Artificial Intelligence
Tag: Amazon Machine Learning
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
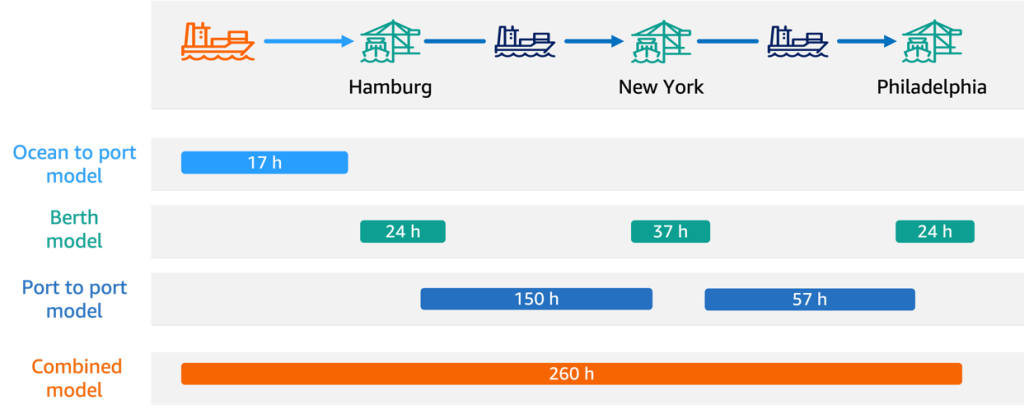
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.

Pioneering AI workflows at scale: A deep dive into Asana AI Studio and Amazon Q index collaboration
Today, we’re excited to announce the integration of Asana AI Studio with Amazon Q index, bringing generative AI directly into your daily workflows. In this post, we explore how Asana AI Studio and Amazon Q index transform enterprise efficiency through intelligent workflow automation and enhanced data accessibility.
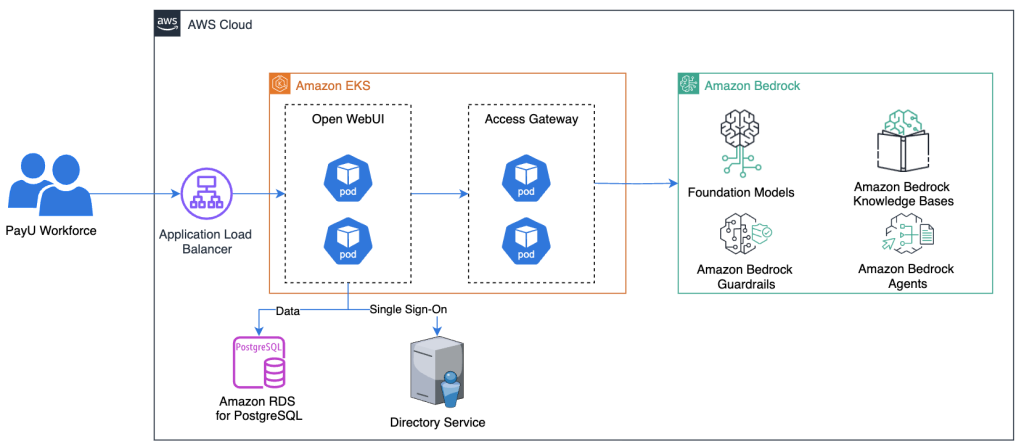
How PayU built a secure enterprise AI assistant using Amazon Bedrock
PayU offers a full-stack digital financial services system that serves the financial needs of merchants, banks, and consumers through technology. In this post, we explain how we equipped the PayU team with an enterprise AI solution and democratized AI access using Amazon Bedrock, without compromising on data residency requirements.

Choosing the right approach for generative AI-powered structured data retrieval
In this post, we explore five different patterns for implementing LLM-powered structured data query capabilities in AWS, including direct conversational interfaces, BI tool enhancements, and custom text-to-SQL solutions.

Build a scalable AI assistant to help refugees using AWS
The Danish humanitarian organization Bevar Ukraine has developed a comprehensive virtual generative AI-powered assistant called Victor, aimed at addressing the pressing needs of Ukrainian refugees integrating into Danish society. This post details our technical implementation using AWS services to create a scalable, multilingual AI assistant system that provides automated assistance while maintaining data security and GDPR compliance.

Enhanced diagnostics flow with LLM and Amazon Bedrock agent integration
In this post, we explore how Noodoe uses AI and Amazon Bedrock to optimize EV charging operations. By integrating LLMs, Noodoe enhances station diagnostics, enables dynamic pricing, and delivers multilingual support. These innovations reduce downtime, maximize efficiency, and improve sustainability. Read on to discover how AI is transforming EV charging management.

Build an AI-powered document processing platform with open source NER model and LLM on Amazon SageMaker
In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.

Reducing hallucinations in LLM agents with a verified semantic cache using Amazon Bedrock Knowledge Bases
This post introduces a solution to reduce hallucinations in Large Language Models (LLMs) by implementing a verified semantic cache using Amazon Bedrock Knowledge Bases, which checks if user questions match curated and verified responses before generating new answers. The solution combines the flexibility of LLMs with reliable, verified answers to improve response accuracy, reduce latency, and lower costs while preventing potential misinformation in critical domains such as healthcare, finance, and legal services.

Trellix lowers cost, increases speed, and adds delivery flexibility with cost-effective and performant Amazon Nova Micro and Amazon Nova Lite models
This post discusses the adoption and evaluation of Amazon Nova foundation models by Trellix, a leading company delivering cybersecurity’s broadest AI-powered platform to over 53,000 customers worldwide.