Microsoft Workloads on AWS
Continuous Replication to Amazon RDS for SQL Server from Azure SQL
In this blog post, we will explore how to set up continuous database replication from Azure SQL to Amazon Relational Database Service (Amazon RDS) for SQL Server using SQL Data Sync for Azure (SQL Data Sync). Customers often replicate data across cloud platforms for various reasons, such as implementing a multicloud strategy, addressing performance challenges, or enabling disaster recovery and platform transitions.
This solution leverages the SQL Data Sync Agent running on an Amazon Elastic Compute Cloud (Amazon EC2) instance. Key benefits of this solution include facilitating seamless migration or disaster recovery from Azure SQL to Amazon RDS for SQL Server, as well as enabling bi-directional synchronization for an active-active configuration.
Introduction
When developing a migration strategy, customers must address several challenges. A critical factor in ensuring a successful migration design is the ability to meet the Recovery Time Objective (RTO). While native options may suffice for migrations from Infrastructure as a Service (IaaS) or self-managed environments, additional considerations come into play when migrating from Platform as a Service (PaaS) or other managed services.
Customers that want to migrate from Azure SQL to Amazon RDS for SQL Server have several options to evaluate. For a one-time bulk load, Smart Bulk Copy is a viable solution that aims to minimize downtime. However, many customers require near real-time replication during the migration. While AWS Database Migration Service (AWS DMS) can perform a one-time full database load, it does not support continuous replication with Azure SQL databases.
Customers operating in a multicloud environment are increasingly looking for disaster recovery solutions to safeguard their workloads. Databases, being one of the most critical components of their workload, require special attention. For customers with stringent RTO (Recovery Time Objective) and RPO (Recovery Point Objective) requirements, near real-time replication is a must.
In this solution, we will set up replication from Azure SQL to Amazon RDS for SQL Server using SQL Data Sync for Azure. SQL Data Sync employs a hub-and-spoke architecture to synchronize databases with the hub database always being an Azure SQL database and the member database being an instance of Amazon RDS for SQL Server. While this solution is designed for Amazon RDS for SQL Server, it will work equally well for the self-hosted SQL Server on Amazon EC2.
Solution
In this architecture (Figure 1), we have deployed an Azure SQL database in a private subnet within the Microsoft Azure Cloud (source) and an Amazon RDS for SQL Server instance in a private subnet in the AWS Cloud (target). For this blog, the Amazon RDS for SQL Server instance is deployed in a single Availability Zone. An Amazon EC2 instance hosts the SQL Data Sync Agent, with connectivity established via a private endpoint to access the Azure SQL database. When implementing this setup, it is important to consider network latency, which may vary depending on your network configuration and the regions involved. Also, be aware of network egress charges as data is copied.
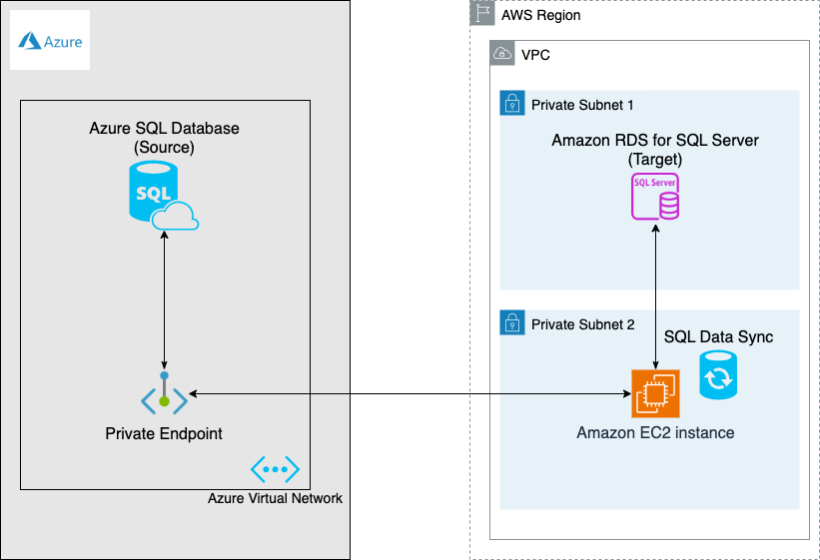
Figure 1 – Azure SQL to Amazon RDS architecture
Prerequisites
The following prerequisites are necessary for this solution.
- AWS
- An active AWS Account.
- An Amazon RDS for SQL Server or self-hosted SQL Server on EC2 instance. If this does not exist, create this resource in Step 2 of the Walkthrough.
- An Amazon EC2 Windows instance to host the SQL Data Sync Agent. If this does not exist, create this resource in Step 5 of the Walkthrough.
- Monitoring tools for Amazon RDS.
- Azure
- An active Azure subscription.
- An Azure SQL database as the hub database. If this does not exist, create this resource in Step 1 of the Walkthrough.
- Monitoring tools for Azure SQL.
SQL Data Sync has a set of requirements and limitations. Please review these to see how they may relate to your database.
Walkthrough
For this example, we will use the Northwinds sample SQL database as the source database hosted in Azure SQL. The target database is hosted in Amazon RDS for SQL Server. The replication direction is from Azure SQL to Amazon RDS for SQL Server.
-
- Select or create an Azure SQL database
Pull the Northwinds SQL installation from the SQL Server samples GitHub repository. Using SQL Server Management Studio (SSMS), run the SQL script instnwnd.sql from the GitHub repository against the Azure SQL database to populate the Northwinds database used in this scenario.We can verify the data is loaded correctly by running a simple SQL query to return the number of rows in the Orders table.SELECT COUNT(*) AS RecordCount FROM Orders RecordCount ----------- 830Create a separate Azure SQL database that will act as the Sync Metadata Database. The Sync Metadata Database contains the metadata and logs for Data Sync. The Sync Metadata Database has to be an Azure SQL database located in the same region as the Hub Database.
- Select or create an Amazon RDS for SQL Server instance
If you don’t have an existing Amazon RDS for SQL Server, you can follow the tutorial, Create and Connect to a Microsoft SQL Server Database with Amazon RDS to create one. Next, create a new empty database in Amazon RDS for SQL Server that will serve as the replication target for the Azure SQL database source. For this blog, we will create a database called Northwinds in Amazon RDS for SQL Server. - Create the Azure Data Sync Group
From the Azure portal, select the Northwinds SQL database created earlier and then select, Sync to other databases. From there, select to create a New Sync Group (Figure 2) providing the following details.Parameter Value Sync Group Name Choose an appropriate name for this Data Sync Group Sync Metadata Database Select the Sync Metadata Database created in Step 1 Automatic Sync On | Off If On, select the frequency of database synchronizations based on your desired update rate. This frequency can be specified in seconds, minutes, hours, or days depending on how transactional the source database is and your desired RPO Conflict Resolution Select either Hub win or Member win Hub Database Username Username for the Hub database created in Step 1 Hub Database Password Password for the Hub database user created in Step 1 Private Link Option Select this option if you have private connectivity between your Azure and AWS environments 
Figure 2 – Create Data Sync Group
- Create the Sync Agent
To create the Sync Agent that will allow connections from Azure SQL to our target Amazon RDS for SQL Server database, select Add an On-Premises Database within the Sync Group created in Step 3. This will bring up the UI to Select Sync Agent. Select Create a new agent (Figure 3), provide a name for the agent, and select Create and Generate Key. The key that is generated will be used in the installation of the Data Sync Agent on the Amazon EC2 instance.
Figure 3 – Create Sync Agent
- Install the Data Sync Agent on Amazon EC2
Within a VPC subnet that has access to the Amazon RDS for SQL Server instance, launch a Windows Server 2022 Amazon EC2 instance. The sizing of this instance will depend on the amount and frequency of data being synchronized between the two environments. We recommend starting with an Amazon EC2 M5.large instance and adjust the instance size as required.Connect to this Amazon EC2 instance using the Fleet Manager feature of AWS Systems Manager or your normal method of remotely connecting to Amazon EC2 Windows instances. Download the SQL Azure Data Sync Agent onto the Amazon EC2 instance. After installation, configure the agent to connect to the Sync Metadata Database (Figure 4). You will need the Agent Key generated in Step 4, along with the appropriate user credentials to complete the connection to the Sync Metadata Database. After successful registration, you can select Ping Sync Service to verify connectivity.
Figure 4 – Sync Metadata Database Configuration
- Connect the Data Sync Agent to Amazon RDS for SQL Server
In the Microsoft SQL Data Sync UI, select Register to connect the Sync Agent with the Amazon RDS for SQL Server instance and database (Figure 5). You can use either SQL or Windows authentication depending on your Amazon RDS configuration. Verify connectivity be selecting the Test Connection button.
Figure 5 – Sync Agent registration with Amazon RDS
- Add the Amazon RDS for SQL Server target to the Azure Sync Group
From the Azure Portal (Figure 6), select the Sync Group, azsqlsyncgrp1 created earlier, Select sync members, and then select, Add an On-Premises Database. Choose the Data Sync Agent created in Step 4. Please note the drop-down value for Sync Directions. This can include a bi-directional or unidirectional synchronization either from or to Azure SQL. In this example, we will choose From the Hub in order to synchronize from Azure SQL to Amazon RDS for SQL Server.
Figure 6 – Hub Database and Sync Group
The direction of the synchronization will be determined by your use case. There are three options for the synchronization direction (Figure 7).
- For a migration or creating a disaster recovery copy on Amazon RDS for SQL Server, choose to replicate From the Hub.
- If the database was failed over and then ready to failback, choose To the Hub to reverse the direction of the synchronization.
- For an active-active configuration, choose Bi-directional Sync, noting the choice of conflict resolution from Step 3.

Figure 7 – Add Amazon RDS for SQL Server target
- Choose the tables to synchronize
From the Sync Group in the Azure portal, we need to select the tables from the source Azure SQL database that we want to synchronize. In this example, we are selecting all tables from the Northwinds database (Figure 8).
Figure 8 – Select tables for synchronization
- Start the synchronization process
With both the target and source configured, we can start the synchronization. We did not configure automatic synchronization; we will manually run the synchronization process. From the Sync Group, select the Sync button to initiate the synchronization (Figure 9). Look for a Sync completed message from the logs in the Sync Group UI.
Figure 9 – Database synchronization
- Verify the results
We can connect to our Amazon RDS for SQL Server instance and run the same SQL query from Step 1 for the Orders table and verify that it matches the count from our source (830 rows). Verify that all tables included in the replication process have equal row counts.SELECT COUNT(*) AS RecordCount FROM Orders RecordCount ----------- 830
- Select or create an Azure SQL database
Cleanup
If you have deployed any AWS resources by following the solution outlined in this blog, they will incur costs. Terminate any Amazon EC2 instances or Amazon RDS for SQL Server instances that you no longer need to avoid any ongoing future charges.
Conclusion
In this blog, we demonstrated how to use the SQL Data Sync Agent to provide near real-time from Azure SQL to Amazon RDS for SQL Server. Depending on the replication direction, this solution can be used as a migration tool with continuous replication, disaster recovery, or even an active-active configuration.
AWS has significantly more services, and more features within those services, than any other cloud provider, making it faster, easier, and more cost effective to move your existing applications to the cloud and build nearly anything you can imagine. Give your Microsoft applications the infrastructure they need to drive the business outcomes you want. Visit our .NET on AWS and AWS Database blogs for additional guidance and options for your Microsoft workloads. Contact us to start your migration and modernization journey today.