Networking & Content Delivery
Target Group Load Shedding for Application Load Balancer
Load Shedding
Load shedding is the practice of sacrificing enough application traffic to keep partial availability in the presence of an overload condition. Used in conjunction with strategies like load balancing, load shedding helps applications support service level agreements (SLAs) when increased traffic overwhelms available system resources. While the cloud’s elasticity reduces the need for load shedding, it is still necessary when application initialization (or cold start) times reduce the effectiveness of elasticity. Load shedding is a simple concept often implemented with one shedding behavior in mind: “use it or lose it”.
At Amazon, we use a load shedding strategy to avoid overload in our own systems. It is discussed in detail in The Amazon Builders’ Library. In this blog, we will detail an automated load shedding implementation using native AWS services including Amazon Route 53, Amazon CloudWatch, Amazon EventBridge, AWS Lambda, and Amazon Simple Queue Service (SQS).
Load Shedding Approach
There are two common approaches we can implement load shedding in AWS: a DNS-based approach and a load balancer based approach. The DNS-based approach can resolve to a larger number of endpoints, but suffers from higher response times. The load balancer approach provides agile reactions to overload conditions, and can route traffic to supported load balancer targets. Today, both approaches require manual intervention or a self-developed solution to activate load shedding.
In the DNS-based approach, we use Route 53 to manage traffic destinations. We configure a weighted routing policy with a primary and secondary endpoint. Under normal load, we configure 100% of the traffic to the primary endpoint. In an overload situation, we increase the percentage of the traffic routed to the secondary endpoint and reduce the percentage routed to the primary. While this approach sheds load during an overload situation, the load shedding only takes effect after expiration of the DNS’ time to live (TTL) when clients refresh their DNS records against Route 53.
The load balancer based approach uses AWS’ Application Load Balancer (ALB) and its Weighted Target Group routing feature. Like the DNS-based approach, we configure load balancer listener rules to direct traffic against primary and secondary weighted target groups. Under normal load, we configure 100% of the traffic to the primary target group. In an overload situation, we increase the percentage of the traffic routed to the secondary target group. Unlike the DNS-based approach, the load balancer responds immediately to weighted target group modifications.
ALB Target Group Load Shedding Solution Overview
To automate this behavior, we built a serverless ALB Target Group Load Shedding (ALB TGLS) solution that performs load shedding via the load balancer based approach. The solution uses native AWS services including Amazon CloudWatch, Amazon EventBridge, AWS Lambda, and Amazon SQS. We built it with flexibility and configurability in mind to fit various use cases.
Let’s dive into the high-level architecture of the ALB TGLS solution (see Figure 1 below).
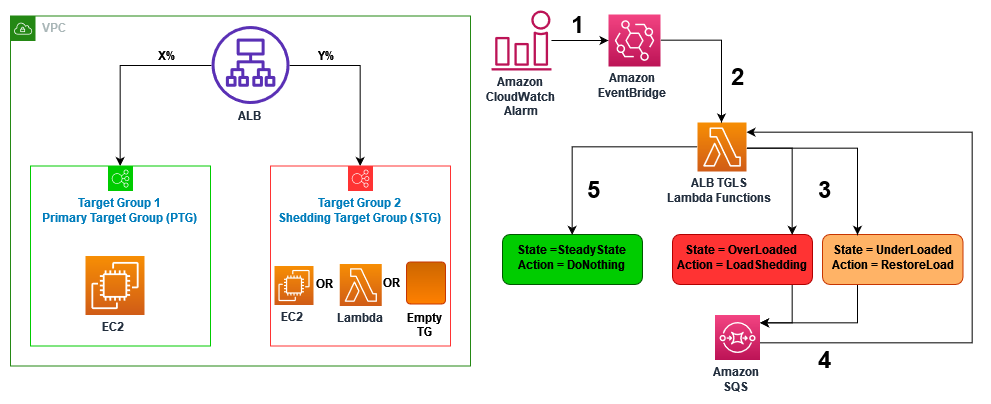
Figure 1: Application Load Balancer Target Group Load Shedding Solution Architecture
- An Amazon CloudWatch Alarm experiences a change in state. This state change is picked up by Amazon EventBridge. We can configure the CloudWatch Alarm to breach based on specific metric and threshold use case requirements.
- Amazon EventBridge invokes an ALB TGLS Lambda function.
- The Lambda function checks the current state of the environment. If the Primary Target Group (PTG) is either in the “OverLoaded” or “UnderLoaded” state, the solution takes the Load Shedding or Restore actions.
- For Load Shedding actions, the solution sheds an incremental configured percentage of traffic from the PTG to the Shedding Target Group (STG).
- For Load Restore actions, the solution restores an incremental configured percentage of traffic from the STG to the PTG.
- After Load Shedding and Restore actions, the solution sends a message to Amazon SQS with a visibility timeout for further evaluation until the PTG environment stabilizes.
- After a delay period, the Amazon SQS queue delivers a message to the ALB TGLS Lambda function. Upon receiving the message, the ALB TGLS Lambda function decides whether to further execute Load Shedding or Load Restore actions.
- The ALB TGLS Lambda Solution repeats points 3, 4, and 5 above until the environment reaches a steady state with 100% of the load back on the PTG environment. When the environment reaches the steady state, the solution stops the workflow and waits until the CloudWatch Alarm breaches again.
The solution performs Load Shedding and Restore actions in incremental percentages. Lambda function environment variables provide configurability. The configurable variables are:
ALB Target Group Load Shedding Strategies
Each customer use case may require different metrics, threshold, and breach intervals for triggering load shedding. You will find standard ALB CloudWatch metrics here. Most metrics that support the “TargetGroup” dimension will work well. However, we recommend production testing.
Here we examine some CloudWatch metrics for common use cases:
- RequestCountPerTarget
- This allows for an upper HTTP(S) request count limit per Target in the PTG. This is useful if you know the maximum number of HTTP(S) requests your target can handle.
- ActiveConnectionCount
- This allows for an upper limit on the number of Active TCP Connections.
- TargetResponseTime
- This metric is best when your use case requires a specific application response SLAs.
- HealthyHostCount or UnHealthyHostCount
- This allows for Load Shedding to be triggered based on the number of healthy hosts in the PTG. This approach provides a grace period to give the PTG EC2 fleet time to scale up. During the grace period, Load Shedding will remain active. When HealthyHostCount or UnHealthyHostCount returns to desired levels, the solution will deactivate Load Shedding.
- HTTPCode_Target_4XX_Count or HTTPCode_Target_5XX_Count
- Used in situations with elevated error rates in the PTG environment, allowing time for the PTG to catch up before restoring load.
Similarly, we expect the Shedding Target Group (Target Group 2) to respond with different strategies. The STG can serve traffic on a best-effort basis, generate a fixed user response, generate custom error responses, or generate a low resource error response.
Here are some options for configuring the ALB Shedding Target Group.
- Standby EC2 Environment
- Configuring the STG as an Instance Target Group with a ready fleet of instances allows for flexible responses to shed traffic. This fleet can serve several purposes:
- The standby fleet of instances can attempt to fulfill requests at a best-effort basis. Keep in mind that the requests may consume downstream microservices, databases, and other services. If the overload’s root cause is an overloaded downstream service, load shedding to the standby fleet will not alleviate the problem.
- The standby fleet can serve requests in a less resource intensive way by sending a fixed/static response or a response requiring less resources from the downstream application.
- The standby fleet can generate static or user-specific error pages.
- Configuring the STG as an Instance Target Group with a ready fleet of instances allows for flexible responses to shed traffic. This fleet can serve several purposes:
- Lambda Target Group
- Lambda can generate custom responses to users without self-managed EC2 or other “always-on” compute resources. Lambda can send either a Fixed Response to Shed requests or generate custom Error responses. This approach has a cost benefit of not always requiring a ready fleet of instances.
- Leave the STG empty
- In cases where it is acceptable to drop traffic, you can choose to leave the STG empty. ALB will generate an HTTP 503 error if a matched rule forwards to an empty target group.
Deploying the ALB Target Group Load Shedding Solution
Pre-requisites
To deploy this solution, you require the following:
- Application Load Balancer with a listener rule configured for weighted routing to two Target Groups. For guidance follow these steps.
- Weighted rules to be configured with 100 weight to Primary Target Group and 0 weight to Shedding Target Group.
- Configured AWS CDK environment (AWS Cloud9 is used for the demo – CDK comes preinstalled)
Deployment Steps
You can access the ALB TGLS Solution code on GitHub here. To simplify deployment, we created one app with an AWS Cloud Development Kit (CDK) stack. The CDK stack, ALBMonitorStack, deploys the ALB TGLS Solution for load shedding. This includes all required AWS Lambda functions and an Amazon SQS Queue. Secondly it deploys a demo CloudWatch Alarm and EventBridge rule. The default CloudWatch metric used in this demo is the sum of RequestCountPerTarget. The metric has a configurable threshold defaulted to 500.
- Connect to your AWS Cloud9 environment
- Update the CDK and Python pip package library
sudo npm install -g aws-cdk
pip install --upgrade pip- Clone the ALB TGLS repository and install requirements
git clone https://github.com/aws-samples/aws-alb-target-group-load-shedding
cd aws-alb-target-group-load-shedding/cdk
python3 -m pip install -r requirements.txt- Synthesize the CDK template
cdk synth -c elbTargetGroupArn="REPLACE_WITH_YOUR_ELBTARGETGROUP_ARN"Replace the elbTargetGroupArn context parameter value with the ARN for your desired Primary Target Group. The stack uses the elbTargetGroupArn parameter value to generate the correct CloudFormation template.
- Deploy the ALB TGLS ALBMonitorStack CDK template to your AWS Account
cdk deploy ALBMonitorStack -c elbTargetGroupArn="REPLACE_WITH_YOUR_ELBTARGETGROUP_ARN" --parameters elbArn="REPLACE_WITH_YOUR_ELB_ARN" –-parameters elbListenerArn="REPLACE_WITH_YOUR_ELBLISTENER_ARN"Provide the appropriate parameter values. The following parameters are required:
Provide the appropriate parameter values. The following parameters are optional:
ALB TGLS Solution in action
For demo purposes, our test environment has an ALB configured to send traffic to a Primary Target Group with two instances. The Shedding Target Group is on standby with another 2 instances. We configured the Primary Target Group with EC2 Autoscaling to react to increases in load, but the instance application takes time to bootstrap.

Figure 2: ALB Traffic before Load Shedding
We deployed the ALB TGLS Solution in an AWS account. In our scenario, the CloudWatch alarm breaches when Sum of RequestCountPerTarget exceeds 50,000 for 1 of 1 data points within 1 minute. We chose this number as we know each EC2 backend instance will sustain 60,000 requests per minute. We want load shedding to occur before load reaches 60,000 requests per minute. Load shedding and restore actions will happen at 5 percent increments. The load shedding will give the PTG environment time to scale up or the increased load to subside, whichever comes first. The primary goal is to ensure no overload of our primary environment.
Example CDK deploy command for the demo parameters.
cdk deploy ALBMonitorStack -c elbTargetGroupArn=" REPLACE_WITH_YOUR_ELBTARGETGROUP_ARN" --parameters elbArn=" REPLACE_WITH_YOUR_ELB_ARN" --parameters elbListenerArn=" REPLACE_WITH_YOUR_ELBLISTENER_ARN" --parameters elbShedPercent="5" --parameters elbRestorePercent="5" --parameters cwAlarmThreshold="50000" --parameters cwAlarmPeriods="1" --parameters cwAlarmMetricStat="sum"
Figure 3: CloudWatch Alarm Set to 50,000 Requests Per Target
Load Test Setup
To load test the environment, we use the Distributed Load Testing on AWS Solution from the AWS Solutions Library. We deployed the solution using the provided AWS CloudFormation template. The solution creates a user-friendly UI hosted on Amazon CloudFront to configure load tests. As seen in Figure 4, the load testing solution is configured to ramp up 10 container tasks over 20 minutes. Each task is configured with a request concurrency of 30, sustained for 40 minutes – meaning the test will run 1hr in total.
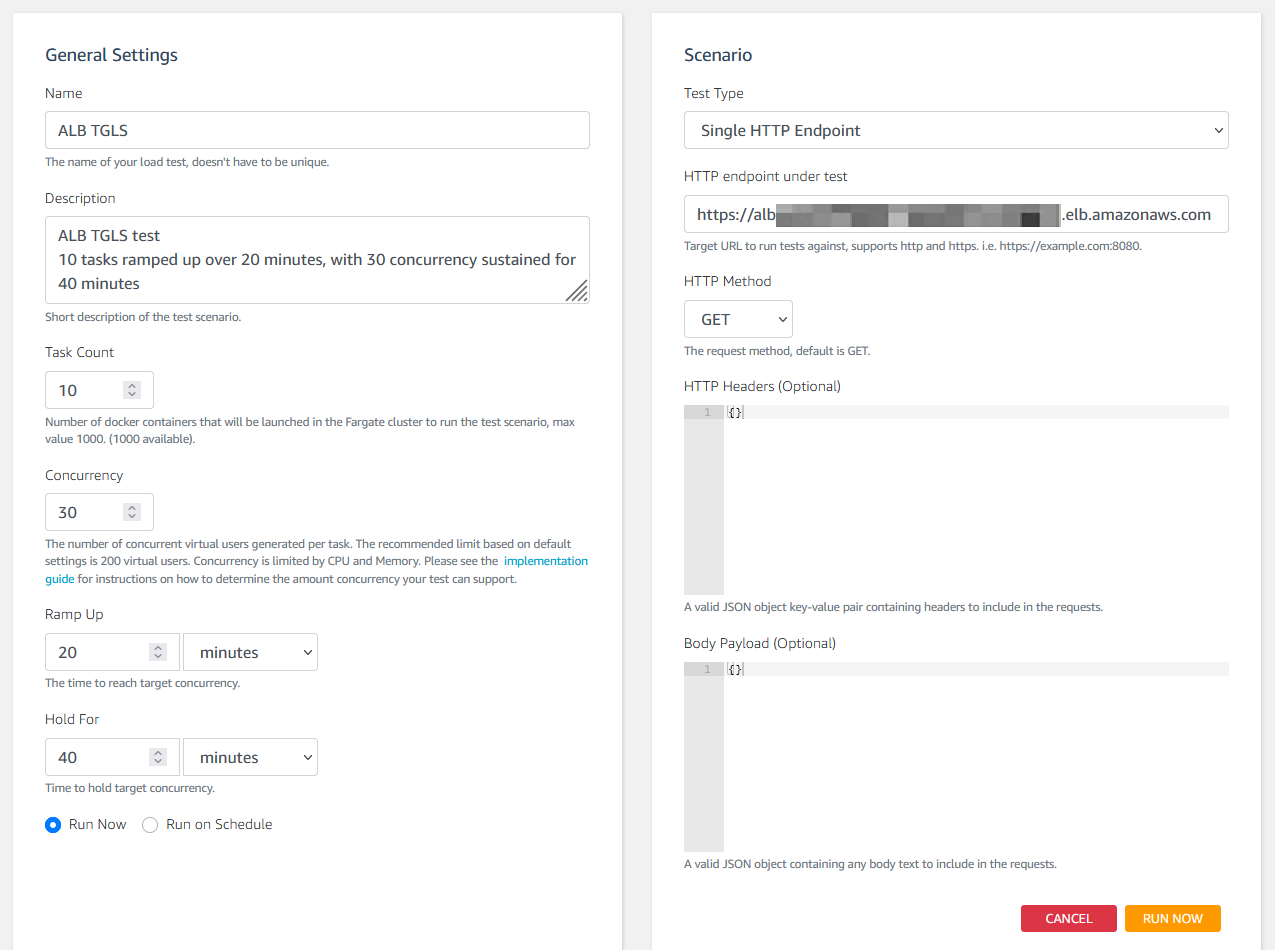
Figure 4: AWS Distributed Load Test Configuration Settings
Fast-forward to after the load test completes and let’s look at what happened. The graph in Figure 5 below shows PTG traffic in Blue and STG traffic in Orange. As the CloudWatch Alarm breaches, the graph shows the ALB TGLS Solution load shedding this traffic from the primary to the secondary target group. Traffic is Shed and Restored at the configured percentage intervals, giving the primary group time to scale and increase its capacity without being overloaded.

Figure 5: ALB TGLS in action – CloudWatch Metrics Responding to Load Test
We’ve annotated each interesting reference point in Figure 6 below…
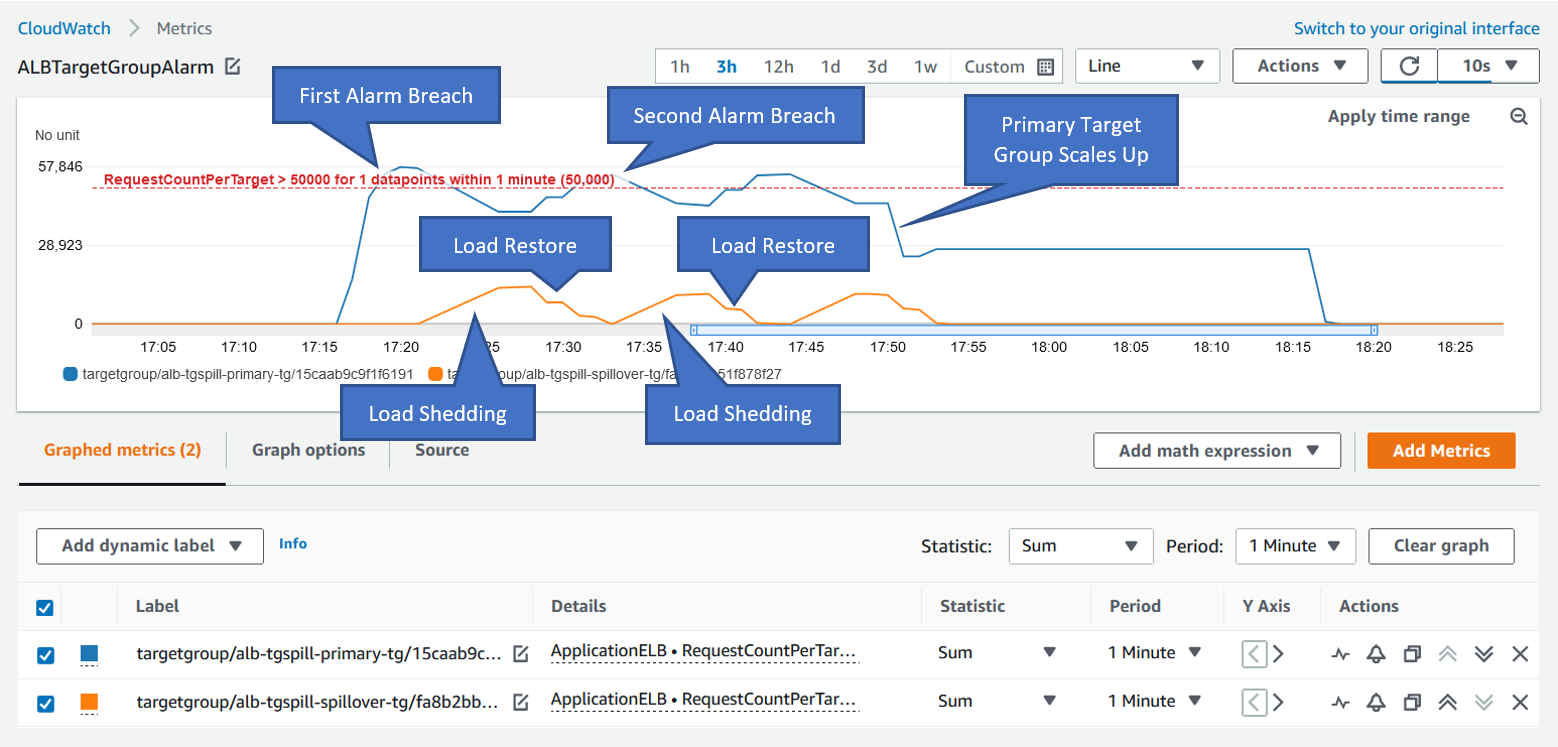
Figure 6: Annotated CloudWatch Metrics Graph
The PTG environment scaled up at 17:50 and although the PTG experienced delayed scaling, the load shedding actions prevented PTG from being overloaded. As seen in Figure 7 below, EC2 Autoscaling increased the PTG instance count from 2 to 4; whilst at the peak ALB TGLS configured the ALB weighted target group load shedding to split 75% of the traffic load to the PTG, and 25% to the STG at the peak.

Figure 7: ALB Load Shedding 75 percent PTG 25 percent STG
Earlier we stated the PTG environment can handle a peak of 60,000 Requests per Target. As seen in Figure 8 below, the RequestCountPerTarget metric never breached the 60,000 limit. PTG did however come close with a 57,846 RequestCountPerTarget data point. To tune the solution and create a larger safety margin, we can:
- Lower the CloudWatch Alarm threshold from 50,000 to a more appropriate number and/or
- Increase the elbShedPercent from 5 to 10 percent. This allows the solution to shed more traffic with each load shedding action.

Figure 8: CloudWatch Metrics Showing Near 60,000 Requests Per Target and Successful Load Shedding
Conclusion
In this blog post we discussed the Application Load Balancer Target Group Load Shedding Solution. The solution assists AWS customers with implementing automated load shedding for their Application Load Balancers based on unique use case requirements. Depending on their requirements customers can customize alarm metrics, alarm thresholds, load shedding and restore velocity, and behavior in response to load shedding traffic in the secondary environment.
Additionally, we covered how to deploy the solution into your AWS Account using the Amazon Cloud Development Kit template and showed the solution in action.
It’s recommended to perform thorough real-world load tests with your unique traffic patterns before deploying to any production environment. Tuning and testing the available parameters is critical to achieve a production ready solution.

Eugene Wiehahn
Eugene is a Sr. Solutions Architect at AWS based in Chicago. Originally from Cape Town, South Africa, he works with AWS customers to architect solutions aimed at achieving their desired business outcomes. In his spare time you can catch him spending time with his wife and daughter – this usually means having a braai and eating too much biltong.

John Walker
John is a Sr. Solutions Architect at AWS based in Texas. He enjoys spending time with his wife and two sons, reading, coding projects, little bits of carpentry, a bit of robotics, and hates jogging but does it anyway.

Michael Han
Michael is a Principal Solutions Architect at AWS based in Chicago. When away from work, he spends his time running and keeping his kids from destroying the house.