AWS Public Sector Blog
The Goldilocks zone for disaster recovery, business continuity planning, and disaster preparedness

Around the world, citizens rely on their governments for a myriad of essential public services—especially during emergencies. However, interruptions to IT systems can be dire emergencies too, since they can have a far-reaching impact on organizations and the people who rely on them. As extreme weather events become more common, public sector organizations need to design their IT solutions to be resilient and have a plan for unexpected events. Disaster recovery (DR)—the process of providing fast, reliable recovery of IT systems to minimize downtime and data loss—is a crucial investment for public sector organizations, along with business continuity planning (BCP) and disaster preparedness.
Why legacy disaster recovery strategies limit the benefits of using the cloud
Many public sector organizations have been making meaningful progress on modernizing their approaches to IT, including adopting the cloud. However, out-of-date DR and BCP policies prevent organizations from improving in these critical areas. Lifting and shifting old DR strategies into the cloud can diminish the potential benefits of using the cloud to improve operational resilience. For example, organizations that have only used on-premises hosting often ask their new cloud provider how far apart cloud data centers are located from each other, for DR purposes. The emphasis on specific distances between data center sites comes from the legacy approach to DR, in which the greater the distance between an organization’s data centers, the less chance that a single adverse event will impact IT operations in all of the data centers at the same time.
This assumption has been the bedrock of legacy DR approaches for the last few decades. This is why Amazon Web Services (AWS) provides its customers with DR options that include the ability to deploy workloads in a multi-Region, active-active architecture where customers can achieve recovery point objectives (RPOs) of near zero and very low recovery time objectives (RTOs). For example, many AWS customers in Canada use a second AWS Region in the US or other locations for DR purposes. However, there are some organizations that would like to keep their data within the borders of Canada, and these tend to be the organizations that ask for specific distance requirements between data centers for DR purposes. Organizations with such requirements have a range of options to achieve their RPOs and RTOs with AWS using the AWS Region in Canada that is backed by three Availability Zones (i.e. clusters of data centers).
Distance requirements for disaster recovery don’t help you achieve your RPOs and RTOs
Governments and organizations can’t achieve aggressive RPOs and RTOs simply by building data centers further apart. This line of thinking doesn’t account for a key reality: the greater the distance between data centers, the greater the network latency. At some point, the limitations imposed by the speed of light make data replication with relational databases or running distributed systems very challenging. Unfortunately, no amount of innovation increases the speed of light. This could mean that the very distance requirements that are supposed to help support DR objectives actually introduce latency that make RTOs and RPOs more challenging or even impossible to meet. Latency, down time, and data loss are literally built into the legacy approach.
Is there a point where more distance between data centers has diminishing risk mitigation returns? After building and operating 26 AWS Regions (clusters of Availability Zones) and 84 Availability Zones (clusters of data centers) around the world since 2006, we think so.
The Goldilocks zone for disaster recovery planning
The following graphic (Figure 1) provides estimates of how much latency would be observed as data centers move further apart. Our experience shows us that for high availability applications, there is a Goldilocks zone for infrastructure planning: a distance that’s not too close, and not too far, but just right. The Goldilocks zone is the distance between Availability Zones or data centers that can support aggressive RPOs and RTOs while keeping latency low enough for high availability applications.
When you look at the risk that natural disasters pose, clearly the further away the better—but after only tens of miles, there are diminishing returns. Beyond tens of miles, the types of disasters mitigated would likely be extinction-level events, like the meteor that killed the dinosaurs. This isn’t an exact range and what qualifies as too close varies on geographic region; things like seismic activity, hundred-year flood plains, and the probability of large hurricanes and typhoons, all influence how we think about too close. But we want miles of separation.
And what about too far? Here we look at the latency between all the Availability Zones in a Region and target a maximum latency round trip of about one millisecond. Whether you are setting up replication with a relational database or running a distributed system like Amazon Simple Storage Service (Amazon S3) or Amazon DynamoDB, we’ve found that maintaining the network conditions to support high availability applications gets fairly challenging when latency goes beyond one millisecond.
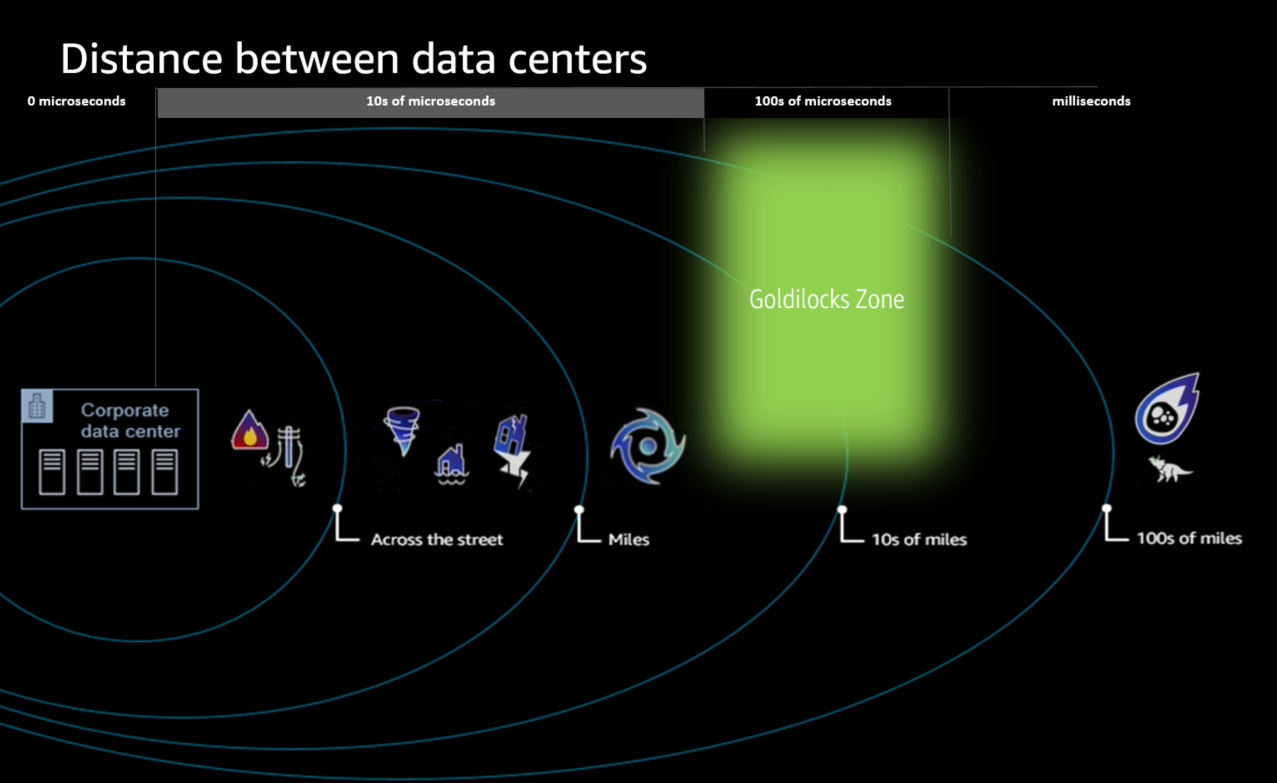
Figure 1. The Goldilocks zone in disaster recovery is the right amount of distance between data centers that keeps latency below one millisecond while protecting organizations’ data from natural disasters in a specific region; the Goldilocks zone is typically in the tens of miles range between data centers. Beyond tens of miles of distance between data centers—in the hundreds of miles range—the types of disasters mitigated would be extinction level events.
In Canada, for example, AWS looked at decades of data related to floods and other environmental factors before we settled on a location for the AWS Canada (Central) Region. Launched in 2016 in Montréal, Québec, this Region has three Availability Zones. Consistent with the Goldilocks zone concept, the region’s third Availability Zone (AZ3) is more than 45 kms (28 miles) away from the next-closest Availability Zone. Based on our years of experience building and operating AWS Regions around the world, this is enough distance to significantly reduce the risk of a single event impacting availability.
A natural disaster prompts Hydro-Quebec to transform its infrastructure — and Canadian AWS customers benefit
Canada’s Great Ice Storm of 1998 was one such unexpected weather event that became the catalyst for AWS customer Hydro-Québec to transform its infrastructure. “The ice storm gave us an opportunity to upgrade and establish a more robust and reliable power grid that could endure natural disasters and be repaired faster. It also allowed us to implement an improved company-wide approach to ensure and measure resiliency,” explains Christian Déjean, Chief of Economic Development & Strategy at Hydro-Québec. Now, AWS’s three Canadian Availability Zones are almost entirely powered by Hydro-Québec’s clean, renewable hydropower.
The improvements to the power grid in this geographic area, coupled with the redundancies designed in AWS data centers, provide AWS customers with a resilient infrastructure for their workloads in the AWS Canada (Central) Region. Water, power, telecommunications, and internet connectivity are designed with redundancy to maintain continuous operations in an emergency. Electrical power systems are designed to be fully redundant so that in the event of a disruption, uninterruptible power supply units can be engaged for certain functions, whereas generators can provide backup power for the entire facility. People and systems monitor and control the temperature and humidity to prevent overheating, further reducing possible service outages.
New Canadian Region helps more customers find the Goldilocks zone for disaster recovery
On November 8, 2021, AWS announced plans to open a second infrastructure Region in Alberta, Canada, in late 2023/early 2024. The AWS Canada West (Calgary) Region will consist of three Availability Zones at launch. With this new Region, AWS will be the only hyperscale cloud provider with a Region in Western Canada, driving greater fault tolerance, resiliency, and availability. Additionally, AWS has recently announced the availability of new services that can help customers plan and test resilience and DR, including AWS Resilience Hub, AWS Fault Injection Simulator, and AWS Elastic Disaster Recovery. And like the Canada (Central) Region, the new Canada West (Calgary) Region will follow the “Goldilocks zone” principle of making sure that its Availability Zones are not too close, but also not too far, from each other.
Learn more about disaster recovery planning with AWS
Designing for disaster recovery is an important investment that every organization needs to implement early on. Using the Goldilocks zone approach can help you optimize your DR without falling into the trap of requiring arbitrary distances between hosting sites. To get started, review our best practice resources below. Got questions? Contact our team.
- Rapidly recover mission-critical systems in a disaster
- Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud
- Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery
- Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
- A pragmatic approach to RPO zero
- Reliability Pillar – AWS Well-Architected Framework – Reliability Pillar
AWS Technology and Consulting Partners can help Canadian customers build DR capabilities. Browse our Partner list.
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.
La « zone Boucle d’Or » pour la reprise après sinistre, la planification de la continuité des activités et la préparation aux catastrophes
À travers le monde, les citoyens comptent sur leurs gouvernements pour une myriade de services publics essentiels, surtout en cas d’urgence. Cependant, les interruptions des systèmes informatiques peuvent également constituer des urgences graves, car elles peuvent avoir des impacts considérables sur les organisations et les personnes qui en dépendent. Alors que les événements climatiques extrêmes deviennent de plus en plus fréquents, les organisations du secteur public doivent concevoir leurs solutions informatiques de manière à ce qu’elles soient résilientes et elles doivent avoir un plan pour faire face aux événements inattendus. La reprise après sinistre (RS), soit le processus consistant à assurer une reprise rapide et fiable des systèmes informatiques afin de minimiser les temps d’arrêt et les pertes de données, est un investissement crucial pour les organisations du secteur public, au même titre que la planification de la continuité des activités (PCA) et la préparation aux catastrophes.
Pourquoi les anciennes stratégies de reprise après sinistre limitent les avantages de l’infonuagique
De nombreuses organisations du secteur public ont fait des progrès significatifs dans la modernisation de leur approche de l’informatique, notamment en adoptant le nuage. Cependant, des politiques obsolètes en matière de RS et de PCA empêchent les organisations de s’améliorer dans ces domaines essentiels. Réhéberger les anciennes stratégies de RS dans le nuage peut diminuer les avantages potentiels qu’offre le nuage dans l’amélioration de la résilience opérationnelle. Par exemple, les entreprises qui n’ont utilisé que l’hébergement sur site demandent souvent à leur nouveau fournisseur de services infonuagiques, pour fins de RS, à quelle distance se trouvent les centres de données infonuagiques les uns des autres. Cet accent mis sur les distances spécifiques entre les sites des centres de données provient de l’approche traditionnelle de la RS, selon laquelle plus la distance entre les centres de données d’une organisation est grande, moins il y a de chances qu’un seul événement perturbateur aura un impact sur les opérations informatiques de tous les centres de données en même temps.
Cette hypothèse a constitué le fondement des approches RS traditionnelles au cours des dernières décennies. C’est pourquoi Amazon Web Services (AWS) propose à ses clients des options RS qui incluent la possibilité de déployer des charges de travail dans une architecture active-active multirégionale, où les clients peuvent atteindre des objectifs de point de reprise (OPR) proches de zéro et des objectifs de temps de reprise (OTR) très bas. Par exemple, de nombreux clients canadiens d’AWS utilisent une deuxième Région AWS aux États-Unis ou ailleurs à des fins de RS. Cependant, certaines organisations souhaitent conserver leurs données à l’intérieur des frontières du Canada, et ce sont généralement ces organisations qui exigent des distances spécifiques entre les centres de données à des fins de DR. Les organisations ayant de telles exigences disposent d’une série d’options pour atteindre leurs OPR et OTR avec AWS, en utilisant la Région AWS au Canada qui est soutenue par trois Zones de disponibilité (soit des grappes de centres de données).
Les exigences de distance pour la reprise après sinistre ne vous aident pas à atteindre vos OPR et OTR
Les gouvernements et les organisations ne peuvent pas atteindre des OPR et OTR agressifs simplement en construisant des centres de données plus éloignés les uns des autres. Ce raisonnement ne tient pas compte d’une réalité essentielle : plus la distance est grande entre les centres de données, plus la latence du réseau est importante. À un certain moment, les limites imposées par la vitesse de la lumière rendent la réplication des données avec des bases de données relationnelles, ou encore l’exécution de systèmes distribués, très difficile. Malheureusement, aucun degré d’innovation ne permet d’augmenter la vitesse de la lumière. Cela pourrait signifier que les exigences de distance, qui sont censées contribuer à la réalisation des objectifs de DR, introduisent en fait une latence qui rend les OPR et OTR plus difficiles, voire impossibles à respecter. La latence, les temps d’arrêt et la perte de données sont littéralement intégrés dans l’approche traditionnelle.
Existe-t-il un point où l’augmentation de la distance entre les centres de données résulte en un rendement décroissant en termes d’atténuation des risques ? Après avoir construit et exploité 25 Régions AWS (grappes de Zones de disponibilité) et 81 Zones de disponibilité (grappes de centres de données) à travers le monde depuis 2006, nous pensons que oui.
La « zone Boucle d’Or » dans la planification de la reprise après sinistre
Le graphique suivant (figure 1) présente des estimations de la latence qui serait observée alors que les centres de données sont de plus en plus éloignés les uns des autres. Pour les applications à haute disponibilité, notre expérience démontre qu’il existe une « zone Boucle d’Or » pour la planification de l’infrastructure : une distance qui n’est ni trop proche, ni trop éloignée, mais juste ce qu’il faut. La zone Boucle d’Or est la distance entre les Zones de disponibilité ou les centres de données pouvant soutenir des OPR et OTR agressifs, tout en permettant une latence suffisamment faible pour les applications à haute disponibilité.
Si l’on considère le risque que représentent les catastrophes naturelles, il est évidemment préférable de s’éloigner. Mais après quelques dizaines de kilomètres seulement, les rendements diminuent. Et au-delà de quelques dizaines de kilomètres, les catastrophes atténuées seraient probablement des événements d’extinction, tel que le météore qui a tué les dinosaures. Il ne s’agit pas ici d’une fourchette exacte, et ce qui est considéré trop près varie selon la région géographique. Des facteurs tels que les activités sismiques, les plaines d’inondation centennale, ainsi que la probabilité d’ouragans et de typhons de grande ampleur, sont autant d’éléments qui influencent la façon dont nous considérons ce qui peut être trop près. Mais il faut toujours avoir des kilomètres de séparation.
Et qu’en est-il des distances trop grandes ? Nous examinons ici la latence entre toutes les Zones de disponibilité d’une Région et visons une latence aller-retour maximale d’environ une milliseconde. Que vous mettiez en place une réplication avec une base de données relationnelle ou que vous utilisiez un système distribué comme Amazon Simple Storage System (Amazon S3) ou Amazon DynamoDB, nous avons constaté que le maintien des conditions réseau, afin de prendre en charge les applications à haute disponibilité, devient assez difficile lorsque la latence dépasse une milliseconde.
| Distance entre les centres de données | |||
| 0 microsecondes | Dizaines de microsecondes | Centaines de microsecondes | Millisecondes |
| Zone Boucle d’Or | |||
| Centre de données de l’entreprise | |||
| L’autre côté de la rue | Kilomètres | Dizaines de kilomètres | Centaines de kilomètres |
Figure 1. Dans le domaine de la reprise après sinistre, la zone Boucle d’Or correspond à la bonne distance entre les centres de données, soit la distance qui permet de maintenir la latence en dessous d’une milliseconde tout en protégeant les données des entreprises contre les catastrophes naturelles dans une région spécifique. La zone Boucle d’Or se situe généralement dans les quelques dizaines de kilomètres entre les centres de données. Au-delà de quelques dizaines de kilomètres de distance entre les centres de données, soit à des centaines de kilomètres, les catastrophes atténuées seraient des événements de niveau d’extinction.
Au Canada, par exemple, AWS a examiné des décennies de données liées aux inondations et à d’autres facteurs environnementaux avant que nous choisissions un emplacement pour la Région AWS Canada (Centre). Lancée en 2016 à Montréal, au Québec, cette région compte trois Zones de disponibilité. Conformément au concept de la zone Boucle d’Or, la troisième Zone de disponibilité de la région (AZ3) se situe à plus de 45 km de la plus proche Zone de disponibilité. D’après nos années d’expérience en construction et en exploitation de Régions AWS dans le monde entier, cette distance est suffisante pour réduire de manière significative le risque qu’un événement unique ait un impact sur la disponibilité.
Une catastrophe naturelle incite Hydro-Québec à transformer son infrastructure; les clients canadiens d’AWS en profitent.
Au Canada, la Grande tempête de verglas de 1998 a été l’un de ces événements météorologiques inattendus qui a mené Hydro-Québec, client d’AWS, à transformer son infrastructure. « La tempête de verglas nous a donné l’occasion de moderniser et de mettre en place un réseau électrique plus robuste et plus fiable, capable de résister aux catastrophes naturelles et d’être réparé plus rapidement. Elle nous a également permis de mettre en œuvre une approche améliorée, à l’échelle de l’entreprise, pour garantir et mesurer la résilience », explique Christian Déjean, chef Stratégies d’attraction et développement économique chez Hydro-Québec. Aujourd’hui, les trois Zones de disponibilité canadiennes d’AWS sont presque entièrement alimentées par l’énergie hydroélectrique propre et renouvelable d’Hydro-Québec.
Les améliorations apportées au réseau électrique dans cette région géographique, associées aux redondances conçues dans les centres de données d’AWS, offrent aux clients d’AWS une infrastructure résiliente pour leurs charges de travail dans la Région AWS Canada (Centre). L’eau, l’électricité, les télécommunications et la connectivité Internet sont conçus de manière redondante afin de maintenir un fonctionnement continu en cas d’urgence. Les systèmes d’alimentation électrique sont conçus pour être entièrement redondants afin qu’en cas de perturbation, des unités d’alimentation sans interruption puissent être engagées pour certaines fonctions, tandis que des générateurs peuvent fournir une alimentation de secours pour l’ensemble de l’installation. Des personnes et des systèmes surveillent et contrôlent la température et l’humidité afin d’éviter toute surchauffe, ce qui réduit davantage les possibilités d’interruptions de service.
Une nouvelle Région canadienne aide davantage de clients à trouver la zone Boucle d’Or pour la reprise après sinistre
Le 8 novembre 2021, AWS a annoncé son projet d’ouvrir une deuxième Région d’infrastructure au Canada, soit en Alberta, vers la fin de 2023 ou le début de 2024. La Région AWS Canada Ouest (Calgary) sera composée de trois Zones de disponibilité lors de son lancement. Avec cette nouvelle Région, AWS sera le seul fournisseur de nuage à hyperconvergence ayant une Région dans l’Ouest canadien, ce qui améliorera davantage la résilience, la disponibilité et la tolérance aux pannes. De plus, AWS a récemment annoncé la disponibilité de nouveaux services qui peuvent aider les clients à planifier et à tester la résilience et la RS, notamment AWS Resilience Hub, AWS Fault Injection Simulator et AWS Elastic Disaster Recovery. Et comme la Région Canada (Centre), la nouvelle Région Canada Ouest (Calgary) suivra le principe de la « zone Boucle d’Or » en veillant à ce que ses Zones de disponibilité ne soient ni trop proches, ni trop éloignées les unes des autres.
En savoir plus sur la planification de la reprise après sinistre avec AWS
La conception d’un plan de reprise après sinistre est un investissement important que toute organisation doit mettre en œuvre dès le début. Utiliser l’approche fondée sur la zone Boucle d’Or peut vous aider à optimiser votre RS sans tomber dans le piège des distances arbitraires exigées entre les sites d’hébergement. Pour vous lancer, contactez notre équipe ici.
Les partenaires d’AWS en technologie et en expert-conseil peuvent aider les clients canadiens à développer leurs capacités de RS. Consultez la liste de nos partenaires.