AWS Startups Blog
Shipper’s Digital Transformation Journey to Build Next Generation 4PL Supply Chain

Guest post by Marvinus Kokoh Arif, CTO, Shipper, and Riza Saputra, Solutions Architect, AWS
Shipper is one of the fastest growing technology companies in Indonesia, providing end-to-end digital supply chain solutions for businesses of all sizes in a market where last mile fulfillment and delivery is estimated at US$80B. Via our proprietary software, we connect the country’s largest tech-enabled logistics network of third-party logistics providers (3PL), first-mile delivery agents, micro-fulfillment hubs (e.g. mom-and-pop shops), and over 222 warehouses across 35 cities in the country.
In this blog post, we would like to share our technology transformation journey and how we have grown and supported a couple hundred orders per day back in 2017 up to hundreds of thousands orders per day in recent years with the help of Amazon Web Services (AWS) managed services such as Amazon Elastic Kubernetes Service (Amazon EKS).
In early years, our architecture was as simple as providing enough compute power for our applications. The focus was really to prove out our business model and significant cost controls from an infrastructure perspective.
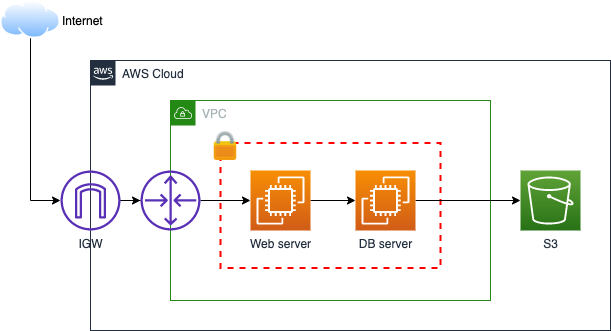
Early architecture
We began to realize that as our business grew, so did our problems, including extended server outage, slow application loading, and extensive manual infrastructure support from the team. Insufficient backup strategy also caused our systems to be vulnerable and resulted in long recovery issues when problems arose.
Environment Separation
In order to alleviate some of the problems above, we started to take advantage of AWS managed services such as Amazon Relational Database Service (Amazon RDS), which helped us tremendously for patching, scaling, as well as performance tuning by utilizing read replicas. Servers were segregated by capabilities, nightly backup, and environment separation to support more rapid development.
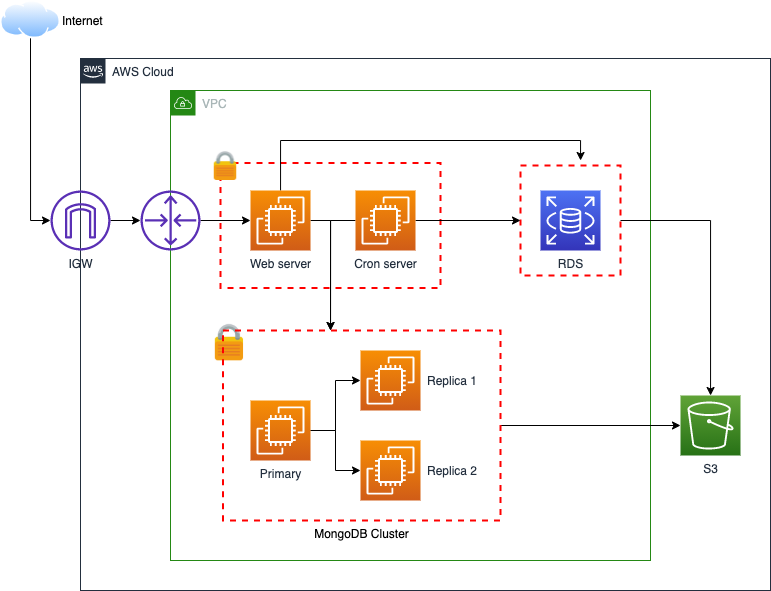
Environment separation
At first, things were looking a bit better, but soon enough, we realized there were several fundamental issues which we were still facing such as inability to scale out, untraceable issues, lack of logs monitoring and metrics, and the fact that all the applications were still monolithic.
Breaking into microservices
As our business continues to grow rapidly, we felt that rearchitecting was needed for long term investment, from a scalability, reliability, and cost optimization perspective. We identified some key areas to modify:
- Isolate service per domain
- Build microservices not nano services
- Keep API and event driven architecture in mind
- Invest in automation
- Implement stress test and performance monitoring tools
- Avoid single point of failure and scale horizontally
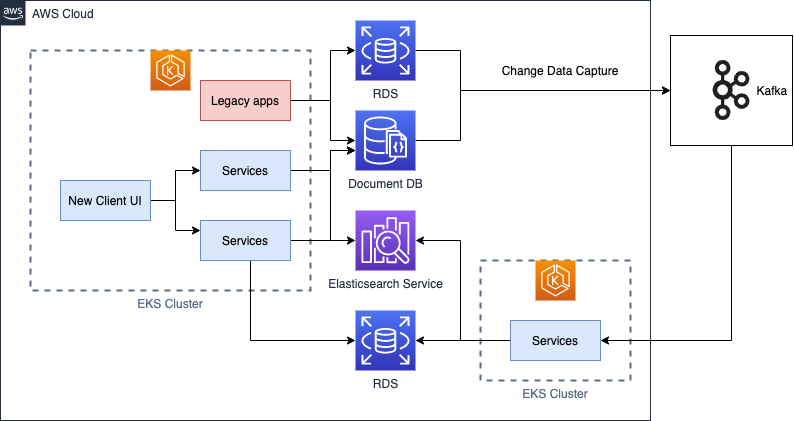
Microservices architecture
We began by breaking our monolithic service into several microservices based on their responsibilities. A common pattern is the strangler pattern, where we incrementally separated specific pieces of functionality from the legacy application into new microservices. During this process, our legacy applications were still running and fully functional while all new components were containerized and deployed with Amazon EKS.
Amazon EKS makes it easy to run Kubernetes and simplifies our architecture by reducing complexity (~60%) and cost saving (~30%). By using Amazon EKS, our applications were able to scale up horizontally and support self-healing deployment. Within the Kubernetes nodes, we ran many microservices segregated by their domain services. Going forward, containers become de facto of our development paradigm without worrying about complexity of the orchestration layer.
We also implemented a data replication via CDC (Change Data Capture) process where we synced data from existing repositories into new repositories: Amazon RDS and Amazon Opensearch Service. One of the biggest benefits we saw was a huge search performance improvement via Amazon Opensearch Service versus querying the database directly. We were able to offload traffic from our main database and at the same time, we were replicating data from legacy to new without system interruption.
For our warehouse solutions (not depicted in the diagram above), we chose Amazon Aurora as our database engine of choice since our warehouses increased exponentially. With Amazon Aurora, replication across multiple availability zones keeps our application transparently recovered when failures occur.
Conclusion
We’ve learned many lessons from this journey but feel like we’re just getting started. We’ve had to change our mindset and tailor the solution based on our business needs. By using AWS managed services, we saw lots of improvements especially from a scalability, availability, and cost optimization perspective. The more we grew, the more complex our architecture became, but it was well worth the investment. We hope our story with Amazon EKS, Amazon Opensearch Service, and Amazon Aurora can help inspire you in your own journey as well.