AWS Storage Blog
AWS re:Invent recap: Best practices with Amazon S3

At AWS re:Invent 2020-2021, I was happy to present a session that first aired on December 3: Amazon S3 foundations: Best practices for Amazon S3. Amazon S3, including Amazon S3 Glacier, provides developers and IT teams with object storage that offers industry-leading scalability, durability, security, and performance. In the re:Invent session, we reviewed key features of Amazon S3 like storage classes, security, data protection, and analytics.
Amazon S3 offers industry-leading scalability, data availability, security, and performance. Scalability is one of the key benefits of S3 storage as it frees you up to focus on more important aspects of your business. It’s easy to get started and grow to petabytes of storage without worrying about capacity planning or hardware. This means customers of all sizes and industries can use it to store and protect any amount of data. Customers can optimally use their data across a range of use cases, such as data lakes, websites, backup and restore, archive, applications, IoT devices, and big data analytics.
In this post, I provide some of the key takeaways from my re:Invent session. If you missed it or haven’t gotten to check it out, remember that you can always view on-demand re:Invent sessions.
Optimizing costs with Amazon S3 storage classes
We’ve continued to add more storage classes to meet your access, performance, and cost needs. If your data is active and frequently accessed, S3 Standard is the best choice. AWS designed S3 Standard for 99.999999999% (11 9’s) of data durability, as your data is stored across three Availability Zones, which protects against a Single-AZ loss. You can also lifecycle your data to colder storage as it becomes dated or unneeded. If your data is less frequently accessed, and not deleted within a month, consider using S3 Standard-Infrequent Access (S3 Standard-IA) to save up to 40% on cost compared to S3 Standard. With S3 Standard-IA, there is a retrieval fee for accessing the data, and a minimum storage duration of 30 days. For data that you can easily recreate and that you access less frequently, you can use S3 One Zone-Infrequent Access (S3 One Zone-IA). S3 One Zone-IA stores data in a Single-AZ at 20% lower storage cost than S3 Standard-Infrequent Access. You also have the option to archive objects via lifecycle policies from any S3 storage classes into Amazon S3 Glacier storage classes or Amazon S3 Glacier Deep Archive. The S3 Glacier and S3 Glacier Deep Archive storage classes provide the lowest storage costs in the cloud, and are designed for long-term archival, with retrieval times from minutes to hours.
For those of you don’t want to think about access patterns or have data with unknown or changing access patterns, consider using S3 Intelligent-Tiering. We recently launched S3 Intelligent-Tiering support for two new access tiers: archive and deep archive. S3 Intelligent-Tiering can automatically move your data between four access tiers: frequent, infrequent, archive, and deep archive. Frequent access provides the same price and performance as S3 Standard, and Infrequent access the same as S3 Standard-IA. This means you can save up to 40% of storage cost as your data moves between the two tiers. Similarly, the archive tier provides the same price and performance as S3 Glacier, and the deep archive tier the same as S3 Glacier Deep Archive. There is no lifecycle fee for S3 Intelligent-Tiering, and no restore fee for accessing data from the archive tiers. However, there is a small, monthly monitoring fee for the automated tiering.
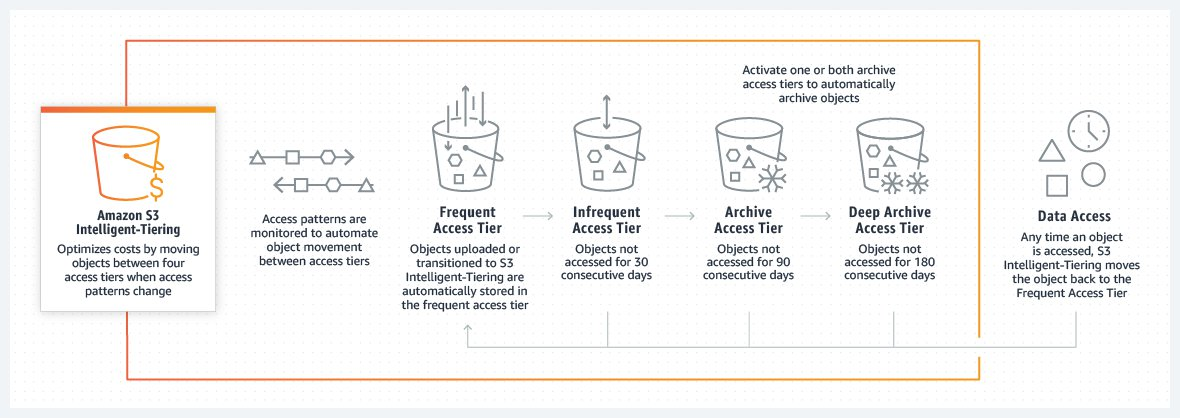
Another option to optimize costs is to analyze data access patterns with tools like S3 Storage Class Analysis and to use S3 Lifecycle rules to transition or expire objects. For example, you could use an S3 Lifecycle rule to move objects from a frequent access storage class like S3 Standard to S3 Glacier if you have not accessed the objects for 90 days. You can also move your objects to S3 Glacier Deep Archive if you have not accessed the objects in 180 days.
Data protection and security with Amazon S3
S3 Versioning is a feature to keep multiple variants of an object in the same bucket. We recommend you enable versioning on all S3 buckets, so you can easily recover from both unintended user actions and application failures. In a versioning-enabled bucket, if you delete an object without a version ID, S3 inserts a delete marker on the object, which becomes the current version of the object. So a GET on the object returns a 404 error, but if you wish to reverse the changes, you can.
Another data protection measure that we recommend to customers is Amazon S3 Replication. With S3 Replication, you can configure Amazon S3 to automatically replicate S3 objects across different AWS Regions by using Amazon S3 Cross-Region Replication (CRR) or between buckets in the same AWS Region by using Amazon S3 Same-Region Replication (SRR). Customers needing a predictable replication time backed by a Service Level Agreement (SLA) can use Replication Time Control (RTC) to replicate objects in less than 15 minutes. We recently launched four new features with S3 Replication:
- The flexibility of replicating to multiple destination buckets in the same, or different AWS Region.
- Support for delete marker replication.
- Support for two-way replication between two or more buckets.
- Replication metrics and notifications.

With Amazon S3, security is at the core of everything we do. We recommend you to enable S3 Block Public Access at an account level, so you can limit unintended public access to your data. S3 Block Public Access provides settings for access points, buckets, and accounts to help you manage public access to Amazon S3 resources.
We also recommend you to enable default encryption at a bucket level so that you encrypt all new objects when you store them in the bucket. You have the option to use server-side encryption with Amazon S3-managed keys (SSE-S3) or customer master keys (CMK) stored in AWS Key Management Service (AWS KMS).
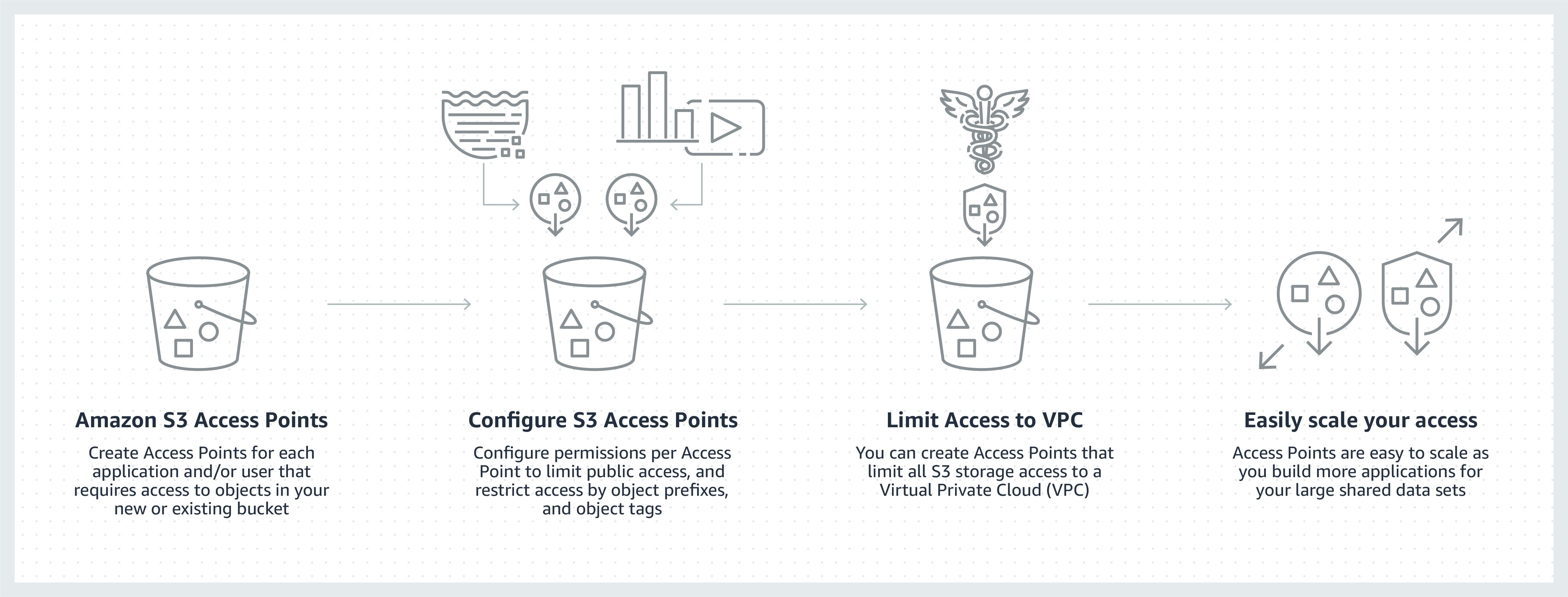
Another way to secure your data with access and bucket policies through a simplified way is through S3 Access Points. Access Points are unique hostnames that customers create to enforce distinct permissions and network controls for any request made through the Access Point. Customers with shared datasets including data lakes, media archives, and user-generated content can easily scale access for hundreds of applications by creating individualized access points with names and permissions customized for each application.
Storage analytics and insights
Amazon S3 Storage Lens is the first cloud storage analytics solution with support for AWS Organizations that gives you organization-wide visibility into object storage, with point-in-time metrics, trend lines, and actionable recommendations. All these things combined will help you discover anomalies, identify cost efficiencies, and apply data protection best practices across accounts. S3 Storage Lens provides you 29+ usage and activity metrics with an interactive dashboard on the S3 console. We recommend you try S3 Storage Lens to understand, analyze, and optimize your data on S3.

We also recommend you try Amazon CloudWatch percentile metrics to visualize your typical request patterns on Amazon S3 and spot and alarm on outliers.
Conclusion
I hope this post was a good recap of all the features on Amazon S3 that you can use to meet your performance, compliance, data sovereignty and business continuity requirements. Here are some key takeaways I would want you to leave my session with:
- Use default encryption at the highest abstract possible.
- Consider using S3 Intelligent-Tiering to optimize costs through smart storage while meeting your performance needs.
- Always enable versioning on buckets to recover from unintended user actions or application failures.
- Use S3 Replication in the same AWS Region or across AWS Regions to create Cross-Region redundancies and serve multi-Region applications.
Here are some helpful links to explore the topics covered in this post:
Thanks for reading this blog post about my re:Invent session on best practices for Amazon S3. If you have any comments or questions, please don’t hesitate to leave them in the comments section.