AWS Architecture Blog
Category: Amazon CloudWatch

Genomics workflows, Part 2: simplify Snakemake launches
Genomics workflows are high-performance computing workloads. In Part 1 of this series, we demonstrated how life-science research teams can focus on scientific discovery without the associated heavy lifting. We used regenie for large genome-wide association studies. Our design pattern built on AWS Step Functions with AWS Batch and Amazon FSx for Lustre. In Part 2, […]

Email delta cost usage report in a multi-account organization using AWS Lambda
AWS Organizations gives customers the ability to consolidate their billing across accounts. This reduces billing complexity and centralizes cost reporting to a single account. These reports and cost information are available only to users with billing access to the primary AWS account. In many cases, there are members of senior leadership or finance decision makers […]
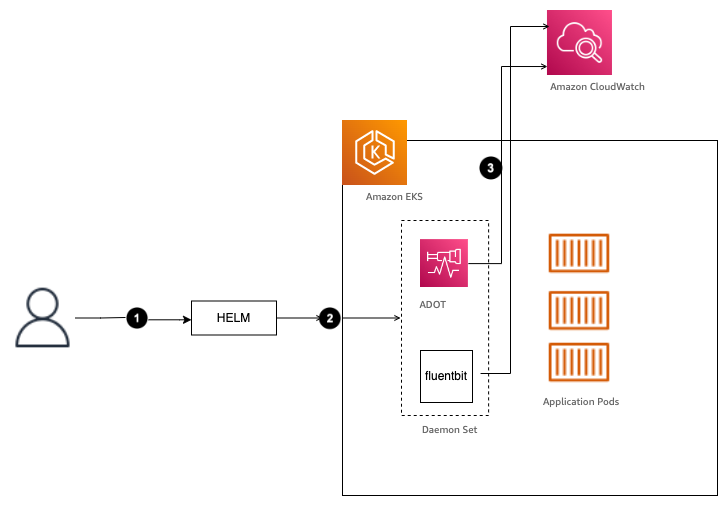
Amazon CloudWatch Insights for Amazon EKS on EC2 using AWS Distro for OpenTelemetry Helm charts
This blog provides a simplified three-step solution to collect metrics and logs from an Amazon Elastic Kubernetes Service (Amazon EKS) cluster on Amazon Elastic Compute Cloud (Amazon EC2) using the AWS Distro for OpenTelemetry (ADOT) Helm charts repository and send them to Amazon CloudWatch Logs and Amazon CloudWatch Container Insights. The ADOT Helm charts repository […]

Setup a high availability design for Oracle Data Guard (Fast-Start Failover) using Amazon Route 53
Many customers use Oracle Database deployed on Amazon Elastic Compute Cloud (Amazon EC2) to run their Oracle E-Business Suite applications. They rely on Oracle Data Guard for high availability databases, with a standby database running in a different availability zone. Oracle Data Guard can switch a standby database to the primary role in case a […]

A multi-dimensional approach helps you proactively prepare for failures, Part 3: Operations and process resiliency
In Part 1 and Part 2 of this series, we discussed how to build application layer and infrastructure layer resiliency. In Part 3, we explore how to develop resilient applications, and the need to test and break our operational processes and run books. Processes are needed to capture baseline metrics and boundary conditions. Detecting deviations […]

How Munich Re Automation Solutions Ltd built a digital insurance platform on AWS
Underwriting for life insurance can be quite manual and often time-intensive with lots of re-keying by advisers before underwriting decisions can be made and policies finally issued. In the digital age, people purchasing life insurance want self-service interactions with their prospective insurer. People want speed of transaction with time to cover reduced from days to […]
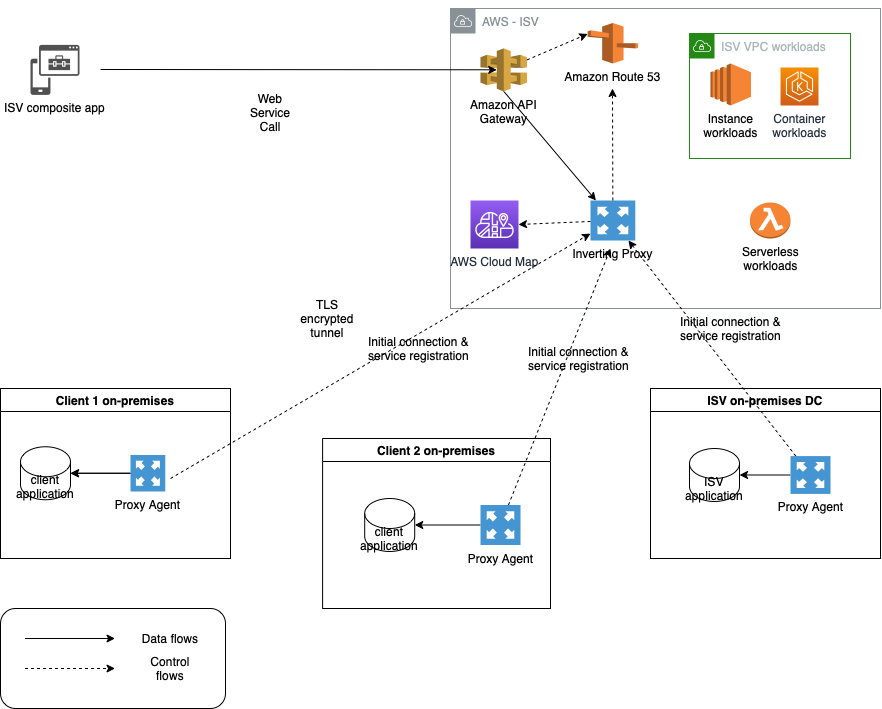
Implementing lightweight on-premises API connectivity using inverting traffic proxy
This post will explore the use of lightweight application inversion proxy as a solution for multi-point hybrid or multi-cloud, API-level connectivity for cases where AWS Direct Connect or VPN may not be practical. Then, we will present a sample solution and explain how it addresses typical challenges involved in this space. Defining the issue Large […]

Disaster recovery with AWS managed services, Part 2: Multi-Region/backup and restore
In part 1 of this series, we introduced a disaster recovery (DR) concept that uses managed services through a single AWS Region strategy. In part two, we introduce a multi-Region backup and restore approach. With this approach, you can deploy a DR solution in multiple Regions, but it will be associated with longer RPO/RTO. Using a […]

Detecting data drift using Amazon SageMaker
As companies continue to embrace the cloud and digital transformation, they use historical data in order to identify trends and insights. This data is foundational to power tools, such as data analytics and machine learning (ML), in order to achieve high quality results. This is a time where major disruptions are not only lasting longer, […]

Building a serverless cloud-native EDI solution with AWS
Electronic data interchange (EDI) is a technology that exchanges information between organizations in a structured digital form based on regulated message formats and standards. EDI has been used in healthcare for decades on the payer side for determination of coverage and benefits verification. There are different standards for exchanging electronic business documents, like American National […]