AWS for SAP
SAP HANA sizing considerations for secondary instance with reduced memory footprint
Introduction
SAP systems that are critical to business continuity require a well designed and tested High Availability and Disaster Recovery (HA/DR) framework to maximise application availability during planned and unplanned outages. SAP HANA is an in-memory database that supports mission critical workloads and is a key component of an SAP system that needs to be safeguarded from failures. A primary or active HANA database can be replicated to a secondary instance using SAP HANA System Replication (HSR). SAP HSR continuously replicates data to ensure that in the event of a failure on the primary instance, changes persist in an alternate instance. In Amazon Web Services(AWS), the secondary HANA database instance can either exist within the same region (different Availability Zone) or in a separate region.
To achieve a near zero Recovery Time Objective (RTO), it is necessary for the primary and secondary HANA database instances to have a similar memory capacity. However, if a higher RTO is acceptable, it is possible to operate the secondary HANA database instance with a reduced memory footprint. This can result in considerable cost savings for compute, either by choosing a smaller instance size or leveraging excess memory on the secondary to operate other SAP HANA database workloads.
The reduced memory requirement in the secondary HANA node is achieved by configuring the secondary to not load HANA column data into main memory. A restart is required before promoting it to be primary, at which time it is assumed that the full memory requirement is available. The actual memory demand on secondary host is highly dependent on the HANA System Replication (HSR) configuration and production data change rate. Even by disabling HANA column table loading, the memory demands on the secondary host can go beyond 60% of the actual production HANA memory usage. If the secondary instance is not sized correctly, this can lead to out-of-memory crashes and reduced resilience.
This blog aims at providing a detailed guidance on how to size the secondary HANA database instance while operating with reduced memory footprint with examples for multiple deployment scenarios.
Architecture
There are two common architectures for deploying a secondary HANA database with a lean, or reduced memory footprint in AWS. In this blog we differentiate between them with the terms ‘smaller secondary’ and ‘shared secondary’. Smaller secondary is where the infrastructure is sized smaller than the primary, and then re-sized on takeover. This is sometimes referred to as Pilot Light DR as in the blog Rapidly recover mission-critical systems in a disaster. Shared secondary is where the unused memory is utilised by a non-production or sacrificial instance. SLES documentation refers to this as ‘Cost Optimized Scenario‘.
In both these scenarios, preload of column tables is disabled on the secondary HANA database. The specific configuration to implement this change is to set the HANA database parameter preload_column_tables to false. This configuration needs to be changed to ‘true’ before promoting this instance as primary. Given the manual intervention required and the time taken following a takeover to load the column tables before the HANA database is open for SQL connections, these scenarios are more relevant for a Disaster Recovery (DR) than a High Availability (HA) solution.
Smaller secondary
The following diagram illustrates the deployment of a smaller secondary in a separate Amazon Web Services(AWS) Availability Zone within the same region. However, such a deployment is also possible across multiple AWS regions. When replicating between AWS regions, the recommended replication mode is async for HSR due to increased latency.

Shared secondary
A common use case for a shared secondary scenario is to operate an active quality (QAS) instance along with the secondary HANA database instance on the same host, also called MCOS (Multiple Components One System). This setup requires additional storage to operate the additional instance(s). During a takeover, the instance with lower priority (QAS) can be shutdown to make the underlying host resources available for production workloads.

For both the scenarios, the secondary HANA database instance configuration is set to preload_column_tables = false. The default value of this parameter is ‘true’ and has to be explicitly changed on the secondary instance to operate with reduced memory. This change is made in HANA database configuration file (global.ini) located in the file path (/hana/shared/<SID>/global/hdb/custom/config).
HANA SR Operation modes
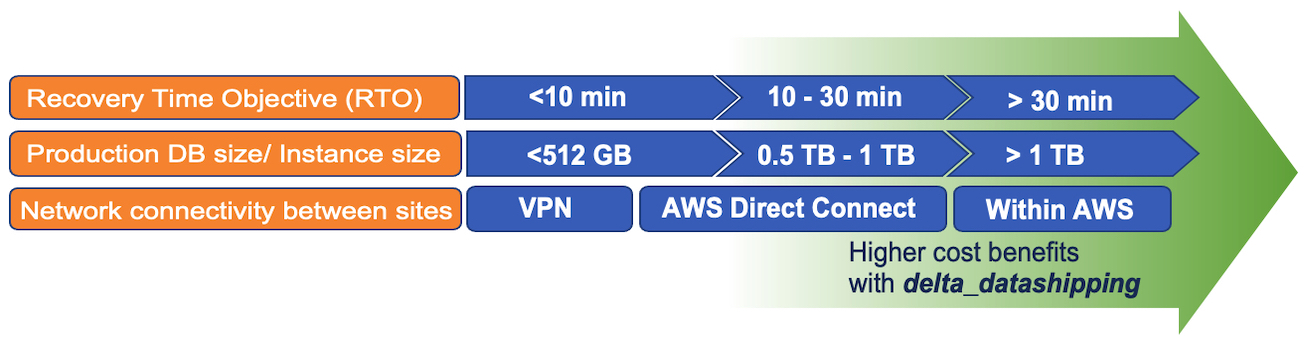
The two operation modes supported by HANA System Replication (HSR) to setup a secondary system are logreplay and delta_datashipping. A high-level comparison between logreplay and delta_datashipping operation modes is presented below.
| # | Criteria | Operation Mode | |
| logreplay | delta_datashipping | ||
| 1. | Operational behaviour | Logs are shipped and continuously applied on the secondary system. | Delta data is shipped from primary to secondary occasionally (default 10 min). Logs are only shipped, not applied until a takeover. |
| 2. | Recovery time | Shorter takeover window, as logs are applied continuously until the failure occurs | Relatively higher takeover time |
| 3. | Data transfer needs | Only logs are shipped, hence comparatively lower data transfer needs | Transfer of both delta data and log shipping adds to higher data transfers |
| 4. | Network bandwidth | Due to reduced data transfers, needs relatively lower bandwidth between sites | Requires higher bandwidth between sites |
| 5. | Memory footprint on DR instance | Significantly higher memory required as column store needs to be loaded for delta merge speed | Memory footprint is much smaller as column store is not loaded into the main memory when column preload is disabled. |
| 6. | Multi-tier replication | Supported | Supported |
| 7. | Multi-target replication | Supported | Not supported |
| 8. | Secondary time travel | Supported | Not supported |
It is worth noting that in a 3-Tier replication setup, a mix of operation modes is not supported. For example if the primary and secondary HANA database instances are configured to use logreplay for HSR, then delta_datashipping operation mode cannot be used between the secondary and tertiary systems and vice-versa.
SAP Guidance on disabling column preload
The actual memory usage on the secondary host is dependent on the HANA replication operation mode configuration and the preload setting for column tables. Hence it is important to understand the sizing requirements for different operation modes in a HANA System Replication setup. The below chart is an excerpt from SAP Note : 1999880 – FAQ: SAP HANA System Replication (SAP Support Portal login required)

As per the above guidance, even with preload = off, the minimum memory requirements for operation mode ‘logreplay’ also factors in the column store memory size of tables with modifications . As a rule of thumb, consider the size of column store tables with data modified in the previous 30 days from current date of evaluation.
SAP Note 1969700 – SQL Statement Collection for SAP HANA provides a collection of SQL scripts that can be used for analysing various administration and performance aspects of SAP HANA database. With minor changes to one of the scripts from this collection, titled ‘HANA_Tables_ColumnStore_Columns_LastTouchTime’, it is possible to provide a rough estimate for the minimum memory required to accommodate these tables. For exact steps of executing this script, refer to the ‘Additional information’ section at the end of this blog.
In the following sections, the examples provide details on how to evaluate sizing when deployed in a Shared secondary scenario. Although not shown, a similar sizing exercise is applicable to the Smaller secondary scenario, without the additional considerations of running a second HANA database instance (for example QAS) on the same host.
Option 1 – HSR with Operation Mode: logreplay
In the following example, the primary and secondary production HANA database instances are deployed on two 9TiB High Memory instances. The secondary instance host also hosts a Quality Assurance (QAS) HANA Database Instance. To be able to deploy these instances, the global_allocation_limit for all the three HANA database instances (PRD-Primary, PRD-Secondary, QAS) needs to be evaluated. Following section illustrates how to derive these values.
 In the subsequent sections, Global Allocation Limit is referred as ‘GAL’.
In the subsequent sections, Global Allocation Limit is referred as ‘GAL’.
- GAL for Primary instance
On the Primary instance, global_allocation_limit is not set in this example (default value=0 and unit is MB). A default value does not limit the amount of physical memory that can be used by the database. However, as per the SAP Note 1681092 – Multiple SAP HANA systems (SIDs) on the same underlying server(s), maximum allocation to HANA database by operating system follows the rule of 90% of the first 64 GB of available physical memory on the host plus 97% of remaining physical memory.
- GAL for Secondary instance
SAP’s guidance for minimum memory requirements for secondary HANA database instance with preload=off and logreplay operation mode is, ‘Row store size + Column store memory size of tables with modifications + 50 GB’. As an example, on the primary instance, the SQL script ‘HANA_Tables_ColumnStore_Columns_LastTouchTime’ was executed and the column tables with modifications for the previous 30 days is identified as 3077 GB. For detailed steps of executing this script, refer to the ‘Additional information’ section of this blog.

Similarly, using SQL script ‘HANA_Memory_Overview’ from SAP Note 1969700 – SQL Statement Collection for SAP HANA, the memory requirements for ‘Row store’ can be determined. An example value of 153 GB is considered for the following evaluation.
Note: This value provides the minimum sizing guidance only. It is recommended to allocate additional headroom of 10-20% of this value to accommodate any immediate spike in column store table modifications.
Similarly, global_allocation_limit (GAL) has to be set for the second HANA database instance (QAS) running on the DR site. According to the SAP Note 1681092 – Multiple SAP HANA systems (SIDs) on the same underlying server(s), the sum total of all HANA database allocation limits on a particular host should not exceed 90% of first 64 GB of available physical memory on the host plus 97% of remaining physical memory.
Applying this guidance to our example of 9 TiB(9896 GB) bare metal instance is as follows.
The total available memory for all HANA database instances is 9595 GB, while the total available physical memory on the bare metal instance is 9TiB (9896 GB). As the HANA DR instance memory sizing is derived at 3280 GB, the remaining size can be the maximum allocatable memory for QAS instance.
Option 2 – HSR with Operation Mode: delta_datashipping
This section provides an overview of HANA System Replication deployed with ‘delta_datashipping’ operation mode and the procedure to evaluate the memory sizing for each individual instance.

- GAL for Secondary instance
SAP’s guidance for minimum memory requirements for secondary HANA database instance with preload=off and delta_datashipping operation mode is as follows. Applying this guidance to our example scenario to derive GAL for DR is as follows
Applying this guidance to our example scenario to derive GAL for DR is as follows
The total available memory for all HANA database instances is 9595 GB, while the total available physical memory on the bare metal instance is 9TiB (9896 GB). In the previous step, secondary HANA database instance memory sizing is derived at 173 GB, the remaining size on the host can be the maximum allocatable memory for QAS instance.