AWS Machine Learning Blog
Incremental learning: Optimizing search relevance at scale using machine learning
Amazon Kendra is releasing incremental learning to automatically improve search relevance and make sure you can continuously find the information you’re looking for, particularly when search patterns and document trends change over time.
Data proliferation is real, and it’s growing. In fact, International Data Corporation (IDC) predicts that 80% of all data will be unstructured by 2025. However, mining data for accurate answers continues to be a challenge for many organizations. In an uncertain business environment there is mounting pressure find relevant information quickly, and use it to sustain and enhance business performance.
Organizations need solutions that deliver accurate answers fast and evolve the process of knowledge discovery from being a painstaking chore that typically results in dead ends, into a delightful experience for customers and employees.
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra has reimagined enterprise search for your websites and applications so employees and customers can easily find what they’re looking for, even when answers could be scattered across multiple locations and content repositories within your organization.

Intelligent search helps you consolidate unstructured data from across your business into a single, secure, and searchable index. However, data ingestion and data source consolidation is just one aspect of upgrading a conventional search solution to a ML-powered intelligent search solution.
A more unique aspect of intelligent search is its ability to deliver relevant answers without the tuning complexities typically needed for keyword-based engines. Amazon Kendra’s deep learning language models and algorithms deliver accuracy out of the box, and automatically tune search relevance on a continuous basis.
Continuous improvement
A large part of this is incremental learning, which now comes built-in to Amazon Kendra. Incremental learning creates a mechanism for Amazon Kendra to observe user activity, search patterns, and user interactions. Amazon Kendra then uses these fundamentally important data points to understand user preferences for various documents and answers so it can take action and optimize search results. For example, the following screenshot shows how users can rate how helpful a search result is.
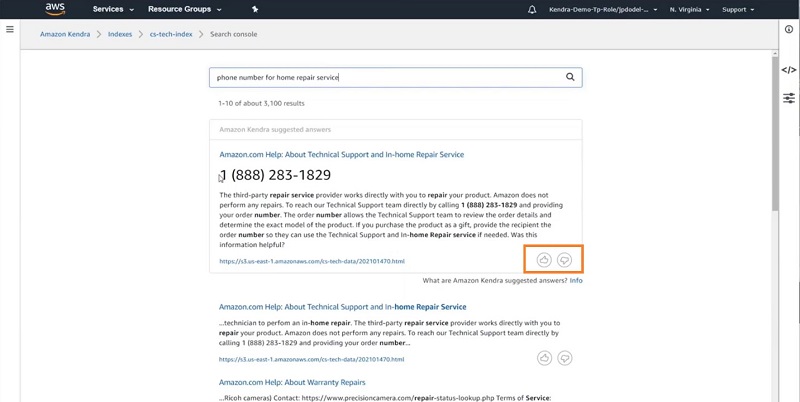
In addition to capturing explicit feedback from users, Kendra can capture the implicit feedback derived from the clickthrough data which provides much higher volumes of useful signals to understand trends and preferences.
For example, if an employee performs a search “What is our company expense policy?” without being specific about what kind of expense policy they’re interested in, they may see a host of varying topics. Their results could include “airfare policies,” “hotels and accommodation,” or meals and entertainment policy,” and although each topic is technically related to company expense policy, the most commonly sought document may not necessarily be at the top of the list.
However, if it turns out that when employees typically ask that question, they’re searching for content related to “home-office reimbursements,” Amazon Kendra can learn from how users interact with results (clicks on page) and adapt its models to re-rank information so “home-office expense policy” content gets promoted at the top of the search results page in future searches.
Scaling lessons learned
Incremental learning autonomously optimizes search results over time without the need to develop, train, and deploy ML models. It tunes future search results quickly in a way that’s data-driven and cost effective.
Consider the process for optimizing search accuracy in non-ML powered solutions, it would require significant effort, machine learning skill, and maintenance, even when using “ML” plugins added on top of legacy engines.
As unstructured data continues to dominate and grow at exponential speeds within the enterprise, implementing an adaptive, intelligent, and nimble enterprise search solution becomes critical to keeping up with the pace of change.
Conclusion
To learn more about how organizations are using intelligent search to boost workforce productivity, accelerate research and development, and enhance customer experiences download our ebook, 7 Reasons Why Your Organization Needs Intelligent Search. For more information about incremental learning, see Submitting feedback, or to learn more about Amazon Kendra visit the website or you can watch this video “What is Intelligent Search?”
About the Authors
 Jean-Pierre Dodel leads product management for Amazon Kendra, a new ML-powered enterprise search service from AWS. He brings 15 years of Enterprise Search and ML solutions experience to the team, having worked at Autonomy, HP, and search startups for many years prior to joining Amazon 4 years ago. JP has led the Kendra team from its inception, defining vision, roadmaps, and delivering transformative semantic search capabilities to customers like Dow Jones, Liberty Mutual, 3M, and PwC.
Jean-Pierre Dodel leads product management for Amazon Kendra, a new ML-powered enterprise search service from AWS. He brings 15 years of Enterprise Search and ML solutions experience to the team, having worked at Autonomy, HP, and search startups for many years prior to joining Amazon 4 years ago. JP has led the Kendra team from its inception, defining vision, roadmaps, and delivering transformative semantic search capabilities to customers like Dow Jones, Liberty Mutual, 3M, and PwC.
 Tom McMahon is a Product Marketing Manager on the AI Services team at AWS. He’s passionate about technology and storytelling and has spent time across a wide-range of industries including healthcare, retail, logistics, and eCommerce. In his spare time he enjoys spending time with family, music, playing golf, and exploring the amazing Pacific northwest and its surrounds.
Tom McMahon is a Product Marketing Manager on the AI Services team at AWS. He’s passionate about technology and storytelling and has spent time across a wide-range of industries including healthcare, retail, logistics, and eCommerce. In his spare time he enjoys spending time with family, music, playing golf, and exploring the amazing Pacific northwest and its surrounds.