Artificial Intelligence
Serverless deployment for your Amazon SageMaker Canvas models
In this post, we walk through how to take an ML model built in SageMaker Canvas and deploy it using SageMaker Serverless Inference, helping you go from model creation to production-ready predictions quickly and efficiently without managing any infrastructure. This solution demonstrates a complete workflow from adding your trained model to the SageMaker Model Registry through creating serverless endpoint configurations and deploying endpoints that automatically scale based on demand .
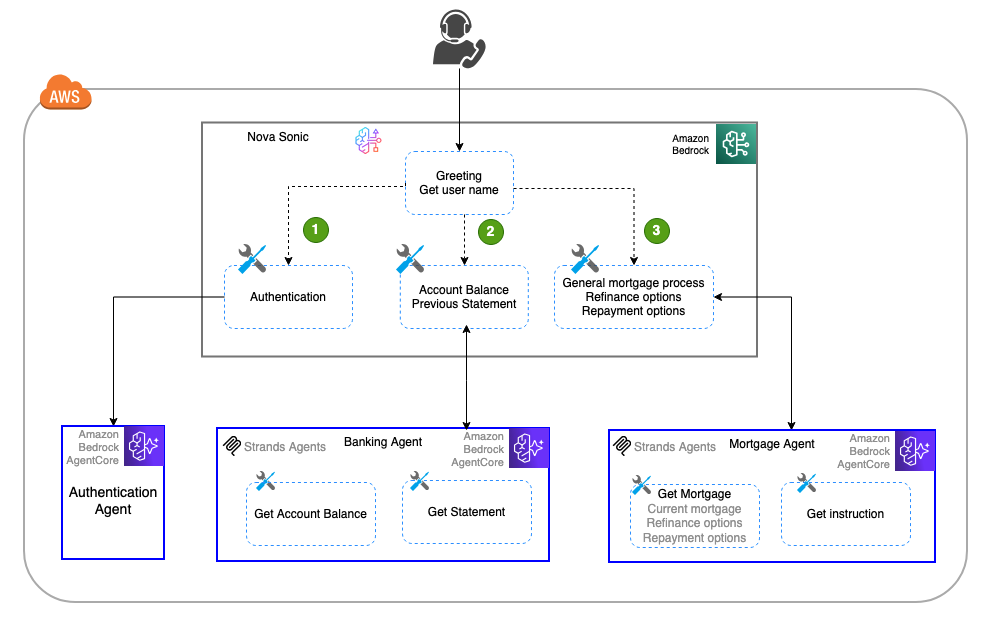
Building a multi-agent voice assistant with Amazon Nova Sonic and Amazon Bedrock AgentCore
In this post, we explore how Amazon Nova Sonic’s speech-to-speech capabilities can be combined with Amazon Bedrock AgentCore to create sophisticated multi-agent voice assistants that break complex tasks into specialized, manageable components. The approach demonstrates how to build modular, scalable voice applications using a banking assistant example with dedicated sub-agents for authentication, banking inquiries, and mortgage services, offering a more maintainable alternative to monolithic voice assistant designs.
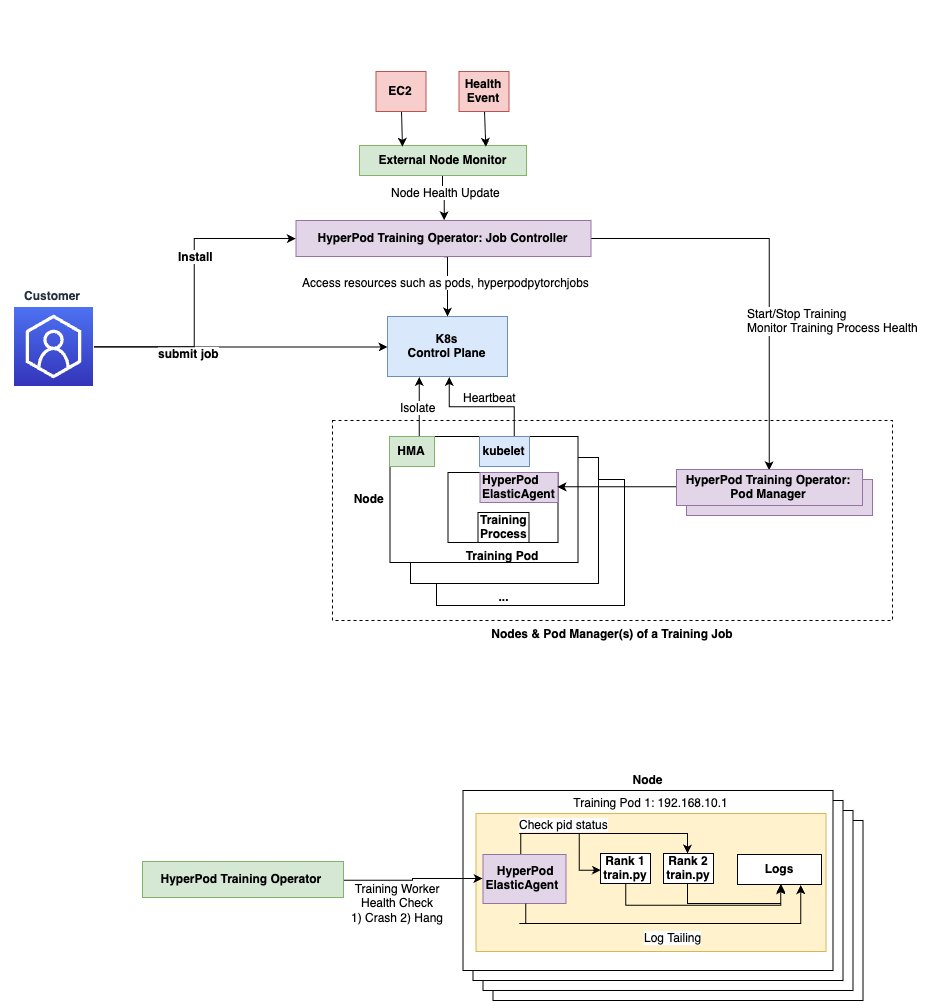
Accelerate large-scale AI training with Amazon SageMaker HyperPod training operator
In this post, we demonstrate how to deploy and manage machine learning training workloads using the Amazon SageMaker HyperPod training operator, which enhances training resilience for Kubernetes workloads through pinpoint recovery and customizable monitoring capabilities. The Amazon SageMaker HyperPod training operator helps accelerate generative AI model development by efficiently managing distributed training across large GPU clusters, offering benefits like centralized training process monitoring, granular process recovery, and hanging job detection that can reduce recovery times from tens of minutes to seconds.
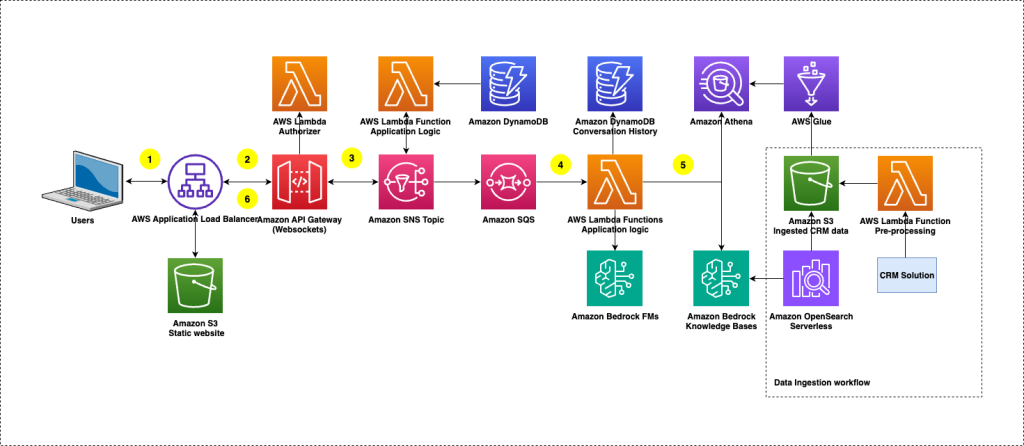
How TP ICAP transformed CRM data into real-time insights with Amazon Bedrock
This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value.
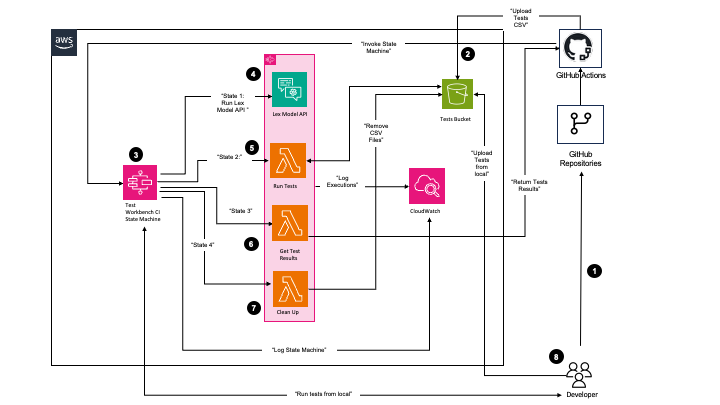
Principal Financial Group accelerates build, test, and deployment of Amazon Lex V2 bots through automation
In the post Principal Financial Group increases Voice Virtual Assistant performance using Genesys, Amazon Lex, and Amazon QuickSight, we discussed the overall Principal Virtual Assistant solution using Genesys Cloud, Amazon Lex V2, multiple AWS services, and a custom reporting and analytics solution using Amazon QuickSight.
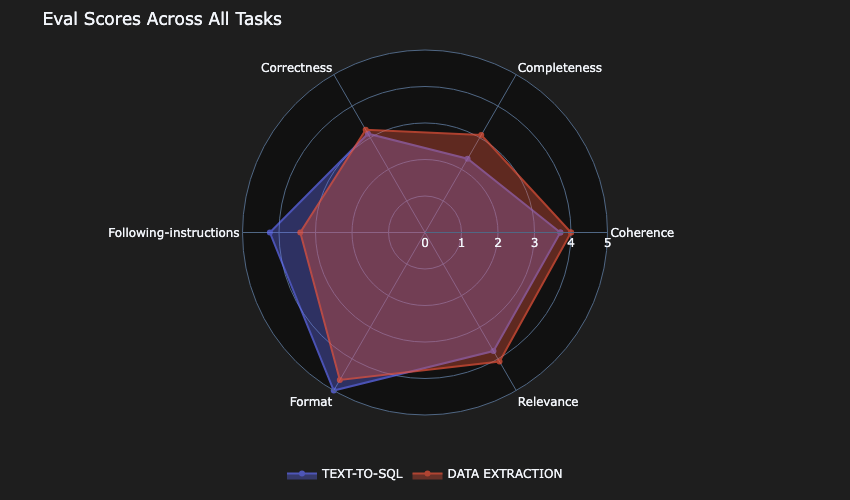
Beyond vibes: How to properly select the right LLM for the right task
In this post, we discuss an approach that can guide you to build comprehensive and empirically driven evaluations that can help you make better decisions when selecting the right model for your task.

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.

Iterative fine-tuning on Amazon Bedrock for strategic model improvement
Organizations often face challenges when implementing single-shot fine-tuning approaches for their generative AI models. The single-shot fine-tuning method involves selecting training data, configuring hyperparameters, and hoping the results meet expectations without the ability to make incremental adjustments. Single-shot fine-tuning frequently leads to suboptimal results and requires starting the entire process from scratch when improvements are […]

Voice AI-powered drive-thru ordering with Amazon Nova Sonic and dynamic menu displays
In this post, we’ll demonstrate how to implement a Quick Service Restaurants (QSRs) drive-thru solution using Amazon Nova Sonic and AWS services. We’ll walk through building an intelligent system that combines voice AI with interactive menu displays, providing technical insights and implementation guidance to help restaurants modernize their drive-thru operations.
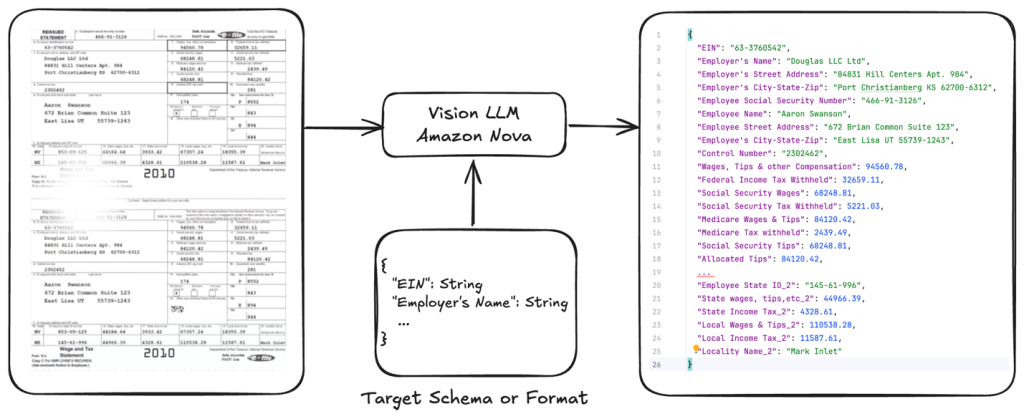
Optimizing document AI and structured outputs by fine-tuning Amazon Nova Models and on-demand inference
This post provides a comprehensive hands-on guide to fine-tune Amazon Nova Lite for document processing tasks, with a focus on tax form data extraction. Using our open-source GitHub repository code sample, we demonstrate the complete workflow from data preparation to model deployment.