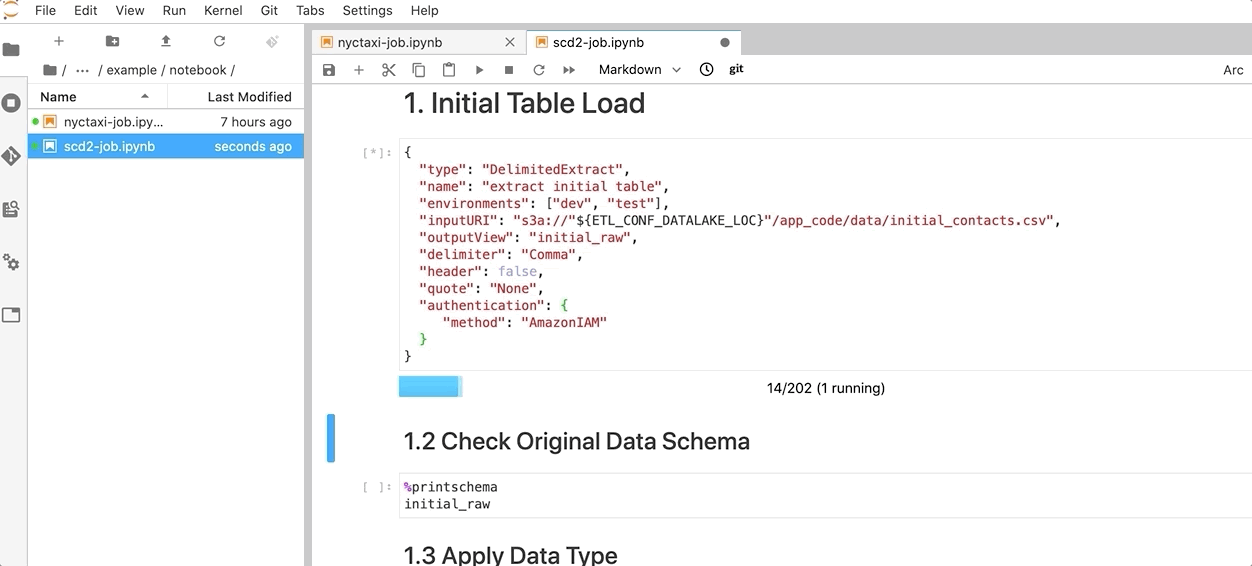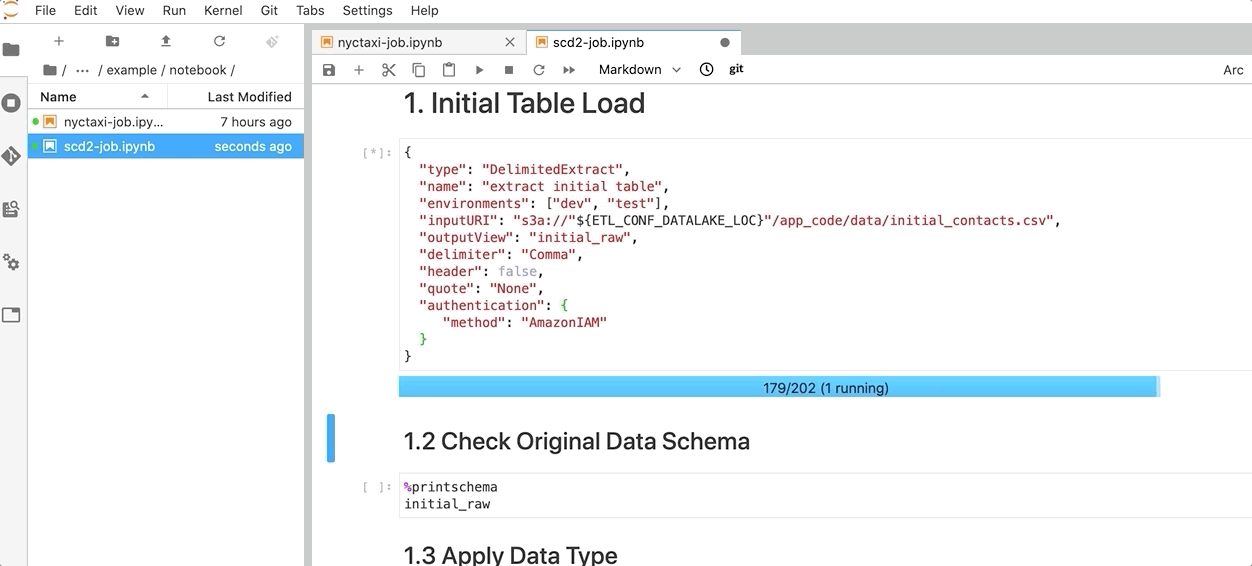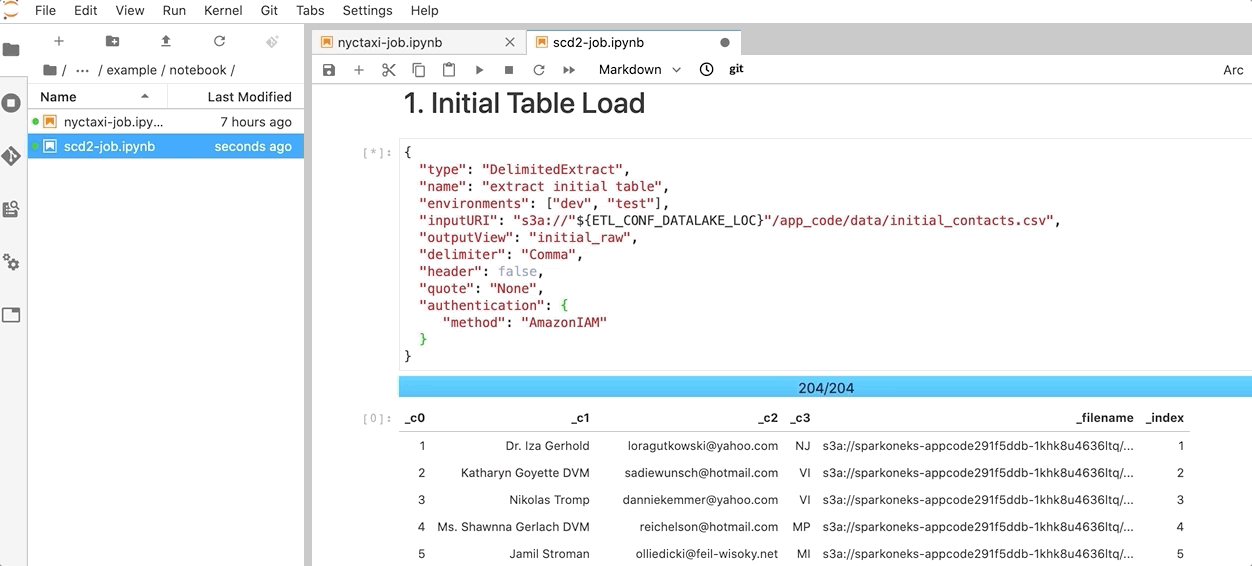
- Open a sample job
spark-on-eks/source/example/notebook/scd2-job.ipynbfrom your notebook instance. - Choose the refresh icon to see the file if needed.
- Run each block and observe the result. The job outputs a table to support the Slowly Changing Dimension Type 2 (SCD2) business need.
- To demonstrate the best practice in Data DevOps, the JupyterHub is configured to synchronize the latest code from this project GitHub repo. In practice, you must save all changes to a source repository in order to schedule your ETL job to run.
- Run the query on the Athena console to see if it’s a SCD type 2 table:
- (Optional) If it’s your first time running an Athena query, configure your result location to:
s3://sparkoneks-appcode<random_string>/


Submit the job via Argo
To submit the job via Argo, complete the following steps:
- Check your connection in CloudShell or your local computer.
- If you don’t have access to Amazon EKS or the Argo CLI isn’t installed, run the post-deployment script again:
- Log in to the Argo Website. It refreshes every 10 minutes (which is configurable).
- Run the script again to get a new login token if you experience a timeout
- Choose the Workflows option icon on the sidebar to view job status.
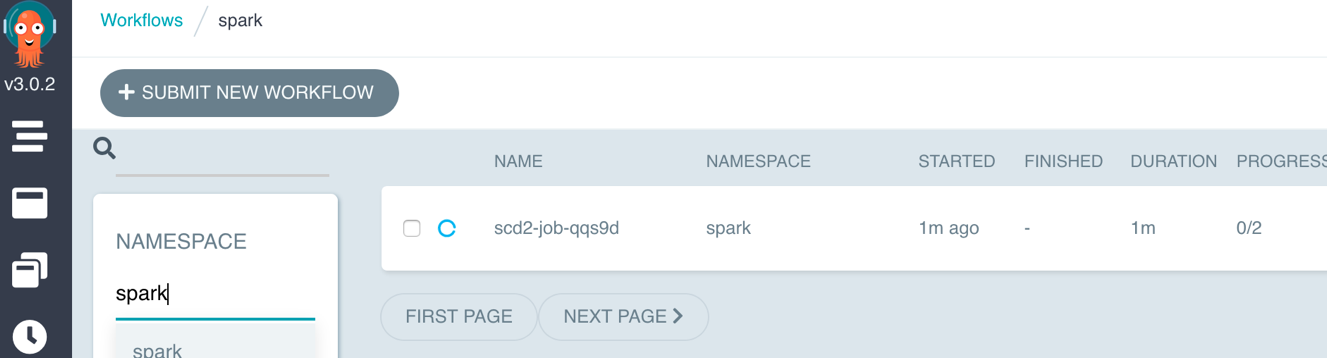
- To demonstrate the job dependency feature in Argo Workflows, we break the previous Jupyter notebook into three files, in our case, three ETL jobs.
- Submit the same SCD2 data pipeline with three jobs:
- Under the spark namespace, check the job progress and application logs on the Argo website.
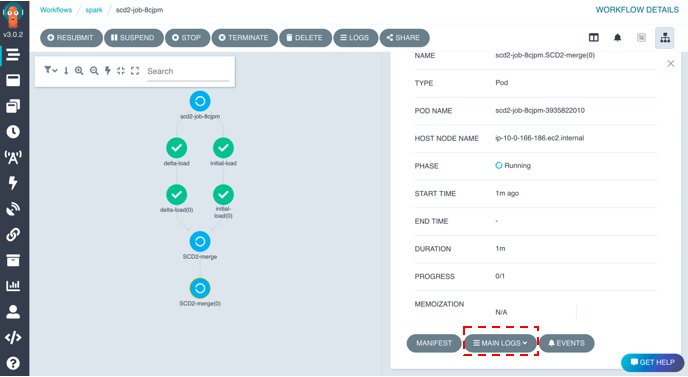
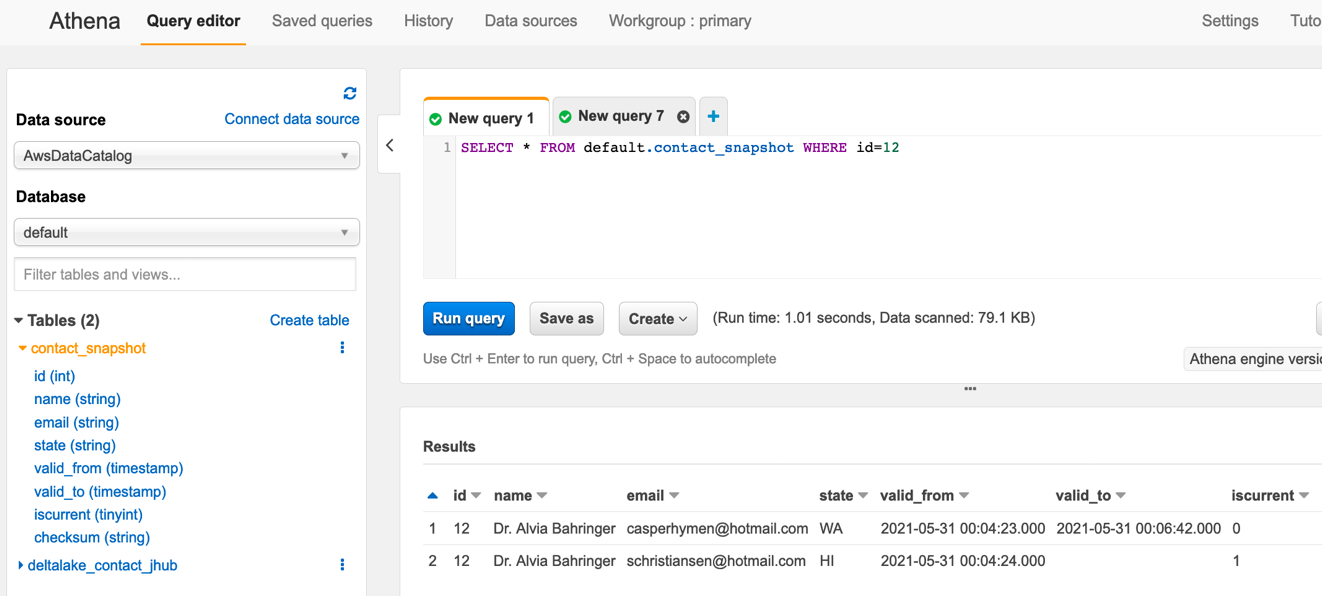
- Query the table in Athena to see if it has the same outcome as the test in Jupyter earlier:
The following screenshot shows the query results.
Submit a native Spark job
Previously, we ran the AWS CloudFormation-like ETL job defined in a Jupyter notebook powered by Arc. Now, let’s reuse the Arc Docker image that contains the latest Spark distribution, to submit a native PySpark job that processes around 50GB of data. The application code looks like this:

The job submitter is defined by spark-on-k8s-operator in a declarative manner. It follows the same declarative pattern as other applications deployment processes. As shown in the following code, we use the same command syntax kubectl apply.
- Submit the Spark job as a usual application on Amazon EKS:
- Check the job status:
- Test fault tolerance and resiliency.
You can perform self-recovery with a simpler retry mechanism. In Spark, we know the driver is a single point of failure. If a Spark driver dies, the entire application won’t survive. It often requires extra effort to set up a job rerun, in order to provide the fault tolerance capability. However, it’s much simpler in Amazon EKS with only a few lines of retry declaration. It works for both batch and streaming Spark applications.

- Simulate a Spot interruption scenario by manually deleting the EC2 instance running the driver:
- Delete the executor exec-1 when it’s running:
- Stop the job or rerun with different job configuration:
Clean up
To avoid incurring future charges, delete the resources generated if you don’t need the solution anymore.
Run the cleanup script with your CloudFormation stack name. The default name is SparkOnEKS:
On the AWS CloudFormation console, manually delete the remaining resources if needed.
Conclusion
To accelerate data innovation, improve time-to-insight and support business agility by advancing engineering productivity, this post introduces a declarative ETL option driven by an SQL-centric architecture. Managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with an open-source data processing framework or in-house built software to achieve the same productivity goal. Abstracting from Apache Spark and container technologies, you can build a modern data solution on AWS managed services simply and efficiently.
You can flexibly deploy Spark applications in multiple ways within your AWS environment. In this post, we demonstrated how to deploy an ETL pipeline on Amazon EKS. Another option is to leverage the optimized Spark runtime available in Amazon EMR. You can deploy the same solution via Amazon EMR on Amazon EKS. Switching to this deployment option is effortless and straightforward, and doesn’t need an application change or regression test. For more details, see the next blog Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS.
Additional reading
For more information about running Apache Spark on Amazon EKS, see the following:
- Best practices for running Spark on Amazon EKS
- New – Amazon EMR on Amazon Elastic Kubernetes Service (EKS)
About the Authors
 Melody Yang is a Senior Analytics Specialist Solution Architect at AWS with expertise in Big Data technologies. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
Melody Yang is a Senior Analytics Specialist Solution Architect at AWS with expertise in Big Data technologies. She is an experienced analytics leader working with AWS customers to provide best practice guidance and technical advice in order to assist their success in data transformation. Her areas of interests are open-source frameworks and automation, data engineering and DataOps.
 Avnish Jain is a Specialist Solution Architect in Analytics at AWS with experience designing and implementing scalable, modern data platforms on the cloud for large scale enterprises. He is passionate about helping customers build performant and robust data-driven solutions and realise their data & analytics potential.
Avnish Jain is a Specialist Solution Architect in Analytics at AWS with experience designing and implementing scalable, modern data platforms on the cloud for large scale enterprises. He is passionate about helping customers build performant and robust data-driven solutions and realise their data & analytics potential.
 Shiva Achari is a Senior Data Lab Architect at AWS. He helps AWS customers to design and build data and analytics prototypes via the AWS Data Lab engagement. He has over 14 years of experience working with enterprise customers and startups primarily in the Data and Big Data Analytics space.
Shiva Achari is a Senior Data Lab Architect at AWS. He helps AWS customers to design and build data and analytics prototypes via the AWS Data Lab engagement. He has over 14 years of experience working with enterprise customers and startups primarily in the Data and Big Data Analytics space.