AWS Open Source Blog
Scaling Cortex with parallel compaction
In this post, Albert Choi, an intern on the Amazon Managed Service for Prometheus team, shares his experience of designing and implementing parallel compactors inside of the Cortex open source project. The addition to the compactors enables Cortex to handle large volumes of active metrics per tenant. This blog post details the work done as part of an internship project. The feature is still under review and not yet available in Cortex.
Background
Cortex is a distributed system that allows for a horizontally scalable, highly available, and long-term storage solution for Prometheus metrics. Cortex is a Cloud Native Computing Foundation (CNCF) incubation project with an open source community working to continuously improve and make the software better for its users. Using Cortex, Amazon Managed Service for Prometheus is intended to provide a Prometheus-compatible monitoring service that simplifies the process of monitoring containerized applications at scale.
Currently, Cortex scales to 21-million active metrics per tenant—a single isolated unit for storing and querying metrics—and this limitation can force users to split their metrics across multiple tenants if their metrics footprint is larger than 21-million active metrics. In this article, we describe the design and implementation of how we improved the scalability of Cortex tenants by parallelizing the compactor.
How does compaction work in Cortex today?
Cortex stores time series metrics as block files based on Prometheus TSDB. A block file contains chunk files, which contain timestamp-value pairs for multiple series, and an index, which indexes metric names and labels to time series in the chunk files. These blocks are compacted at regular intervals to improve query performance and to reduce storage size. We found that as a tenant exceeded 21-million active metrics, the time to compact the blocks took longer than the two hour scheduled compaction interval. In Cortex, each tenant’s incoming metrics could only be processed by a single compactor, which meant that while we could scale out compactors to handle more tenants, we had no way to parallelize the compaction work for a single tenant.
This internship project set out to parallelize the compactor by designing an effective sharding strategy for the block compactions to enable Cortex to handle a larger number of active time series metrics.
Originally, each tenant was mapped to a single compactor, which meant that if a single compactor was overwhelmed all tenants handled by that compactor would be backlogged. As shown in Figure 1, when multiple tenant hashes are closest to a single compactor, the single compactor is required to handle all of those tenants. If the compactor takes too long on any one of those tenants, the entire group of tenants fall behind.
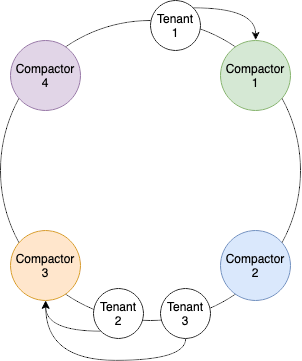
Each tenant’s block files are also compacted sequentially by a single compactor, which means a single time consuming block could become a bottleneck in the compaction process with no way to horizontally scale out compactors to recover the system. Figure 2 shows an example of how compactors executed against tenant block files prior to the introduction of parallel compaction.
![]()
In order to scale the compactor, we realized we needed compactors to more efficiently share work within a single tenant’s set of blocks, so that a single slow-to-process block file wouldn’t risk derailing the compaction process for the tenant.
Parallelizing the compactor
The design of the new compactor uses a shuffle-sharding strategy. Shuffle-sharding is used across various services at Amazon Web Services (AWS) to create fault-tolerant solutions and products. Within the Cortex compactor, shuffle-sharding is used to shard compactable groups of blocks effectively across multiple compactors to support effective scaling of the compactors. Figure 3 shows an example of how the same compaction groups defined previously are sharded with shuffle-sharding.
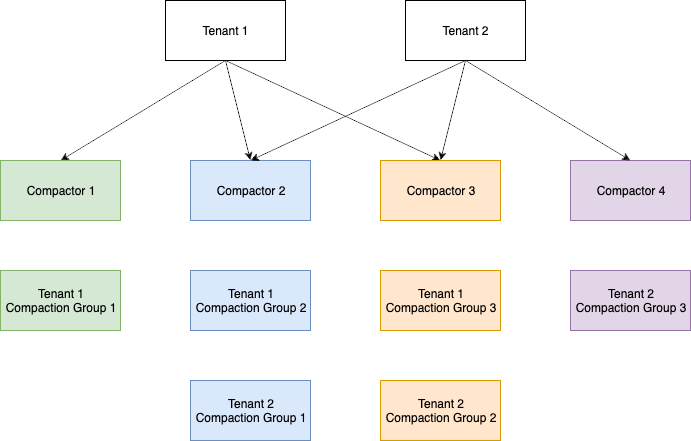
Unlike before where a single tenant’s blocks could only be mapped to a single compactor, the compaction groups—a set of block files—are more evenly distributed across all the available compactors. By mapping the compaction work across all compactors, we enable a single tenant’s blocks to be compacted by multiple compactors in parallel, reducing the bottlenecking impact of a single slow-to-process block in the compaction time. However, with a more even distribution, we create a risk that a single bad tenant could impact the compaction speeds of all other tenants. In other words, the blast radius for who was affected by slow-to-process blocks went from being a single tenant or a single set of tenants on the same compactor to potentially every tenant. By using the shuffle-sharding strategy and mapping a subset of the compactors to any set of tenants, we reduce the risk that a single tenant will cause another to be blocked as long as an appropriate shard size is used. In our Cortex PR, the shard size is defined by compactor.tenant-shard-size, which determines how many compactors each tenant will shard the compaction groups to.
Design
To implement the new shuffle-sharding strategy, rather than sharding the compaction group based only on the tenant name, we will instead select a configurable number of compactors to form a subring for each tenant. This subring will then be used to determine which compactor will handle the compaction of each group of blocks.
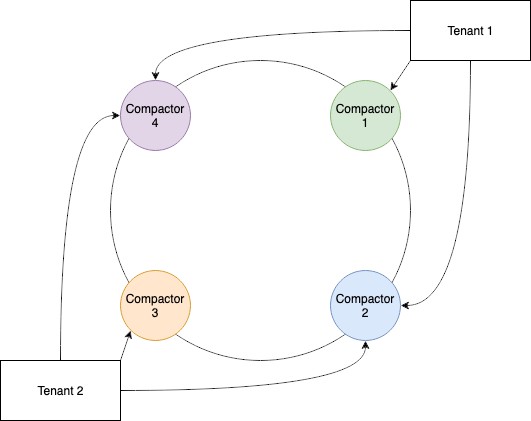
A hash ring was used to implement the shuffle-sharding. To begin, a subring of n compactors is chosen. This value is defined in the configuration file using compactor_tenant_shard_size. The visualization shown in Figure 4 uses the same blocks as used in the previous example.
Here, we will set compactor_tenant_shard_size: 3, so three compactors are selected for each tenant to form a subring. The subring for Tenant 1 consists of compactors 1, 2, and 3, whereas the subring for Tenant 2 consists of compactors 2, 3, and 4. As long as the compactors that are registered on the ring remain consistent, the subring for each tenant will also remain consistent for each compaction.
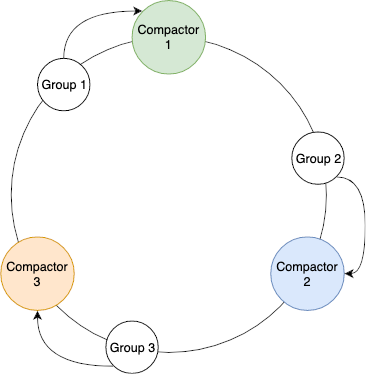
Upon determining the subring for the specified tenant, each group of compactable blocks is placed on the subring to determine which compactor should handle the compaction. Figure 5 shows the subring for Tenant 1 in our example and the groups on the ring. The groups will be handled by the compactor that is closest in a clockwise direction on the ring.
Implementation
The implementation of the scalable compactor came in two main steps. The first step was to generate all of the compaction groups. The second step was to determine which compactor should handle each of those compaction groups.
To generate all of the possible plans for block compaction, the blocks were grouped into the time ranges that are defined in the Cortex configuration. The time ranges determine the size of the resulting compacted blocks. For example, if the time ranges are 2h, 12h, and 24h (the default configuration), then compactions will result in the blocks first being grouped into two-hour blocks; afterward, the blocks will be compacted into 12-hour and 24-hour blocks. The compaction groups can be created by overlapping blocks (vertical compaction) or by adjacent blocks that fit within the specified time range.
To use the shuffle-sharding strategy for Cortex compactors, the following options should be set in the configuration file.
Results
Through load testing these changes, we observed that the compactors would be able to handle 83-million time series without having to be concerned about the compactors falling behind or blocking other tenants. During testing, we were limited to testing up to 83-million time series, and the compactor wasn’t the cause of the scalability limits; rather, these limits were caused by other resources and components. We expect that with further scalability improvements to the other Cortex components, we would observe higher compaction throughput.
Future enhancements
Currently, the compaction algorithm does not always perform the most efficient compactions when there are multiple compactions that can happen all at once. We see this, for example, if there are four blocks: two from 12:00 a.m. — 2:00 a.m. and two from 2:00 a.m. — 4:00 a.m., and if we have set compactor.block-ranges=2h0m0s,4h0m0s. Because we have block ranges 4h defined in our configuration, all of the blocks can and will be compacted together.
The current approach, however, favors compacting for the smallest group range possible, so the current approach will compact the overlapping blocks first into a two-hour block range, and then it will run another compaction to handle the two resulting blocks. Thus, with the current approach, there will be three total compactions completed to get a single final block. The optimal approach would have been to run a single compaction to combine all of the blocks. This is an area that can be further improved to help with the scalability of Cortex.
Personal experiences
Throughout my internship and working on this project, I gained significant exposure to collaboration with a larger open source community. I learned how workflows in open source differ as compared to working within a single team in a single organization. I also learned how to make decisions and consult the community for large changes that would impact the Cortex project and how to make sure that the changes were aligned with the community’s best interests.
In addition to what I learned regarding collaborating with an open source community, I was also strengthened my technical software engineering skills. I think that the biggest takeaway for me in this area is that I should make sure that I’m not reinventing the wheel. This is something that we often hear, but I found myself having to constantly keep it in mind and make sure that what I was trying to do had not already been implemented both within the Cortex project but also in general. Also, even if the exact code I was trying to implement hadn’t been written before, there would often be similar code, and I learned how to follow the code style and design patterns to maintain consistency across the code base.