Artificial Intelligence
Performing batch inference with TensorFlow Serving in Amazon SageMaker
After you’ve trained and exported a TensorFlow model, you can use Amazon SageMaker to perform inferences using your model. You can either:
- Deploy your model to an endpoint to obtain real-time inferences from your model.
- Use batch transform to obtain inferences on an entire dataset stored in Amazon S3.
In the case of batch transform, it’s becoming increasingly necessary to perform fast, optimized batch inference on large datasets.
In this post, you learn how to use Amazon SageMaker batch transform to perform inferences on large datasets. The example in this post uses a TensorFlow Serving (TFS) container to do batch inference on a large dataset of images. You also see how to use the new pre– and post-processing feature of the Amazon SageMaker TFS container. This feature enables your TensorFlow model to make inferences directly on data in S3 and also save post-processed inferences to S3.
Overview
The dataset in this example is the “Challenge 2018/2019” subset of the Open Images V5 Dataset. This subset consists of 100,000 images in JPG format for a total of 10 GB. The model you use is an image-classification model based on the ResNet-50 architecture that has been trained on the ImageNet dataset and exported as a TensorFlow SavedModel. Use this model to predict the class of each image (for example, boat, car, bird). You write a pre– and post-processing script and package it with the SavedModel to perform inferences quickly, efficiently, and at scale.
Walkthrough
When you run a batch transform job, you specify:
- Where your input data is stored
- Which Amazon SageMaker Model object (named “Model”) to use to transform your data
- The number of cluster instances to use for your batch transform job
In our use case, a Model object is an HTTP server that serves a trained model artifact, a TensorFlow SavedModel, via the Amazon SageMaker TFS container. Amazon SageMaker batch transform distributes your input data among the instances.
To each instance in the cluster, Amazon SageMaker batch transform sends HTTP requests for inferences containing input data from S3 to the Model. Amazon SageMaker batch transform then saves these inferences back to S3.
Data often must be converted from one format to another before it can be passed to a model for predictions. For example, images may be in PNG or JPG format, but they must be converted into a format the model can accept. Also, sometimes other preprocessing of the data, such as resizing of images, must be performed.
Using the Amazon SageMaker TFS container’s new pre– and post-processing feature, you can easily convert data that you have in S3 (such as raw image data) into a TFS request. Your TensorFlow SavedModel can then use this request for inference. Here’s what happens:
- Your pre-processing code runs in an HTTP server inside the TFS container and processes incoming requests before sending them to a TFS instance within the same container.
- Your post-processing code processes responses from TFS before they are saved to S3.
The following diagram illustrates this solution.
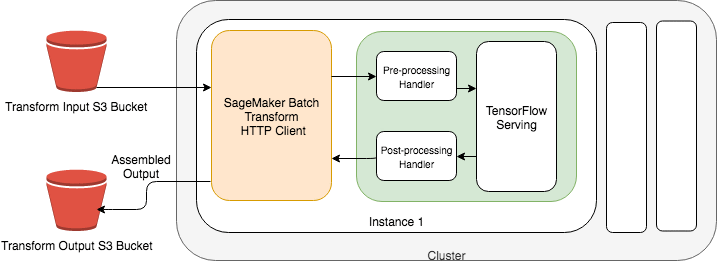
Performing inferences on raw image data with an Amazon SageMaker batch transform
Here are the three steps required for implementation:
- Write a pre– and post-processing script for JPEG input data.
- Package a Model for JPEG input data.
- Run an Amazon SageMaker batch transform job for JPEG input data.
To write a pre– and post-processing script for JPEG input data
To make inferences, you first preprocess your image data in S3 to match the serving signature of your TensorFlow SavedModel, which you can inspect using thesaved_model_cli. The following is the serving signature of the ResNet-50 v2 (NCHW, JPEG) model:
The Amazon SageMaker TFS container uses the model’s SignatureDef named serving_default, which is declared when the TensorFlow SavedModel is exported. This SignatureDef says that the model accepts a string of arbitrary length as input, and responds with classes and their probabilities. With your image classification model, the input string is a base64 encoded string representing a JPEG image, which your SavedModel decodes. The Python script that you use for pre– and post-processing, inference.py, is reproduced as follows:
The input_handler intercepts inference requests, base64 encodes the request body, and formats the request body to conform to the TFS REST API. The return value of the input_handler function is used as the request body in the TensorFlow Serving request. Binary data must use key “b64”, according to the TFS REST API.
Because your serving signature’s input tensor has the suffix “_bytes,” the encoded image data under key “b64” is passed to the “image_bytes” tensor. Some serving signatures may accept a tensor of floats or integers instead of a base64 encoded string. However, for binary data (including image data), your model should accept a base64 encoded string for binary data because JSON representations of binary data can be large.
Each incoming request originally contains a serialized JPEG image in its request body. After passing through the input_handler, the request body contains the following, which TFS accepts for inference:
The first field in the return value of output_handler is what Amazon SageMaker batch transform saves to S3 as this example’s prediction. In this case, output_handler passes the content on to S3 unmodified.
Pre– and post-processing functions let you perform inference with TFS on any data format, not just images. To learn more about the input_handler and output_handler, see the Amazon SageMaker TFS Container README.
Packaging a model for JPEG input data
After writing a pre– and post-processing script, package your TensorFlow SavedModel along with your script into a model.tar.gz file. Then, upload the file to S3 for the Amazon SageMaker TFS container to use. The following is an example of a packaged model:
The number 1538687370 refers to the model version number of the SavedModel, and this directory contains your SavedModel artifacts. The code directory contains your pre– and post-processing script, which must be named inference.py. It also contains an optional requirements.txt file, which is used to install dependencies (with pip) from the Python Package Index before the batch transform job starts. In this use case, you don’t need any additional dependencies.
To package your SavedModel and your code, create a GZIP tar file named model.tar.gz by running the following command:
Use this model.tar.gz when you create a Model object to run batch transform jobs. To learn more about packaging a model, see the Amazon SageMaker TFS Container README.
After creating a model artifact package, upload your model.tar.gz and create a Model object that refers to your packaged model artifact and the Amazon SageMaker TFS container. Specify that you are running in Region us-west-2 using TFS 1.13.1 and GPU instances.
The following code examples use both the AWS CLI, which is helpful for scripting automated pipelines, and the Amazon SageMaker Python SDK. However, you can create models and Amazon SageMaker batch transform jobs using any AWS SDK.
AWS CLI
Amazon SageMaker Python SDK
Running an Amazon SageMaker transform job for JPEG input data
Now, use the Model object you created to run batch predictions with Amazon SageMaker batch transform. Specify the S3 input data, the content type of the input data, the output S3 bucket, and the instance type and count.
You must specify two additional parameters that affect performance: max-payload-in-mb and max-concurrent-transforms.
The max-payload-in-mb parameter determines how large request payloads can be when sending requests to your model. Because the largest object in your S3 input is less than one megabyte, set this parameter to 1.
The max-concurrent-transforms parameter determines how many concurrent requests to send to your model. The value that maximizes throughput varies according to your model and input data. For this post, it was set to 64 after experimenting with powers of two.
AWS CLI
Amazon SageMaker Python SDK
Your input data consists of 100,000 JPEG images. The S3 input data path looks like this:
In tests, the batch transform job finished transforming the 100,000 images in 12 minutes on two ml.p3.2xlarge instances. You can easily scale your batch transform jobs to handle larger datasets or run faster by increasing the instance count.
After the batch transform job completes, inspect the output. In your output path, you find one S3 object per object in the input:
Inspecting one of the output objects, you see the prediction from the model:
So that’s how to get inferences on a dataset consisting of JPEG images. In some cases, you may have converted your data to TFRecords for training or to encode multiple feature vectors in a single record. The following section shows how to perform batch inference with TFRecords.
Performing inferences on a TFRecord dataset with an Amazon SageMaker batch transform
TFRecord is a record-wrapping format commonly used with TensorFlow for storing multiple instances of tf.Example. With TFRecord, you can store multiple images (or other binary data) in a single S3 object, along with annotations and other metadata.
Amazon SageMaker batch transform can split an S3 object by the TFRecord delimiter, letting you perform inferences either on one example at a time or on batches of examples. Using Amazon SageMaker batch transform to perform inference on TFRecord data is similar to performing inference directly on image data, per the example earlier in this post.
To write a pre– and post-processing script for TFRecord data
Assume that you converted the image data used earlier into the TFRecord format. Rather than performing inference on 100,000 separate S3 image objects, perform inference on 100 S3 objects, each containing 1000 images bundled together as a TFRecord file. The images are stored in key “image/encoded” in a tf.Example and these tf.Examples are wrapped in the TFRecord format. We can perform inference on these TFRecords and output them in any data format, like JSON or CSV.
Now, tell Amazon SageMaker batch transform to split each object by a TFRecord header and do inference on a single record at a time, so that each request contains one serialized tf.Example. Use the following pre– and post-processing script to perform inference:
Your input handler extracts the image data from the value stored in the tf.Example’s key “image/encoded”. It then base64 encodes the image data for inference in TFS, just as in the previous example for JPEG input data.
Each output object contains 1000 predictions (one per image in the input object). These predictions are ordered in the same way they were in the input object. Your output_handler removes white space from the output JSON-formatted string that represents each TFS prediction. This way, the output S3 object can adhere to the JSONLines format, making it easier to parse. Later, configure your batch transform job to join each record with a newline character.
The pre-processing script requires additional dependencies to parse the input data. Add a dependency on TensorFlow to the requirements.txt file in the previous example so you can parse the serialized instances of tf.Example:
TensorFlow 1.13.1 is installed when each transform job starts. There are other options for including external dependencies, including options to avoid installing dependencies at runtime at all. For more information, see the Amazon SageMaker TFS Container README.
To package a model for TFRecord input data
Re-create your model.tar.gz to contain your new pre-processing script and then create a new Model object pointing to the new model.tar.gz. This step is identical to the previous example for JPEG input data, so refer to that section for details.
To run an Amazon SageMaker batch transform job for TFRecord input data
Now run a batch transform job against TFRecord files that contain the images:
AWS CLI
Amazon SageMaker Python SDK
The command is nearly identical to the one in the previous example for JPEG input data, with a few notable differences:
- You specify SplitType as “TFRecord.” This is the delimiter that Amazon SageMaker batch transform uses. Other supported delimiters are “Line” for newline characters and “RecordIO” for the RecordIO data format.
- You specify BatchStrategy as “SingleRecord” (rather than “MultiRecord”). This means that one record at a time is sent to the model after splitting by the TFRecord delimiter. In this case, choose “SingleRecord” to avoid having to strip records of the TFRecord header in your pre-processing script. If you choose “MultiRecord” instead, each request sent to your model contains up to 1 MB of records (since you chose MaxPayloadInMB to be 1 MB).
- You specify AssembleWith as “Line.” This instructs your batch transform job to assemble the individual predictions in each object by newline characters rather than concatenate them.
- You specify environment variables to be passed to the Amazon SageMaker TFS container. These particular environment variables enable request batching, a TFS feature that allows records from multiple requests to be batched together. The MaxConcurrentTransforms parameter is increased to 100, since TFS queues batches of requests. Request batching is an advanced feature that, when correctly configured, can significantly improve throughput, especially on GPU-enabled instances. For more information on configuring request batching, see the Amazon SageMaker TFS Container
Your S3 input data consisted of 100 objects corresponding to TFRecord files:
Your batch transform job on the images in TFRecord format should finish in about 8 minutes on two ml.p3.2xlarge instances with request batching enabled. Now, your output S3 data path consists of one output object for each of the 100 input objects:
Each object in the output follows the JSONLines format and contains 1000 lines, with each line containing the TFS output for one image:
For each file, the order of the images in the output remains the same as in the input. In other words, the first image in each input file corresponds to the first line in the matching output file, the second image to the second line, and so on.
Conclusion
Amazon SageMaker batch transform can transform large datasets quickly and at scale. You saw how to use the Amazon SageMaker TFS container to perform inferences with GPU-accelerated instances on image data as well as TFRecord files.
While the Amazon SageMaker TFS container supports CSV and JSON data out-of-the-box, its new pre– and post-processing feature also lets you run batch transform jobs on data of any format. The same container can be used for real-time inference as well, using an Amazon SageMaker-hosted model endpoint.
Our example in the blog post text above uses the Open Images dataset. However, we’ve made several examples available to suit your time constraints, use case, and preferred workflow. They are available on GitHub (click the links below) and in SageMaker notebook instances.
- CIFAR-10 example: the CIFAR-10 dataset is much smaller than Open Images, so this example is meant for a quick demonstration of the above features.
- Open Images example, image data: this example uses the Open Images dataset, and performs inference on raw image files. Two versions are available: one uses the SageMaker Python SDK, while the other uses the AWS CLI.
- Open Images example, TFRecord data: this example uses the Open Images dataset, and performs inference on data stored in the TensorFlow binary format, TFRecord. Two versions are available: one uses the SageMaker Python SDK, while the other uses the AWS CLI.
To get started with these examples, go to Amazon SageMaker console, and either create a SageMaker notebook instance or open an existing one. Then go to the SageMaker Examples tab, and select the relevant examples from the SageMaker Batch Transform drop-down menu.
About the Authors
Andre Moeller is a Software Development Engineer at AWS AI. He focuses on developing scalable and reliable platforms and tools to help data scientists and engineers train, evaluate, and deploy machine learning models.
Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.