Artificial Intelligence
Analyze Amazon SageMaker spend and determine cost optimization opportunities based on usage, Part 4: Training jobs
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. Since its introduction, we’ve helped hundreds of customers optimize their workloads, set guardrails, and improve the visibility of their machine learning (ML) workloads’ cost and usage.
In this series of posts, we share lessons learned about optimizing costs in Amazon SageMaker. In this post, we focus on SageMaker training jobs.
Analyze Amazon SageMaker spend and determine cost optimization opportunities based on usage:
|
SageMaker training jobs
SageMaker training jobs are asynchronous batch processes with built-in features for ML model training and optimization.
With SageMaker training jobs, you can bring your own algorithm or choose from more than 25 built-in algorithms. SageMaker supports various data sources and access patterns, distributed training including heterogenous clusters, as well as experiment management features and automatic model tuning.
The cost of a training job is based on the resources you use (instances and storage) for the duration (in seconds) that those instances are running. This includes the time training takes place and, if you’re using the warm pool feature, the keep alive period you configure. In Part 1, we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. You can filter training costs by applying a filter on the usage type. The names of these usage types are as follows:
REGION-Train:instanceType(for example,USE1-Train:ml.m5.large)REGION-Train:VolumeUsage.gp2(for example,USE1-Train:VolumeUsage.gp2)
To view a breakdown of your training costs in Cost Explorer, you can enter train: as a prefix for Usage type. If you filter only for hours used (see the following screenshot), Cost Explorer will generate two graphs: Cost and Usage. This view will help you prioritize your optimization opportunities and identify which instances are long-running and costly.
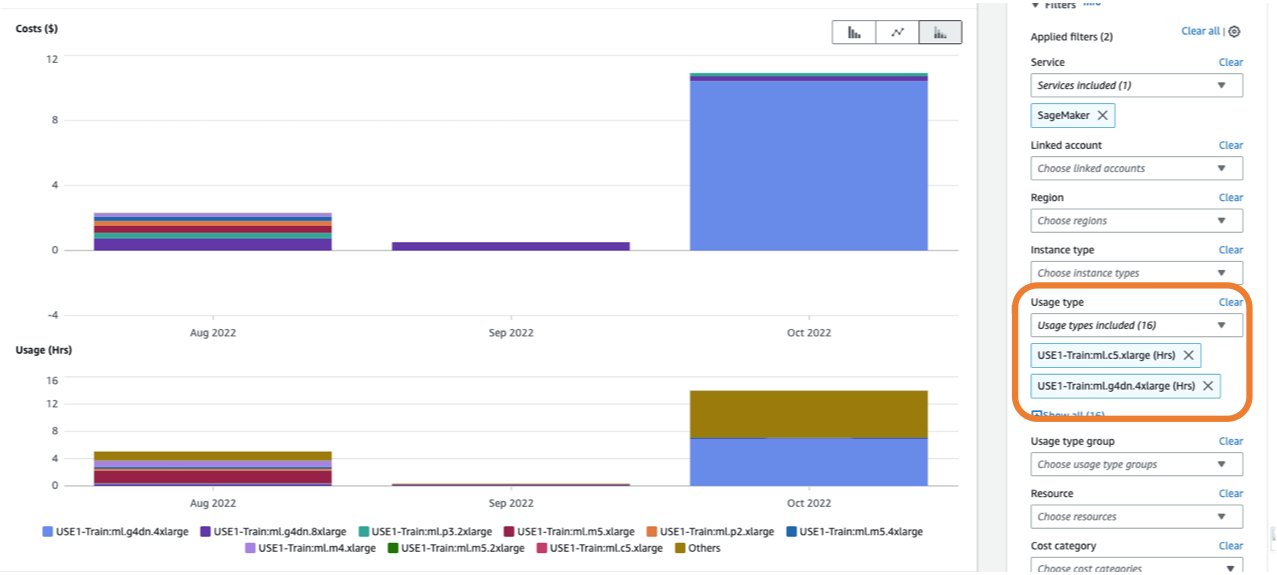
Before optimizing an existing training job, we recommend following the best practices covered in Optimizing costs for machine learning with Amazon SageMaker: test your code locally and use local mode for testing, use pre-trained models where possible, and consider managed spot training (which can optimize cost up to 90% over On-Demand instances).
When an On-Demand job is launched, it goes through five phases: Starting, Downloading, Training, Uploading, and Completed. You can see those phases and descriptions on the training job’s page on the SageMaker console.
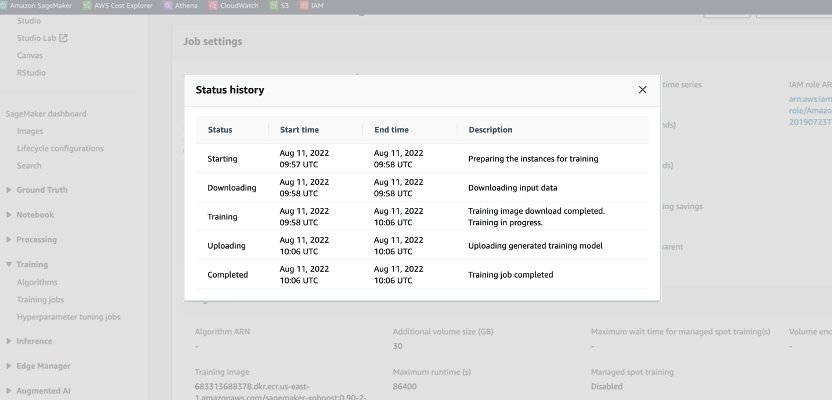
From a pricing perspective, you are charged for Downloading, Training, and Uploading phases.
Reviewing these phases is a first step in diagnosing where to optimize your training costs. In this post, we discuss the Downloading and Training phases.
Downloading phase
In the preceding example, the Downloading phase took less than a minute. However, if data downloading is a big factor of your training cost, you should consider the data source you are using and access methods. SageMaker training jobs support three data sources natively: Amazon Elastic File System (Amazon EFS), Amazon Simple Storage Service (Amazon S3), and Amazon FSx for Lustre. For Amazon S3, SageMaker offers three managed ways that your algorithm can access the training: File mode (where data is downloaded to the instance block storage), Pipe mode (data is streamed to the instance, thereby eliminating the duration of the Downloading phase) and Fast File mode (combines the ease of use of the existing File mode with the performance of Pipe mode). For detailed guidance on choosing the right data source and access methods, refer to Choose the best data source for your Amazon SageMaker training job.
When using managed spot training, any repeated Downloading phases that occurred due to interruption are not charged (so you’re only charged for the duration of the data download one time).
It’s important to note that although SageMaker training jobs support the data sources we mentioned, they are not mandatory. In your training code, you can implement any method for downloading the training data from any source (provided that the training instance can access it). There are additional ways to speed up download time, such as using the Boto3 API with multiprocessing to download files concurrently, or using third-party libraries such as WebDataset or s5cmd for faster download from Amazon S3. For more information, refer to Parallelizing S3 Workloads with s5cmd.
Training phase
Optimizing the Training phase cost consists of optimizing two vectors: choosing the right infrastructure (instance family and size), and optimizing the training itself. We can roughly divide training instances into two categories: accelerated GPU-based, mostly for deep-learning models, and CPU-based for common ML frameworks. For guidance on selecting the right instance family for training, refer to Ensure efficient compute resources on Amazon SageMaker. If your training requires GPUs instances, we recommend referring to the video How to select Amazon EC2 GPU instances for deep learning.
As a general guidance, if your workload does require an NVIDIA GPU, we found customers gain significant cost savings with two Amazon Elastic Compute Cloud (Amazon EC2) instance types: ml.g4dn and ml.g5. The ml.g4dn is equipped with NVIDIA T4 and offers a particularly low cost per memory. The ml.g5 instance is equipped with NVIDIA A10g Tensor Core and has the lowest cost-per-CUDA flop (fp32).
AWS offers specific cost saving features for deep learning training:
- Amazon SageMaker Training Compiler, which implements optimizations to reduce training time on GPU instances
- Trn1 instances, powered by AWS Trainium accelerators, which are purpose built for high-performance training while offering up to 50% cost-to-train savings over comparable GPU-based instances
In order to right-size and optimize your instance, you should first look at the Amazon CloudWatch metrics the training jobs are generating. For more information, refer to SageMaker Jobs and Endpoint Metrics. You can further use CloudWatch custom algorithm metrics to monitor the training performance.
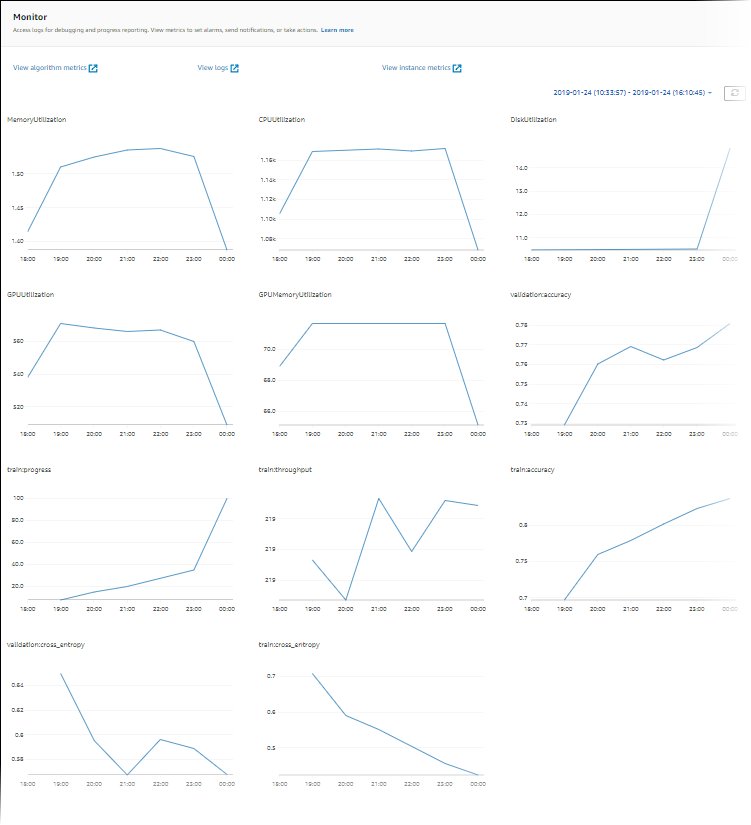
These metrics can indicate bottlenecks or over-provisioning of resources. For example, if you’re observing high CPU with low GPU utilizations, you can address the issue by using heterogeneous clusters. Another example can be seeing consistent low CPU utilization throughout the job duration—this can lead to reducing the size of the instance.
If you’re using distributed training, you should test different distribution methods (tower, Ring-AllReduce, mirrored, and so on) to validate maximum utilization and fine-tune your framework parameters accordingly (for an example, see Best practices for TensorFlow 1.x acceleration training on Amazon SageMaker). It’s important to highlight that you can use the SageMaker distribution API and libraries like SageMaker Distributed Data Parallel, SageMaker Model Parallel, and SageMaker Sharded Data Parallel, which are optimized for AWS infrastructure and help reduce training costs.
Note that distributed training doesn’t necessarily scale linearly and might introduce some overhead, which will affect the overall runtime.
For deep learning models, another optimization technique is using mixed precision. Mixed precision can speed up training, thereby reducing both training time and memory usage with minimal to no impact on model accuracy. For more information, see the Train with Data Parallel and Model Parallel section in Distributed Training in Amazon SageMaker.
Finally, optimizing framework-specific parameters can have a significant impact in optimizing the training process. SageMaker automatic model tuning finds hyperparameters that perform the best, as measured by an objective metric that you choose. Setting the training time as an objective metric and framework configuration as hyperparameters can help remove bottlenecks and reduce overall training time. For an example of optimizing the default TensorFlow settings and removing a CPU bottleneck, refer to Aerobotics improves training speed by 24 times per sample with Amazon SageMaker and TensorFlow.
Another opportunity for optimizing both download and processing time is to consider training on a subset of your data. If your data consists of multiple duplicate entries or features with low information gain, you might be able to train on a subset of data and reduce downloading and training time as well as use a smaller instance and Amazon Elastic Block Store (Amazon EBS) volume. For an example, refer to Use a data-centric approach to minimize the amount of data required to train Amazon SageMaker models. Also, Amazon SageMaker Data Wrangler can simplify the analysis and creation of training samples. For more information, refer to Create random and stratified samples of data with Amazon SageMaker Data Wrangler.
SageMaker Debugger
To ensure efficient training and resource utilization, SageMaker can profile your training job using Amazon SageMaker Debugger. Debugger offers built-in rules to alert on common issues that are affecting your training like CPU bottleneck, GPU memory increase, or I/O bottleneck, or you can create your own rules. You can access and analyze the generated report in Amazon SageMaker Studio. For more information, refer to Amazon SageMaker Debugger UI in Amazon SageMaker Studio Experiments. The following screenshot shows the Debugger view in Studio.
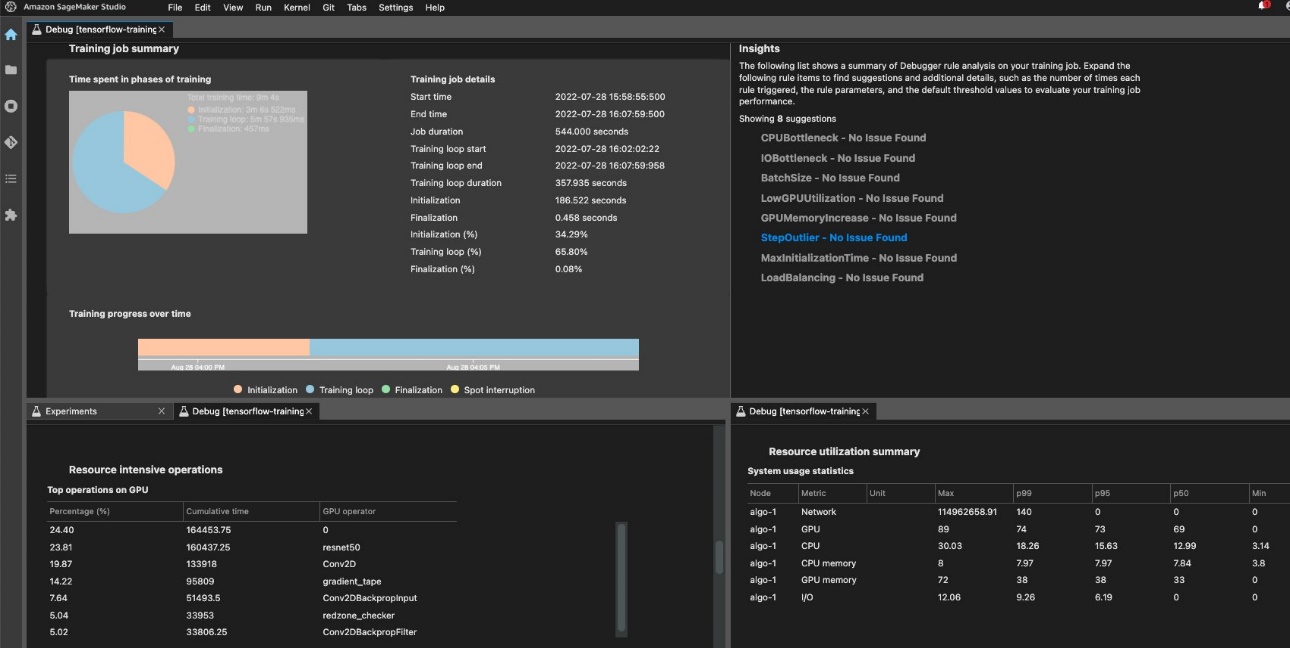
You can drill down into the Python operators and functions (the Top operations on GPU section) that are run to perform the training job. The Debugger built-in rules for profiling watch framework operation-related issues, including excessive training initialization time due to data downloading before training starts and step duration outliers in training loops. You should note that although using the built-in rules are free, costs for custom rules apply based on the instance that you configure for the duration of the training job and storage that is attached to it.
Conclusion
In this post, we provided guidance on cost analysis and best practices when training ML models using SageMaker training jobs. As machine learning establishes itself as a powerful tool across industries, training and running ML models needs to remain cost-effective. SageMaker offers a wide and deep feature set for facilitating each step in the ML pipeline and provides cost optimization opportunities without impacting performance or agility.
Refer to the following posts in this series for more information about optimizing cost for SageMaker:
|
About the Authors
 Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise customers providing technical guidance with best practices for deploying and maintaining AI/ML solutions in the AWS ecosystem. She has worked with a wide range of organizations on various deep learning use cases involving NLP and computer vision. She is passionate about empowering organizations to leverage generative AI to enhance their use experience. In her spare time, she enjoys movies, music, and literature.
Deepali Rajale is a Senior AI/ML Specialist at AWS. She works with enterprise customers providing technical guidance with best practices for deploying and maintaining AI/ML solutions in the AWS ecosystem. She has worked with a wide range of organizations on various deep learning use cases involving NLP and computer vision. She is passionate about empowering organizations to leverage generative AI to enhance their use experience. In her spare time, she enjoys movies, music, and literature.
 Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. Based out of Israel, Uri works to empower enterprise customers on all things ML to design, build, and operate at scale. In his spare time, he enjoys cycling, hiking, and increasing entropy.
Uri Rosenberg is the AI & ML Specialist Technical Manager for Europe, Middle East, and Africa. Based out of Israel, Uri works to empower enterprise customers on all things ML to design, build, and operate at scale. In his spare time, he enjoys cycling, hiking, and increasing entropy.