AWS Startups Blog
Tag: Technical Use Cases
Pillar on Optimizing Blockchain Data Processing with AWS
Pillar Project changed the base of their architecture entirely to facilitate a vision: an ability to ingest ever increasing amounts of data from various blockchain networks with high durability, low latency, fault-tolerance, transferability and ultimately store this data in a useful, unrestricted way. Here’s how they did it.

HyperTrack: Managed Service for Live Location Tracking at Scale
Suppose you are building location-aware applications to make the mobile workforce more productive and logistics networks more efficient. To do this, you would start by getting the live location and then show it to the customer on a map in real-time. To do that successfully, you also need to operate complex infrastructure to ingest, process, store, provision, and manage this data. Enter HyperTrack.
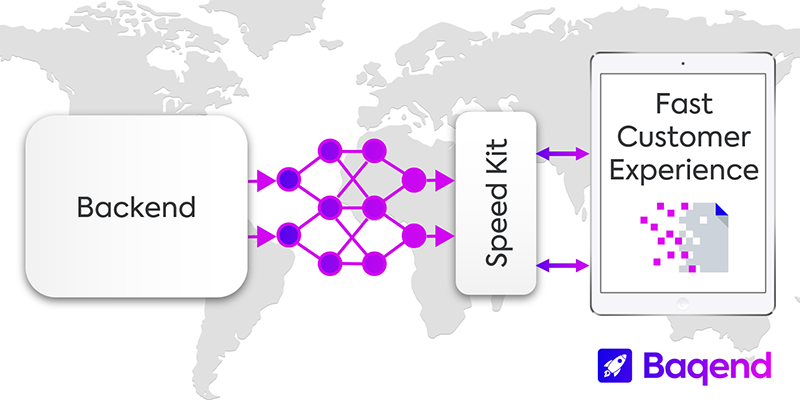
Caching the Uncacheable: How Speed Kit Accelerates E-Commerce Websites
German software startup Baqend has developed Speed Kit as an SaaS solution for accelerating e-commerce websites. Here’s how they did it.

AgTech: How House of Crops is Digitizing the Least Digital Industry
Berlin-based House of Crops is an agtech startup that’s digitalizing the world’s most traditional industry: agriculture. COO Maximilian Commandeur recently sat down to tell us more.

Transifex & Amazon Translate: Bringing Machine Translation to Enterprise Content Management
At Transifex, we’re constantly asking ourselves what building products can look like when localization becomes an integrated part of the standard developer stack and agile workflows. What technology do we need to enable companies to go global from day one?

How Renovo Uses Amazon OpenSearch to Manage Logs
AWS has enabled auto tech startup Renovo to keep up with logs generated by vehicles and support systems in a manner that does not require it to over-provision processing and focus on the problem space: operating a vehicle or fleet of vehicles. Director of Data Services Khalid Azam explains how.

How ALICE uses AWS Glue to Solve Complex Data Migration Challenges
ALICE, a platform for hotel staff to deliver exceptional hospitality to their guests, acquired a large competitor, GoConcierge with a global customer base of over 1k hotels. ALICE needed to migrate GoConcierge’s customers so they could benefit from the new platform. Here’s how they used AWS Glue to do it.

Meeting SLAs for Data Pipelines on Amazon EMR With Unravel
Among the most common complaints and concerns about optimizing big data clusters and applications is the amount of time it takes to root-cause issues like application failures and slowdowns. Here’s a detailed look at how big data startup Unravel helps.

Datavant Uses Batch to De-Identify Health Data
Datavant enables health companies to share sensitive health data securely. An important part of this process is de-identifying records so that they can be used in research or analytics contexts where identifying information is unneeded or required by law to be removed. Datavant supports both on-premise and cloud workflows to de-identify data. In this post, we share a simple approach to turn our native on-premise application into an AWS-hosted cloud service over the course of a single sprint cycle.

How Mapbox Created a Flexible Artifact Building System Using AWS CodeBuild
Last year, the Mapbox Platform team decided that in order to better serve developers at the company, we should combine all of our existing artifact-creation tools into a single-unified system. This system, which we named artifacts, provides an easy to use, extendable platform for creating any type of build artifact. Here’s how we did it.