AWS Public Sector Blog
How to partition your geospatial data lake for analysis with Amazon Redshift

Data lakes are becoming increasingly common in many different workloads and geospatial is no exception. A data lake allows you to store all your structured and unstructured data at any scale, as-is, which can help you break down data silos between data and data types and incorporate multiple types of analytics features, like machine learning, to get the most insight from your data.
But while the concept and applications of data lakes have been around for a while, data lakes have seen mixed adoption in the geospatial world. Geospatial analysts were quick to make use of data lake architecture for raster datatypes, which consist of pixels, but were historically less likely to use the same for vector data, which is made of tabular data and points, lines, and polygons. This was mostly due to limited native file format support in object storage services, along with geospatial server and application object storage integration capabilities. However, in 2021, Amazon Web Services (AWS) announced geography and geohash support on Amazon Redshift, so geospatial analysts have the capability to quickly and efficiently query geohashed vector data in Amazon Simple Storage Service (Amazon S3). In this blog post, I walk through how to use geohashing with Amazon Redshift partitioning for quick and efficient geospatial data access, analysis, and transformation.
What is geohashing?
Geohashing is a popular geocode method for converting geographic coordinates of latitude and longitude into a string of digits and letters called a hash. Geohashing functions as a hierarchical spatial data structure that divides the world into a grid shape of quadrants or cells, onto which each quadrant is assigned an alphanumeric hash – the longer the hash, the more precise the location on the world map. The hash makes it simple to index and efficiently query geospatial data. Nearly any kind of data can be stored in a geohashed file structure, but it is more commonly used as the file structure for storing tiled datasets. Geohashing is used across many different applications, including geospatial analysis, social networking and interactive apps, consumer maps, proximity searches, and much more.
How geohashing works on AWS
Geospatial workloads are known for having some of the largest data sets, which makes them a natural fit for using a data lake architecture. Being able to store petabytes of data cheaply and efficiently is the biggest driver for data lake architectures. The foundation of a data lake’s architecture is low cost and highly scalable object storage like Amazon S3. Amazon Redshift, a fully managed, petabyte-scale data warehouse service in the cloud, can natively generate a geohash that can be used to lookup datasets located on Amazon S3 storage. Learn more about geohashing on AWS in this blog post, “Implementing geohashing at scale in serverless web applications.”
Additionally, Amazon Redshift can partition the data that is stored in an Amazon S3 data lake. When you upload your data to Amazon S3, you can use various folder structures to separate your data. Customers might use a timestamp as a folder name to organize their data. Structuring the data this way isn’t just beneficial from an organizing data standpoint; it also allows Amazon Redshift to make use of the folder structure while searching for data, so it only loads in the folders needed to fulfill a specific SQL query. For example, if I want to select data from sensorA where Day is Monday, Amazon Redshift can load the folder holding all the data that was sent on Monday instead of reading all the data that is stored in Amazon S3. Geospatial analysts can use this concept for geohashing, in which the folder structure can be the geohash of the area of interest that the analyst wants to query.
Let’s walk through how to set this up in Amazon Redshift and Amazon S3.
Solution overview: Partitioning vector data by geohash in Amazon S3 with Amazon Redshift
In this blog post, we walk through how to:
- Connect to your Amazon Redshift cluster using the query editor
- Load data into your Amazon Redshift cluster from Amazon S3
- Unload data from Amazon Redshift to Amazon S3 partitioned by geohash
- Leverage Amazon Redshift Spectrum and AWS Glue Data Catalog to create an external schema and table
- Query your partitioned dataset on Amazon S3 directly from Amazon Redshift
Prerequisites
Prerequisites required to complete this walk through:
- An AWS Account.
- A running Amazon Redshift cluster. Check out these steps for launching an Amazon Redshift cluster.
- An AWS Identify and Access Management (IAM) role with appropriate permissions associated with your cluster.
- An Amazon S3 bucket to start your geospatial data lake. Check out these steps for creating an Amazon S3 bucket.
Procedure
Amazon Redshift allows you to query the Amazon Redshift cluster right from the console. The following instructions assume that you have permission to access Amazon Redshift query editor.
1. From your cluster on the Amazon Redshift console, choose Query data and then choose Query in query editor V2.

Figure 1. In the Amazon Redshift console, choose Query data and then choose Query in query editor V2 (Step 1).
For our walkthrough, we use the Global Database of Events, Language, and Tone (GDELT), available on the AWS Open Data Registry. This dataset contains news events from around the world and is a great example for highlighting the efficiency of a geohash query. In the following steps, we import the data from Amazon S3 and then use ST_SetSRID and ST_MakePoint to insert the data into a new table with the geometry data type.
2. Run the following commands to create the tables, load the data, and format the data appropriately. Be sure to replace the <INSERT_IAM_ROLE_ARN> placeholder with the IAM role Amazon Resource Name (ARN) that you previously associated with your cluster:
Now we use the ST_GeoHash function to create our geohashes. This step is a bit unique as we also leverage the UNLOAD command with a PARTITION BY clause to effectively export our data in a partitioned format to Amazon S3.
3. Run the following command to export your data in a format that is partitioned by geohash. Be sure to replace the <INSERT_IAM_ROLE_ARN> and <INSERT_YOUR_S3_BUCKET> placeholders with the IAM role ARN and Amazon S3 bucket name that you previously created:
This command will take a few minutes to run as it unloads the data.
4. Now we’re ready to leverage Amazon Redshift Spectrum to extend our geospatial data lake into Amazon S3. Run the below command to create an external schema and database for your AWS Glue Data Catalog.
5. Create an external table and reference the GDELT input that is partitioned by geohash in Amazon S3 using the following command:
6. Add one of the geohash partitions to test with. In the following code, we partition for geohashes beginning with 204, which specifies an area near New Zealand.
7. Check to make sure the partitioning is working as expected using the following command. If everything is working as expected, you will see a few results returned. Because we use the 204 geohash, we expect to see only results related to this New Zealand region.
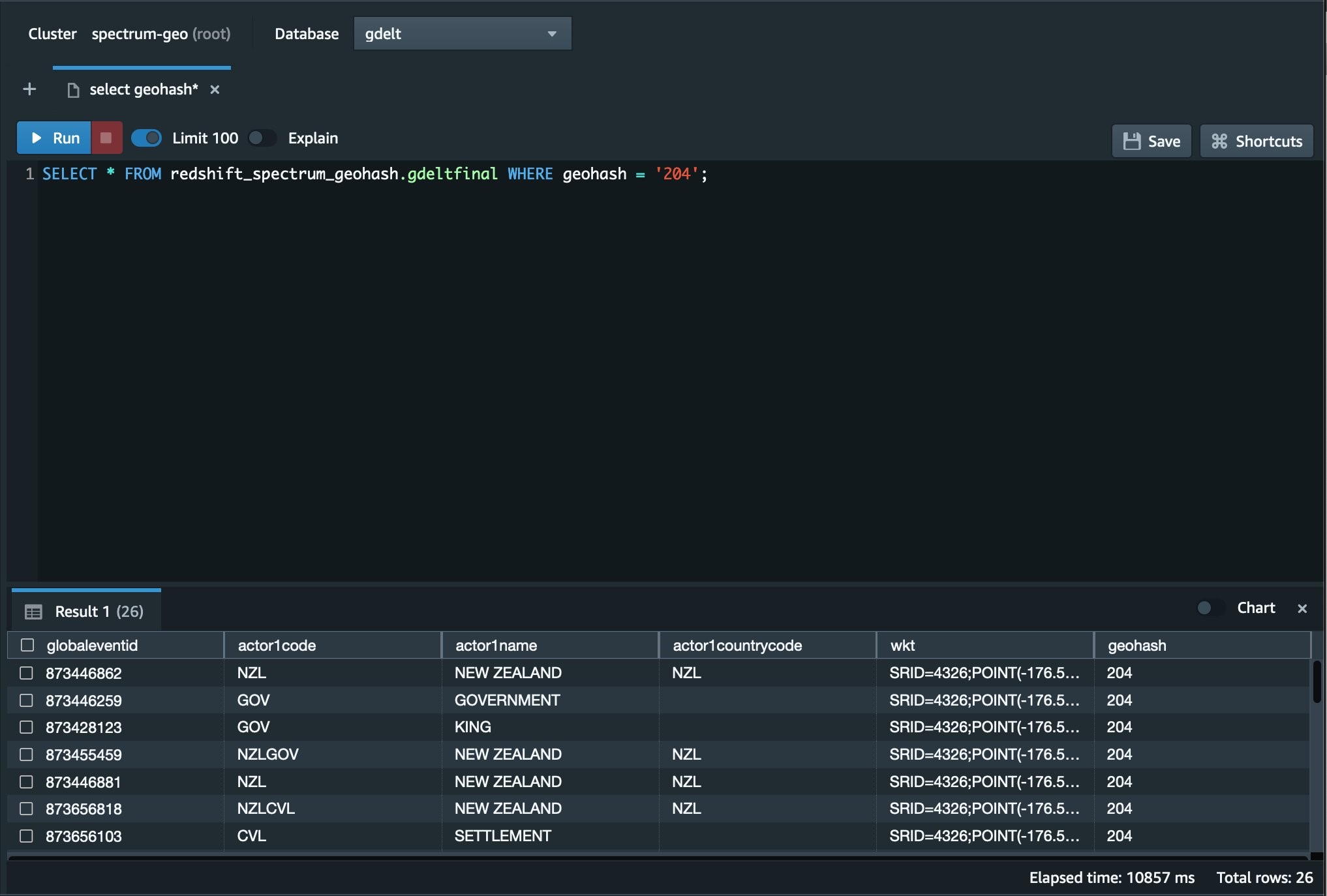
Figure 2. This Image shows the Redshift Query Editor V2 with our sample query and results.
We can see now from the Redshift Query Editor V2 in the AWS Console that the query returned only the results from New Zealand. If we reversed the geohash value 204, it would essentially be a latitude and longitude value for a grid somewhere between Te One, Chatham Islands and New Zealand. We can also see that only the data needed to return the results was pulled from Amazon S3, providing optimal performance for your newly created geospatial data lake.
Conclusion
In this blog, we covered the basics of geohashing along with support for geohashing in Amazon Redshift, and we presented a procedure walkthrough for how to partition and query vector data by geohashing Amazon Redshift. Using Amazon Redshift for geohashing allows you to use a hybrid approach in storing your data. You can combine geohashed data in Amazon S3 along with data stored locally on the Amazon Redshift cluster. You can also natively import shape files from Amazon S3 into Amazon Redshift. Amazon Redshift can then simply combine all this data through standard SQL joins and present it to the user as if it was all sitting together inside the database.
This capability can make queries faster to complete by reducing the amount of data that must be read, and can also decrease the cost of the query because less data is traversing the network. Lastly, it reduces the overall cost of storage by allowing the data to be stored in a data lake on Amazon S3 instead of needing to always be loaded in the database.
Read more about AWS for geospatial:
- Analyze terabyte-scale geospatial datasets with Dask and Jupyter on AWS
- How to deliver performant GIS desktop applications with Amazon AppStream 2.0
- How Natural Resources Canada migrated petabytes of geospatial data to the cloud
- Managing the world’s natural resources with earth observation
- Bringing world-class satellite imagery to smallholder farmers with open data
- OpenFold, OpenAlex catalog of scholarly publications, and Capella Space satellite data: The latest open data on AWS
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.