AWS Machine Learning Blog

Implement backup and recovery using an event-driven serverless architecture with Amazon SageMaker Studio
Amazon SageMaker Studio is the first fully integrated development environment (IDE) for ML. It provides a single, web-based visual interface where you can perform all machine learning (ML) development steps required to build, train, tune, debug, deploy, and monitor models. It gives data scientists all the tools you need to take ML models from experimentation […]

How Vericast optimized feature engineering using Amazon SageMaker Processing
This post is co-written by Jyoti Sharma and Sharmo Sarkar from Vericast. For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. […]

Hosting ML Models on Amazon SageMaker using Triton: XGBoost, LightGBM, and Treelite Models
One of the most popular models available today is XGBoost. With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. In this post, we dive deep to see how Amazon SageMaker can serve these models using NVIDIA Triton […]

Bring your own ML model into Amazon SageMaker Canvas and generate accurate predictions
Machine learning (ML) helps organizations generate revenue, reduce costs, mitigate risk, drive efficiencies, and improve quality by optimizing core business functions across multiple business units such as marketing, manufacturing, operations, sales, finance, and customer service. With AWS ML, organizations can accelerate the value creation from months to days. Amazon SageMaker Canvas is a visual, point-and-click […]
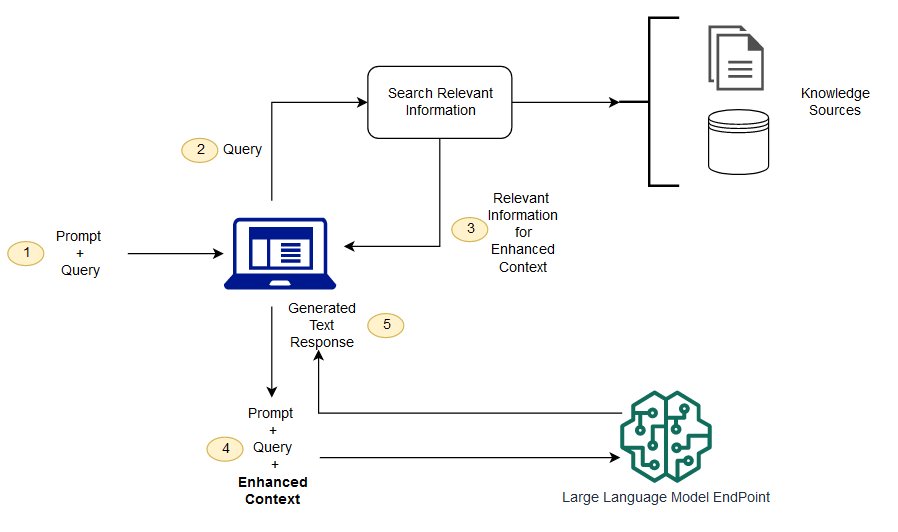
Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart
Today, we announce the availability of sample notebooks that demonstrate question answering tasks using a Retrieval Augmented Generation (RAG)-based approach with large language models (LLMs) in Amazon SageMaker JumpStart. Text generation using RAG with LLMs enables you to generate domain-specific text outputs by supplying specific external data as part of the context fed to LLMs. […]

Prepare image data with Amazon SageMaker Data Wrangler
The rapid adoption of smart phones and other mobile platforms has generated an enormous amount of image data. According to Gartner, unstructured data now represents 80–90% of all new enterprise data, but just 18% of organizations are taking advantage of this data. This is mainly due to a lack of expertise and the large amount […]

Improve multi-hop reasoning in LLMs by learning from rich human feedback
Recent large language models (LLMs) have enabled tremendous progress in natural language understanding. However, they are prone to generating confident but nonsensical explanations, which poses a significant obstacle to establishing trust with users. In this post, we show how to incorporate human feedback on the incorrect reasoning chains for multi-hop reasoning to improve performance on […]

How to extend the functionality of AWS Trainium with custom operators
Deep learning (DL) is a fast-evolving field, and practitioners are constantly innovating DL models and inventing ways to speed them up. Custom operators are one of the mechanisms developers use to push the boundaries of DL innovation by extending the functionality of existing machine learning (ML) frameworks such as PyTorch. In general, an operator describes […]

Deliver your first ML use case in 8–12 weeks
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? You’re not alone. Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. This post describes how to implement your first ML use case using Amazon […]

Run your local machine learning code as Amazon SageMaker Training jobs with minimal code changes
We recently introduced a new capability in the Amazon SageMaker Python SDK that lets data scientists run their machine learning (ML) code authored in their preferred integrated developer environment (IDE) and notebooks along with the associated runtime dependencies as Amazon SageMaker training jobs with minimal code changes to the experimentation done locally. Data scientists typically […]