AWS Storage Blog
How to move and store your genomics sequencing data with AWS DataSync
Genomics data is expanding at a rate exceeding Moore’s law according to the National Human Genome Research Institute. As more sequencing data is produced and researchers move from genotyping to whole genome sequencing, the amount of data produced is outpacing on-premises capacity. Organizations need cloud solutions that help manage data movement, storage, and analysis. The volume of data being generated by genomics sequencing laboratories makes data movement to the cloud a principal challenge for genomics customers.
Researchers often have a contractually specified period of time, or turn-around time (TAT), requirement for products that are downstream of their genomics sequencing efforts. For this reason, data files produced by genomics sequencers need to be moved to the cloud as soon as they are written to network attached storage (NAS) on premises. These researchers cannot wait until a sequencing run is complete to initiate data movement for that run.
The volume of data generated can range from gigabytes a day for small sequencing projects to terabytes a day for population sequencing initiatives. And genomics data is generally considered the most private of personal data. From a regulatory perspective it is certainly considered Protected Health Information (PHI) or a special class of Personal Data. Due to the amount of data and the type of data, the solution to move data to the cloud has to be secure, scalable, and cost effective. It must also provide visibility into the success or failure of each data migration job while keeping any operational burden to a minimum.
Maximizing storage performance and minimizing storage cost are also key concerns. Customers must make their genomics data accessible to their research community and must move the data to archival storage to minimize cost and to meet regulatory requirements for patient data storage.
In this blog, we describe a robust, scalable, and secure solution to move data from on-premises genomics sequencers to object storage in Amazon Simple Storage Service (S3) using AWS DataSync and AWS Lambda. We demonstrate how to move genomics data files to Amazon S3 as they are written to network attached storage (NAS) on-premises using AWS DataSync and how to lifecycle genomics data to archival storage in Amazon S3 Glacier Deep Archive.
Prerequisites
AWS DataSync is an online data migration service that simplifies, automates, and accelerates moving data between on-premises storage systems and AWS storage services. DataSync can copy data between Network File System (NFS), Server Message Block (SMB) file servers, self-managed object storage, AWS Snowcone, Amazon S3 buckets, Amazon Elastic File System (EFS), Amazon FSx for Windows File Server file systems, and Amazon FSx for Lustre. AWS DataSync is a perfect fit for moving genomics data to AWS Storage services. It takes on the undifferentiated heavy lifting of encryption, transfer validation, error handling, and scaling data movement to the cloud.
AWS Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can trigger Lambda from over 200 AWS services and software as a service (SaaS) application, and only pay for what you use. AWS Lambda is used in this solution to run AWS DataSync tasks on a schedule or a custom run to migrate the raw genomics data files to Amazon S3.
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. Genomics data is persisted in files by sequencers while genomics analysis tools take files as inputs and write files as outputs. This makes Amazon S3 a natural fit for storing genomics data, data lake analytics, and managing the data lifecycle.
For this walkthrough, you need the following prerequisites:
- An AWS account
- This GitHub repository cloned to your local computer
- An Amazon Elastic Compute Cloud (Amazon EC2) key pair created, preferably named ‘GenomicsDatasyncTransfer’, in the same AWS account.
Launching the solution
This solution was built using the AWS Serverless Application Model (AWS SAM). To begin the launch of this solution, please follow the deployment instructions found in the README file of the GitHub repository. An AWS CloudFormation stack will be created in your account.
Solution architecture
The solution covers the following key elements. Each of these elements are explained in detail in the following subsections of this blog post:
- On-premises simulator: Used to simulate genomics sequencing data generation in an environment running on AWS.
- On-premises environment considerations: List the actions needed in order to integrate this solution with sequencing instruments running on premises.
- Scheduled AWS DataSync task executions: Describes how the solution automatically triggers data migration tasks on a given interval.
- On-demand AWS DataSync task executions: Describes how users can trigger custom, on-demand, data migration tasks.
Figure 1 shows the solution blueprint, broken down in detail following the diagram:

Figure 1: Solution architecture diagram
The key elements of the solution are carried out through the following workflow, as numbered in the preceding diagram:
- During the AWS CloudFormation stack creation, an AWS Lambda-backed custom resource is invoked. The function retrieves a subset of genomics data from the sample dataset, and loads this data to the genomics sample dataset in an Amazon S3 bucket.
- During the AWS CloudFormation stack creation, a second AWS Lambda-backed custom resource is invoked. This function waits for the AWS DataSync Agent AMI EC2 instance to be created. Then it uses the instance’s public IP address to retrieve the AWS DataSync Agent AMI activation code. Finally, the activation code is used by the AWS CloudFormation template to create and activate the AWS DataSync Agent.
- An Amazon EventBridge rule runs every minute, executing the sequencer simulator AWS Lambda function. This function simulates the work performed by a genomics sequencer. The function accesses the Amazon S3 bucket that contains the genomics sample dataset through an Amazon Virtual Private Cloud (Amazon VPC) endpoint. A subset of the data is copied over to an Amazon EFS file system.
- An Amazon EventBridge rule runs every 20 minutes (this value is configurable), and executes an AWS Lambda function that will start a new AWS DataSync task execution. The rule sets ‘include filters’ that specify the paths to look for files in. The paths are based on the timestamp that genomics sequencers put in the output folders. By default, the function will include folders generated in the past 72 hours (this value is configurable) so that runs executed during the previous three days are included. This is useful when data transfers occur around midnight or when transfers span over multiple days. This filter also reduces the number of files AWS DataSync needs to scan which decreases the read load on the local storage as well as the overall time the AWS DataSync agent takes to figure out which files need to be synced.
- AWS DataSync instructs the associated AWS DataSync agent to begin a transfer. The AWS DataSync task execution can be different, depending on whether you are running the solution as-is, or updating it to run against your on-premises local storage:
- On-premises simulator: The AWS DataSync agent that runs on Amazon EC2 begins to scan the Amazon EFS file system and determines which files need to be transferred to the destination. AWS DataSync only transfers files that have changed and that are part of the include filters set earlier. The protocol used to access the files is NFS v4.1.
- On-premises: The AWS DataSync agent that runs on a virtual machine (VM) begins to scan the on-premises local storage and determines which files need to be transferred to the destination. The data can be transferred using either NFS, SMB, or Amazon FSx for Windows File Server protocols.
- This solution supports custom data transfers using a separate AWS Lambda function that can trigger custom DataSync task executions, where specific folders that fall out the default 72-hour window can be added to the include filters of the AWS DataSync task. For more details, review the Custom AWS DataSync executions section of this post.
- During a DataSync task execution, logs and metrics are written to Amazon CloudWatch. Users can monitor the status and metrics of transfers by looking at a pre-built dashboard.
- A separate Amazon S3 bucket serves as the destination location for AWS DataSync transfers. The data generated by genomics sequencers on-premises is stored here. To cost-effectively handle all the transferred data, data that has been stored for more than 30 days is automatically moved to Amazon S3 Glacier Deep Archive. Finally, a separate Amazon S3 bucket is used to store the server access logs for both the genomics sample dataset bucket and the destination bucket.
On-premises simulator
This solution simulates an on-premises environment on AWS. It uses Amazon VPC, an AWS Lambda function to simulate genomics sequencers, Amazon EFS for local storage, and an AWS DataSync Agent AMI running on Amazon EC2.
The code base includes an AWS CloudFormation template to generate all the resources needed for the data migration. During its execution, data is loaded from a genomics sample dataset from the AWS Registry of Open Data, and an AWS DataSync Agent running on EC2 is automatically activated. The template also creates an AWS DataSync task with a source location pointing to Amazon EFS.
The template contains a list of pre-populated parameters, as illustrated in Figure 2:

Figure 2: Available pre-populated parameters
If you decide to use a different name for the EC2 key pair that’s listed in the prerequisites section, then you’ll need to update the DataSyncAgentKey parameter.
Another important parameter is SequencerOutputPaths; this is where you can define a comma-separated list of absolute paths that AWS DataSync will use to look for files. The on-premises simulator uses the following paths:
/sequencers/incoming/iseq,/sequencers/incoming/nextseq,/sequencers/incoming/miseq,/sequencers/incoming/nextseq2000
These paths mimic common file system structures used by Illumina sequencing instruments: iseq, nextseq, miseq, and nextseq2000.
This solution is designed to handle high volumes of data, so it supports other instruments like the NovaSeq 6000 sequencing system, also from Illumina, which can process up to six terabytes and 20 billion paired-end reads in less than 2 days.
On-premises environment considerations
To use the solution on premises, you need to perform a few configuration changes. First, capture the paths of your local storage device where your sequencing instruments write genomics data. Then, in the AWS CloudFormation template, update the value of the SequencerOutputPaths parameter with a comma-separated list containing those paths.
To run AWS DataSync migrations on premises, you will need to create and activate an AWS DataSync agent in your local environment. The AWS DataSync agent deployed as an Amazon EC2 instance provided by this solution is only recommended to move data between AWS accounts or from a self-managed, in-cloud file system. The on-premises agent reads from a self-managed storage location. To improve performance, the agent should deploy as close as possible to your storage device. AWS DataSync supports VMware ESXi, Linux Kernel-based Virtual Machine (KVM), and Microsoft Hyper-V hypervisors.
To connect to your local storage device, create a new AWS DataSync source location. Depending on the protocol, different information may be required, in most cases AWS DataSync will connect to local storage using NFS or SMB protocols. You can create a new location using the AWS DataSync console or the AWS Command Line Interface (AWS CLI).
To use the new DataSync locations, create a new AWS DataSync task using the AWS DataSync console or the AWS CLI, configuring the desired source and destination locations. The AWS DataSync task provided by this solution is configured to use all the available bandwidth for a transfer, to verify only the data transferred, and to transfer only the data that has changed. Task scheduling is handled using an Amazon EventBridge rule, which triggers task executions every 20 minutes. The default minimum interval you can set is one hour. Although the frequency of the rule is configurable, we recommend triggering task executions no more than every 15 minutes otherwise DataSync will start queueing up executions and won’t begin any new migration tasks until the previous executions finish. Finally, to see meaningful information in the provided Amazon CloudWatch dashboard, make sure you enable logging for all transferred objects and files.
Scheduled AWS DataSync task executions
After the AWS CloudFormation stack is created you are now ready to begin a transfer. To begin the data transfer, you need to go to the Amazon EventBridge console and enable the rules named SequencerSimulatorTaskTriggerEvent and DataSyncTaskTriggerEvent, as seen in Figure 3.

Figure 3: Amazon EventBridge rules
The SequencerSimulatorTaskTriggerEvent rule pulls data from the genomics sample dataset Amazon S3 bucket and loads it on to the EFS file system on the on-premises simulator. This is used to simulate a genomics sequencer loading data into local storage.
The DataSyncTaskTriggerEvent rule calls the StartDataSyncTask AWS Lambda function at a 10 minute interval. The function takes the ARN of the AWS DataSync task named EFSToS3DataSyncTask, which was created by the AWS CloudFormation template, along with the list of paths passed in the SequencerOutputPaths parameter. The function uses these paths to dynamically generate include filters by appending the current and previous dates to the end of those paths, as illustrated in Figure 4. This enables you to reduce the number of paths AWS DataSync needs to look at, effectively reducing the time AWS DataSync tasks take to execute.
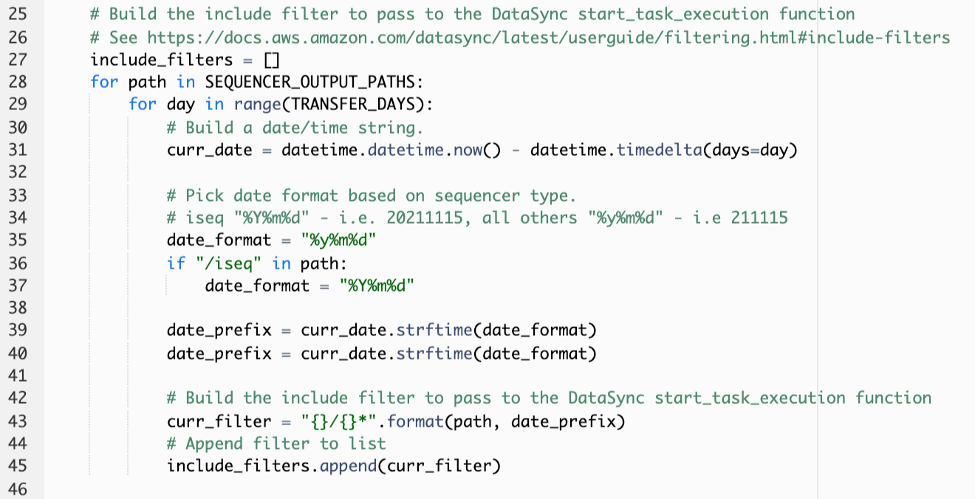
Figure 4: Custom include filters
By default, the function will create include filters covering 72 hours. If there is a need to cover runs that may span more than 72 hours, then the TRANSFER_DAYS variable needs to be updated. Please note that changing this default time period will result is longer execution times for AWS DataSync task executions.

Figure 5: Configurable TRANSFER_DAYS variable
Moving on to the AWS DataSync task itself, you’ll notice that at the beginning it has a status of unavailable, as seen in Figure 6. This is normal. Once you execute the task for the first time the status will change to available.

Figure 6: AWS DataSync task initial status
You should see new AWS DataSync task executions running 20 minutes after the Amazon EventBridge rules are enabled. You can view them on the AWS DataSync console by clicking on the task and looking under the history tab, as illustrated in Figure 7. In this tab you’ll see all the execution history and can view the status of each execution and the task itself.

Figure 7: AWS DataSync task executions
More information about the run is available to you by clicking on any Execution ID from the history tab. You can verify the input filters used for the data transfer by looking at the Data transfer configuration section, as seen in Figure 8.

Figure 8: AWS DataSync task execution transfer configuration
Lastly, you can monitor the status and results of the AWS DataSync task executions overall by looking at the Genomics-Data-Transfer-Monitoring dashboard. You can find that under dashboards in the Amazon CloudWatch console. See Figure 9.

Figure 9: Genomics Data Transfer CloudWatch dashboard
On-demand AWS DataSync task executions
There might be occasions where you need to trigger one-off or ad hoc uploads. This might be because a previous upload failed, a genomics sequencer ran for an extended period of time, something was misconfigured, or a network outage occurred. For these cases, one-time run can be triggered. You need to upload a text file containing a list of absolute paths to upload.
This text file needs to be uploaded to the /adhoc directory. Note the directory is at the root level of either the on-premises simulator Amazon EFS or your local on-premises storage device. The text file can have any name you want and can contain many paths, each path in a separate line. For an example, see Figure 10.

Figure 10: Sample text files with custom include filters for ad-hoc transfers
On the next scheduled AWS DataSync task execution, the text file is transferred to the S3 destination bucket which is configured to detect object create events on the adhoc prefix. Once the event is detected, the AdhocDataSyncTaskFunction AWS Lambda function is triggered. This function reads each line from the text file and triggers a custom DataSync task execution using these paths as input filters.
S3 Lifecycle for genomics data
Identify your Amazon S3 storage access patterns to optimally configure your S3 Lifecycle policy. You can use S3 Storage Class Analysis to analyze your storage access patterns. After storage class analysis observes the access patterns of a filtered set of data over a period of time, you can then use the analysis results to improve your lifecycle policies. For genomics data, the key metric is identifying the amount of data retrieved for an observation period of at least 30 days. Knowing the amount of data that was retrieved for a given observation period helps you decide the length of time to keep data in infrequent access before archiving.
Typically, customers archive the Binary Base Call (BCLs) files and Binary Alignment Map (BAM) files to Amazon S3 Glacier Flexible Retrieval or Amazon S3 Glacier Deep Archive within 30 to 90 days. Variant Call Files (VCFs) typically stay in Amazon S3 Standard-Infrequent Access for a year or more and FASTQ files are typically deleted since they can be regenerated. There are three different Amazon S3 Glacier storage classes, make sure to pick the right class based on your needs.
Finally, it’s a best practice to remove files from your local file system after they are transferred by DataSync to AWS. This can be accomplished in a post-processing step. You can learn more about cleaning up your local file system through data sync post processing in the AWS blog “Post-process your transferred data with file-level logging in AWS DataSync”.

Figure 11: Lifecycle of genomics dataCleaning up
To avoid incurring future charges, delete the solution by deleting the stack on the AWS CloudFormation console.
After testing the solution, the following Amazon S3 buckets will not be automatically deleted, so be sure to manually remove them to avoid charges. The S3 buckets we created are as follows:
- Logging Bucket: LoggingBucket
- Genomics sample dataset bucket: MockSynthDataBucket
- Destination Bucket: SyncDestinationBucket
Conclusion
Moving genomics data from on-premises genomics sequencers to AWS is not a trivial task when speed and security are paramount concerns. In this post, we demonstrated how you can securely transfer files written to local storage within minutes to Amazon S3. This is critical for genomics customers obligated to hit a TAT like a clinical report. Because DataSync scales data transfer volumes on demand, this solution scales to meet your data transfer needs, and you only pay for the data transferred. We encourage you to try this solution today.
To learn more about healthcare and life sciences at AWS visit thinkwithwp.com/health.
Thanks for reading this blog post. If you have any comments or questions, please leave them in the comments section.