AWS Machine Learning Blog
Intuitivo achieves higher throughput while saving on AI/ML costs using AWS Inferentia and PyTorch
This is a guest post by Jose Benitez, Founder and Director of AI and Mattias Ponchon, Head of Infrastructure at Intuitivo.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. This groundbreaking technology enables us to operate millions of autonomous points of purchase (A-POPs) concurrently, transforming the way customers shop. Our solution outpaces traditional vending machines and alternatives, offering an economical edge with its ten times cheaper cost, easy setup, and maintenance-free operation. Our innovative new A-POPs (or vending machines) deliver enhanced customer experiences at ten times lower cost because of the performance and cost advantages AWS Inferentia delivers. Inferentia has enabled us to run our You Only Look Once (YOLO) computer vision models five times faster than our previous solution and supports seamless, real-time shopping experiences for our customers. Additionally, Inferentia has also helped us reduce costs by 95 percent compared to our previous solution. In this post, we cover our use case, challenges, and a brief overview of our solution using Inferentia.
The changing retail landscape and need for A-POP
The retail landscape is evolving rapidly, and consumers expect the same easy-to-use and frictionless experiences they are used to when shopping digitally. To effectively bridge the gap between the digital and physical world, and to meet the changing needs and expectations of customers, a transformative approach is required. At Intuitivo, we believe that the future of retail lies in creating highly personalized, AI-powered, and computer vision-driven autonomous points of purchase (A-POP). This technological innovation brings products within arm’s reach of customers. Not only does it put customers’ favorite items at their fingertips, but it also offers them a seamless shopping experience, devoid of long lines or complex transaction processing systems. We’re excited to lead this exciting new era in retail.
With our cutting-edge technology, retailers can quickly and efficiently deploy thousands of A-POPs. Scaling has always been a daunting challenge for retailers, mainly due to the logistic and maintenance complexities associated with expanding traditional vending machines or other solutions. However, our camera-based solution, which eliminates the need for weight sensors, RFID, or other high-cost sensors, requires no maintenance and is significantly cheaper. This enables retailers to efficiently establish thousands of A-POPs, providing customers with an unmatched shopping experience while offering retailers a cost-effective and scalable solution.

Using cloud inference for real-time product identification
While designing a camera-based product recognition and payment system, we ran into a decision of whether this should be done on the edge or the cloud. After considering several architectures, we designed a system that uploads videos of the transactions to the cloud for processing.
Our end users start a transaction by scanning the A-POP’s QR code, which triggers the A-POP to unlock and then customers grab what they want and go. Preprocessed videos of these transactions are uploaded to the cloud. Our AI-powered transaction pipeline automatically processes these videos and charges the customer’s account accordingly.
The following diagram shows the architecture of our solution.
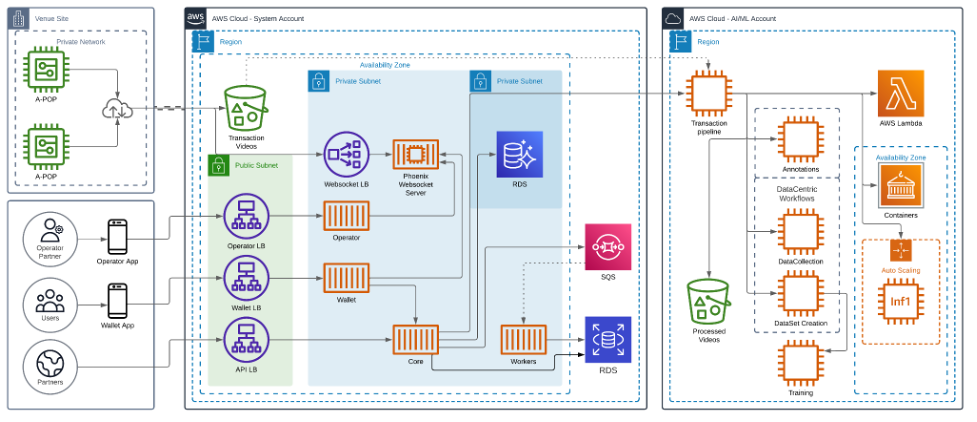
Unlocking high-performance and cost-effective inference using AWS Inferentia
As retailers look to scale operations, cost of A-POPs becomes a consideration. At the same time, providing a seamless real-time shopping experience for end-users is paramount. Our AI/ML research team focuses on identifying the best computer vision (CV) models for our system. We were now presented with the challenge of how to simultaneously optimize the AI/ML operations for performance and cost.
We deploy our models on Amazon EC2 Inf1 instances powered by Inferentia, Amazon’s first ML silicon designed to accelerate deep learning inference workloads. Inferentia has been shown to reduce inference costs significantly. We used the AWS Neuron SDK—a set of software tools used with Inferentia—to compile and optimize our models for deployment on EC2 Inf1 instances.
The code snippet that follows shows how to compile a YOLO model with Neuron. The code works seamlessly with PyTorch and functions such as torch.jit.trace()and neuron.trace()record the model’s operations on an example input during the forward pass to build a static IR graph.
We migrated our compute-heavy models to Inf1. By using AWS Inferentia, we achieved the throughput and performance to match our business needs. Adopting Inferentia-based Inf1 instances in the MLOps lifecycle was a key to achieving remarkable results:
- Performance improvement: Our large computer vision models now run five times faster, achieving over 120 frames per second (FPS), allowing for seamless, real-time shopping experiences for our customers. Furthermore, the ability to process at this frame rate not only enhances transaction speed, but also enables us to feed more information into our models. This increase in data input significantly improves the accuracy of product detection within our models, further boosting the overall efficacy of our shopping systems.
- Cost savings: We slashed inference costs. This significantly enhanced the architecture design supporting our A-POPs.
Data parallel inference was easy with AWS Neuron SDK
To improve performance of our inference workloads and extract maximum performance from Inferentia, we wanted to use all available NeuronCores in the Inferentia accelerator. Achieving this performance was easy with the built-in tools and APIs from the Neuron SDK. We used the torch.neuron.DataParallel() API. We’re currently using inf1.2xlarge which has one Inferentia accelerator with four Neuron accelerators. So we’re using torch.neuron.DataParallel() to fully use the Inferentia hardware and use all available NeuronCores. This Python function implements data parallelism at the module level on models created by the PyTorch Neuron API. Data parallelism is a form of parallelization across multiple devices or cores (NeuronCores for Inferentia), referred to as nodes. Each node contains the same model and parameters, but data is distributed across the different nodes. By distributing the data across multiple nodes, data parallelism reduces the total processing time of large batch size inputs compared to sequential processing. Data parallelism works best for models in latency-sensitive applications that have large batch size requirements.
Looking ahead: Accelerating retail transformation with foundation models and scalable deployment
As we venture into the future, the impact of foundation models on the retail industry cannot be overstated. Foundation models can make a significant difference in product labeling. The ability to quickly and accurately identify and categorize different products is crucial in a fast-paced retail environment. With modern transformer-based models, we can deploy a greater diversity of models to serve more of our AI/ML needs with higher accuracy, improving the experience for users and without having to waste time and money training models from scratch. By harnessing the power of foundation models, we can accelerate the process of labeling, enabling retailers to scale their A-POP solutions more rapidly and efficiently.
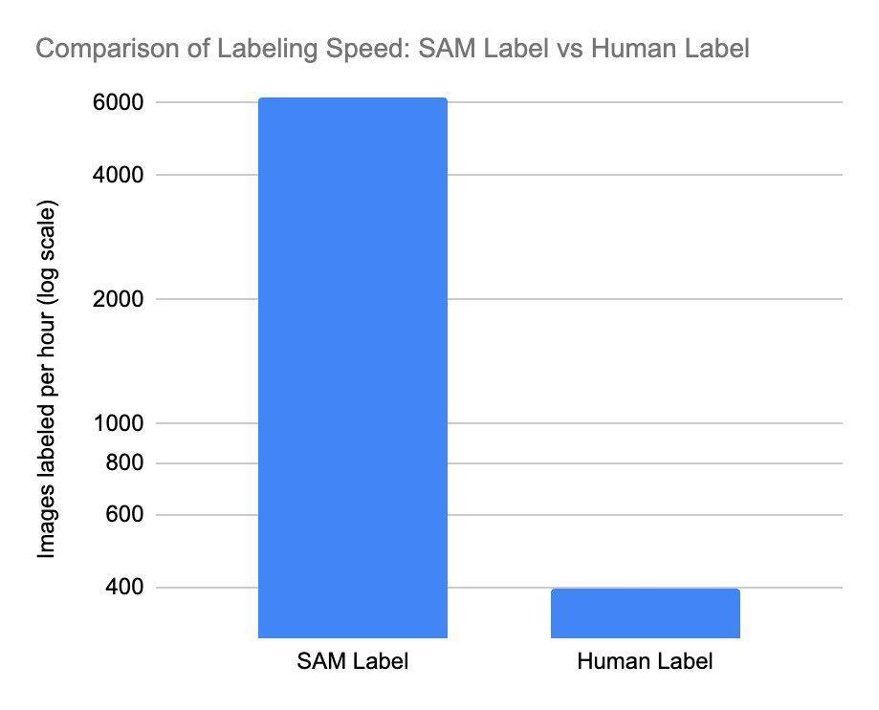
We have begun implementing Segment Anything Model (SAM), a vision transformer foundation model that can segment any object in any image (we will discuss this further in another blog post). SAM allows us to accelerate our labeling process with unparalleled speed. SAM is very efficient, able to process approximately 62 times more images than a human can manually create bounding boxes for in the same timeframe. SAM’s output is used to train a model that detects segmentation masks in transactions, opening up a window of opportunity for processing millions of images exponentially faster. This significantly reduces training time and cost for product planogram models.
Our product and AI/ML research teams are excited to be at the forefront of this transformation. The ongoing partnership with AWS and our use of Inferentia in our infrastructure will ensure that we can deploy these foundation models cost effectively. As early adopters, we’re working with the new AWS Inferentia 2-based instances. Inf2 instances are built for today’s generative AI and large language model (LLM) inference acceleration, delivering higher performance and lower costs. Inf2 will enable us to empower retailers to harness the benefits of AI-driven technologies without breaking the bank, ultimately making the retail landscape more innovative, efficient, and customer-centric.
As we continue to migrate more models to Inferentia and Inferentia2, including transformers-based foundational models, we are confident that our alliance with AWS will enable us to grow and innovate alongside our trusted cloud provider. Together, we will reshape the future of retail, making it smarter, faster, and more attuned to the ever-evolving needs of consumers.
Conclusion
In this technical traverse, we’ve highlighted our transformational journey using AWS Inferentia for its innovative AI/ML transactional processing system. This partnership has led to a five times increase in processing speed and a stunning 95 percent reduction in inference costs compared to our previous solution. It has changed the current approach of the retail industry by facilitating a real-time and seamless shopping experience.
If you’re interested in learning more about how Inferentia can help you save costs while optimizing performance for your inference applications, visit the Amazon EC2 Inf1 instances and Amazon EC2 Inf2 instances product pages. AWS provides various sample codes and getting started resources for Neuron SDK that you can find on the Neuron samples repository.
About the Authors
Matias Ponchon is the Head of Infrastructure at Intuitivo. He specializes in architecting secure and robust applications. With extensive experience in FinTech and Blockchain companies, coupled with his strategic mindset, helps him to design innovative solutions. He has a deep commitment to excellence, that’s why he consistently delivers resilient solutions that push the boundaries of what’s possible.
Jose Benitez is the Founder and Director of AI at Intuitivo, specializing in the development and implementation of computer vision applications. He leads a talented Machine Learning team, nurturing an environment of innovation, creativity, and cutting-edge technology. In 2022, Jose was recognized as an ‘Innovator Under 35’ by MIT Technology Review, a testament to his groundbreaking contributions to the field. This dedication extends beyond accolades and into every project he undertakes, showcasing a relentless commitment to excellence and innovation.
Diwakar Bansal is an AWS Senior Specialist focused on business development and go-to-market for Gen AI and Machine Learning accelerated computing services. Previously, Diwakar has led product definition, global business development, and marketing of technology products for IoT, Edge Computing, and Autonomous Driving focusing on bringing AI and Machine Learning to these domains.