AWS Machine Learning Blog
Create a large-scale video driving dataset with detailed attributes using Amazon SageMaker Ground Truth
Do you ever wonder what goes behind bringing various levels of autonomy to vehicles? What the vehicle sees (perception) and how the vehicle predicts the actions of different agents in the scene (behavior prediction) are the first two steps in autonomous systems. In order for these steps to be successful, large-scale driving datasets are key. Driving datasets typically comprise of data captured using multiple sensors such as cameras, LIDARs, radars, and GPS, in a variety of traffic scenarios during different times of the day under varied weather conditions and locations. The Amazon Machine Learning Solutions Lab is collaborating with the Laboratory of Intelligent and Safe Automobiles (LISA Lab) at the University of California, San Diego (UCSD) to build a large, richly annotated, real-world driving dataset with fine-grained vehicle, pedestrian, and scene attributes.
This post describes the dataset label taxonomy and labeling architecture for 2D bounding boxes using Amazon SageMaker Ground Truth. Ground Truth is a fully managed data labeling service that makes it easy to build highly accurate training datasets for machine learning (ML) workflows. These workflows support a variety of use cases, including 3D point clouds, video, images, and text. As part of the workflows, labelers have access to assistive labeling features such as automatic 3D cuboid snapping, removal of distortion in 2D images, and auto-segment tools to reduce the time required to label datasets. In addition, Ground Truth offers automatic data labeling, which uses an ML model to label your data.
LISA Amazon-MLSL Vehicle Attributes (LAVA) dataset
LAVA is a diverse, large-scale dataset with a unique label set that we created to provide high-quality labeled video data for a variety of modern computer vision applications in the automotive domain. We captured the data using rigidly mounted cameras with a 1/2.3” sensor size and f/2.8 aperture at 1920×1080 resolution. The chosen aperture, sensor size, and focal length between 1 to 20 meters results in a depth-of-field extending up to infinity, which means most objects on the road are in-focus. We augmented the data with additional navigation sensors that provide centimeter-level localization accuracy and inertial motion information. We collected the data during real-world drives in Southern California under different illumination, weather, traffic, and road conditions to capture the complexity and diversity of real-world vehicle operation. This, put together with our unique set of annotations, allowed us to develop reliable ML models for existing automotive applications, and new ones that were previously unfeasible due to the lack of high-quality labeled data.
From the hundreds of hours of raw data captured during our many data collection drives, we first processed and curated 10-second segments of video data for inclusion into the LAVA dataset. We curated the 10-second video clips manually to identify “interesting” clips, such as those with high vehicle/pedestrian activity, intersections, and maneuvers such as lane changes. We selected these clips based on their uniqueness in comparison to existing clips in the dataset, and their overall value to the training of ML models for different tasks. After we curated the clips, we processed them to remove distortion and compressed them for easy sharing and playback. We then sent these clips for labeling according the established taxonomy.
In this post, we describe our taxonomy, motivation behind the design of the taxonomy and how we map the taxonomy to Ground Truth labeling jobs to create a labeling pipeline that produces high-quality annotations quickly while still being flexible to changes in labeling priorities.

LAVA dataset taxonomy
The following code illustrates our LAVA dataset taxonomy:
The labeling taxonomy consists of a hierarchical structure with drive-level attributes at the very top. These attributes include properties that are applicable to an entire data collection drive, such as weather, route, or time of day.
Below the drive-level attributes are clip-level attributes, which correspond to the 10-second video segments that make up the dataset. These clip-level attributes inherit drive-level attributes from the parent drive, and also contain additional fields such as scene, traffic density, and traffic flow. This allows users to assign fine-grained labels to each individual clip in the dataset, and also enables users to conduct experiments that measure how models perform under very specific scene, traffic, or weather conditions. This kind of analysis is extremely valuable to gauge the readiness and shortcomings of models prior to real-world deployment, and isn’t as easily achievable in other popular datasets.
Below clip-level attributes are the frame-level attributes at the bottom of the labeling hierarchy, which correspond to each frame in the 10-second video segment. As before, the frame-level attributes inherit from clip-level attributes (and indirectly from drive-level attributes), and additionally contain fields that correspond to the locations and properties of different objects of interest in an image frame. The objects of interest can be broadly categorized into static and dynamic objects.
For dynamic objects like vehicles and pedestrians, we labeled the 2D box locations and track IDs. In addition to these standard attributes found in most datasets, we also labeled fine-grained attributes for vehicles such as license plate locations, and the head and tail light locations and state. This gives users the ability to train models that go beyond simply detecting vehicle locations.
Next, for static objects in the scene, we focused on lanes, traffic signs, and traffic lights. Unlike popular lane detection datasets that restrict themselves to a maximum of four lanes, we labeled every lane (using polylines) and its marker type in our direction of travel. We also labeled curbs and crosswalks because they’re important markers that dictate free space and driving behavior. For traffic lights, we labeled every visible light and its state.
Finally, for traffic signs, we labeled every visible sign and its type (such as stop, yield, and do not enter). Because we labeled every visible traffic light and sign, we also marked the ones that correspond to our direction of travel with a binary indicator: is_front from the preceding taxonomy. This gives us the benefit of having many labeled signs and lights, which improves model training, while still being able to identify the ones that actually affect driving behavior. This labeling taxonomy allows users to train most types of computer vision models that are of importance in modern automotive applications, while crucially addressing some of the shortcomings in existing datasets.
An example of lane labels is shown in the following image. The line perpendicular to the vehicle is the crosswalk, and the label contains the lane style, type and direction. Similarly, the lane divider on the left and the curb on the right side of the vehicle have labels according to the preceding taxonomy.

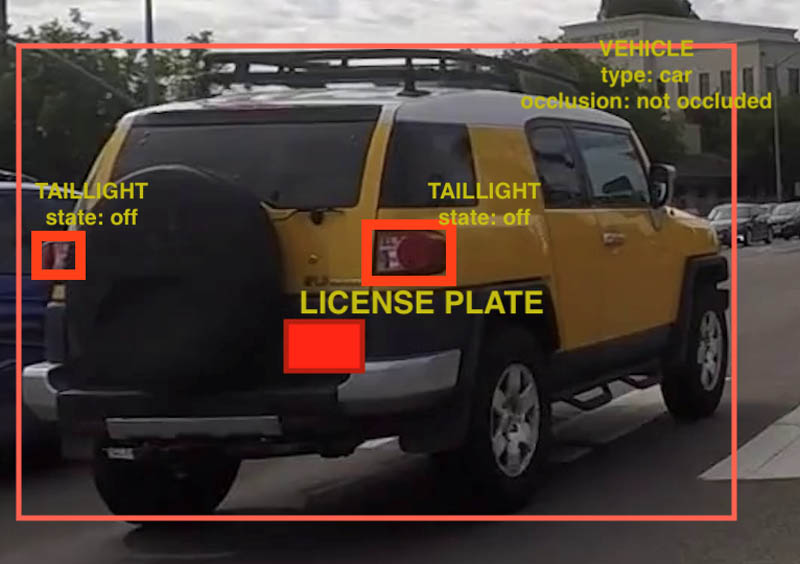
A labeled vehicle is shown in the following image. The vehicle label consists of its type and occlusion level, in addition to the vehicle internal objects: taillights with state and license plate.
The following example shows labeled traffic lights at various states, orientations, and occlusion levels, and traffic signs with various types, orientations, and occlusion levels.

Labeling architecture
When mapping such a complex taxonomy to actual labeling tasks in Ground Truth, there are often multiple trade-offs to make around what parts of the taxonomy are grouped together in labeling jobs, what modalities and annotation types in Ground Truth map well to the problem, and whether to follow a batch or streaming job model.
Because we wanted to perpetually send new video clips to labelers as they are collected and available, we used Ground Truth streaming labeling jobs. This also allowed us to receive labels and perform quality assurance and adjustment in real time after each clip is labeled. It also reduced the total number of labeling jobs we needed to have running in parallel because we only needed one long-living streaming labeling job per task type rather than multiple jobs per task type depending on the batch size. For more information about the advantages of streaming labeling jobs, see Real-time data labeling pipeline for ML workflows using Amazon SageMaker Ground Truth.
In addition to the requirement of continuous adjustment, the taxonomy consists of multiple classes and multiple annotation types based. For example, labeling vehicles requires using a video object tracking job to produce a consistent instance identifier per object over the course of the video clip to capture movement, but labeling traffic signs only requires video object detection. The taxonomy also requires different annotation types within the labeling job task type. For example, vehicles and traffic signs require bounding boxes, but lanes require line segments using a polyline tool, to better model the curve of street markings.
For example, the following is a frame from a video being labeled with a video object tracking job using bounding box annotations.

In contrast, the following similar clip uses polylines annotation, where line segments define the lanes.

For more information about the available annotation types supported for different data modalities, see Create a Labeling Category Configuration File with Label Category and Frame Attributes.
We found four main reasons to split our taxonomy into multiple parallel labeling tasks rather than attempting to perform all the labeling for a clip in a single task:
- Overlapping annotations reduce labeler throughput – If a scene is rich with objects to identify, that means there will be many highly overlapping annotations in a single task. This can reduce worker throughput and increase the number of errors created by workers.
- Different annotation types may require separate jobs – Today, SageMaker Ground Truth only allows one AnnotationType per labeling job. This necessitates splitting the taxonomy labeled by bounding boxes from that labeled by polylines.
- Multiple labeling jobs increase flexibility – With multiple jobs, as labeling priorities shift depending on your end users, it’s simpler to reallocate head count and resources as priorities shift. For example, if the end user is attempting to build a model that uses just a subset of the overall taxonomy, like a vehicle detector, labelers can label all clips for just for vehicles and ignore other jobs in the worker portal until they become higher priority.
- Multiple jobs allow specialization – As data labeling specifications get more complex, there is often a high cost associated with retraining data labelers in different modalities. Having parallel jobs means that certain workers can become specialists in only traffic sign labeling while others can specialize in lane annotations, increasing overall throughput.
To ensure high-quality annotations are being produced, we added a real-time adjustment ability by publishing a clip to the input Amazon Simple Notification Service (Amazon SNS) topic of a first-level streaming job for a task type, then after completion, sending the labeled clip to an adjustment streaming job which uses a specialized group of more skilled annotators to review the output of the first pass. These senior annotators perform quality assurance and modify labels as needed. This adjustment capability is backed by Ground Truth’s label adjustment and verification capabilities.
One simple way to connect these labeling jobs is to use the output SNS topic of the first-level streaming job and directly connect it to the input SNS topic of the second-level streaming job (for more information, see Real-time data labeling pipeline for ML workflows using Amazon SageMaker Ground Truth). We added an orchestration layer on top of Ground Truth using AWS Step Functions, Amazon DynamoDB, and AWS Lambda to resubmit a video clip when an initial or adjustment labeling task is not completed within Ground Truth’s timeout windows.
Architecture diagram
Now that we’ve covered the overall requirements that drove our labeling architecture, let’s review at a high level the functionality of the step function we implemented to handle sending a data object to each running streaming job while handling edge cases around expiration.
Each combination of video clip and label category configuration have an independently running step function invocation responsible for ensuring that video clip is passed through each desired labeling job. Each run manages the state primarily through DynamoDB, only relying on the state machine state to pass the annotation task IDs to subsequent states. The DynamoDB table responsible for tracking annotation tasks maintains any metadata including the clip identifier, input manifest location of the clip, output manifest location of labeling job output, and label attribute name, in addition to state information (complete, failed, or stopped).
The solution also provides an API for starting streaming labeling jobs with varying label category configurations. This streaming job is shared among all clips sent for labeling that have the same modality (vehicle bounding boxes for example). The solution also stores these labeling jobs by name in a separate DynamoDB table that maintains metadata about the streaming jobs started through the solution, including input and output SNS topics. Having a separate API for streaming job lifecycle management allows us to not launch redundant labeling jobs per clip, but instead only launch jobs for the unique modalities we want to label.
A SageMaker notebook instance starts each step function run (known as an annotation task) and iterates through a list of uploaded video clips in Amazon Simple Storage Service (Amazon S3) and calls the annotation task creation API for each clip and modality pair. The annotation task creation API stores the requested annotation task in DynamoDB, and then starts a step function run to service the requested task. The notebook provides the input location of the clip, the number of frames per second, and the list of labeling jobs that make up the workflow to the annotation task creation API, which passes that information to each step function run. For example, the following annotation task definition defines that the given clip should be sent to a streaming labeling job VOTVehicle, then the output of this first streaming job should be sent to a second job AdjVOTVehicle for adjustment:
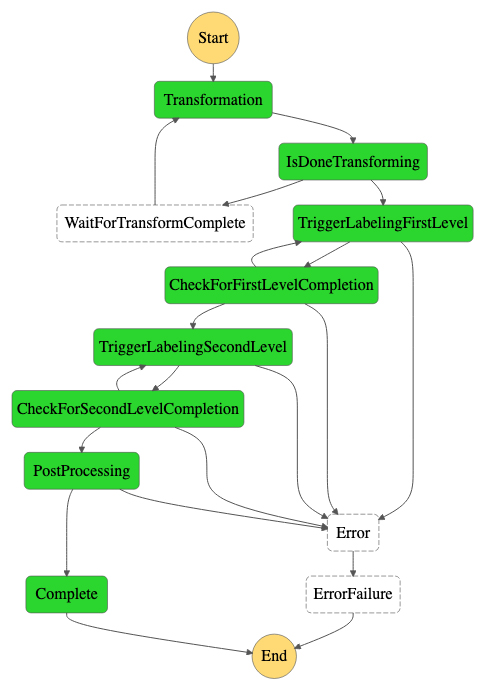
The following state machine diagram describes the overall logic flow for each created annotation task, which includes a video clip and a list of labeling jobs to send the video clip through. Every video clip goes through a transformation loop (Transformation, IsDoneTransforming, WaitForTransformComplete), that extracts image frames at a certain frame per second rate. After frame extraction, the state machine sends the frames to a Ground Truth streaming job for initial labeling (TriggerLabelingFirstLevel, CheckForFirstLevelCompletion).
After labeling completion, the state machine sends the frames and labels to label adjudication in the second-level labeling job (TriggerLabelingSecondLevel, CheckForSecondLevelCompletion).
After adjustment, the state machine processes the labels (PostProcessing) by calculating summary metadata on the clips and saved in Amazon S3 (Complete).
The state machine also contains reverse state transitions back from CheckForFirstLevelCompletion to TriggerLabelingFirstLevel and from CheckForSecondLevelCompletion to TriggerLabelingSecondLevel. These state transitions give the pipeline the ability to retry sending a clip for labeling if an expiration or problem is detected with the initial round of labeling. We cover these exception cases in more detail in the next section.
Connecting SNS topics and managing the video clip lifecycle
Using streaming jobs for long-running annotation tasks requires an orchestration layer, as mentioned earlier. To explain why, we walk through a direct approach to connecting streaming labeling jobs through Amazon SNS and describe the potential failure states.
The following diagram describes one way to connect between the initial labeling job and the adjustment job that doesn’t require any intervention from an orchestrating step function.
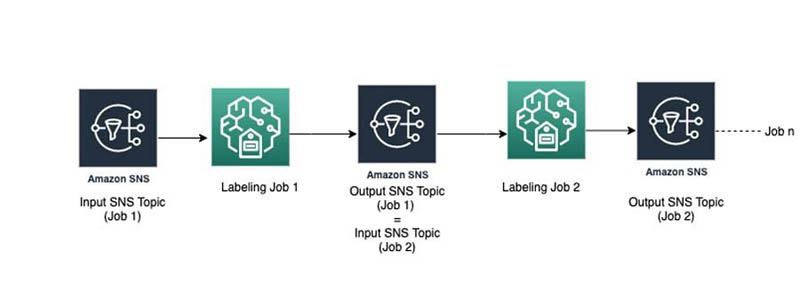
This approach works well when tasks are quickly completed (before the TaskAvailabilityLifetimeInSeconds specified during labeling job creation). However, when clips are queueing for labeling for a time greater than the task availability, the clip may be dropped in Amazon Simple Queue Service (Amazon SQS) or Ground Truth within the pipeline.
Instead of this approach, we broke the direct Amazon SNS connection between the labeling jobs and instead have the CheckForFirstLevelCompletion state wait for the SNS topic from the initial labeling job and optionally handle retries before moving to TriggerLabelingSecondLevel. A DynamoDB table tracks the SNS topic names for each labeling job whenever a new streaming job is created.
We describe each expiration case and a mitigation in the following sections.
Handling Amazon SQS time limits
Each streaming labeling job connects the specified input SNS topic to an SQS queue. As tasks are completed within the labeling job, Ground Truth takes items off the queue and makes them available for labeling. Amazon SQS has a 14-day limit before items expire of the input queue, meaning that if workers fail to complete enough tasks such that the queue doesn’t have its 14-day limit reached on any given item, that item is dropped.
One way to handle this is to periodically resend clips using a unique deduplication identifier per clip. This deduplication identifier can be specified on the Amazon SNS message along with a clip. To learn more about deduplication IDs and keys, see Duplicate Message Handling. As long as we resend the clip before the 14-day limit, we always have a non-expired version in the queue. If Ground Truth receives two clips with the same deduplication identifier, it ignores the duplicate, making this operation idempotent regardless of how many duplicate data objects we send to the job. We set a fairly short retry period of 5 days to ensure we are repeatedly refreshing the age of the data item in Amazon SQS in case we ever reach the 14-day window.
Handling worker dashboard time limits
Another expiration case to handle is when an object has been ingested by the streaming labeling job and is available in the worker portal, but fails to be labeled within the TaskAvailabilityLifetimeInSeconds. This timeout is specified in the HumanTaskConfig of labeling jobs. One way to mitigate this issue is by reducing the MaxConcurrentTaskCount of the labeling job. This reduces the number of tasks Ground Truth takes from its input queue, meaning the task timeout is only active on a smaller number of tasks at a time. However, this isn’t always a solution because if the concurrent task count is tuned too low, workers may run out of tasks while additional tasks are being moved from the input queue and preprocessed for labeling.
We handled this by using a large MaxConcurrentTaskCount and detecting Ground Truth task expirations on the output SNS topic of the labeling job. When state machine detects a task expiration from Ground Truth, it resends the data object to reset the expiration timer back to 0. One caveat is that because Ground Truth has already seen the expired data item’s deduplication identifier, we have to resend the clip using a modified deduplication identifier so Ground Truth sees the task as new and shows it in the worker portal.
Performing these retries and monitoring of clips as they go through the labeling process requires the external orchestration described in the preceding Step Function state diagram. The step function handles both cases mentioned earlier by either reusing the previous deduplication ID if we’re performing a retry to handle Amazon SQS timeouts, or by generating a new deduplication ID if we know the data object has had a format expiration in Ground Truth.
Architecture diagram steps
Now that we’ve seen failure cases and mitigations in long-running streaming jobs, we can see how these are modeled in the step function and take a closer look at how state transitions occur.
The Trigger* states of the overall step function send clips to the labeling jobs. This triggering state moves to a check for completion state that waits for the clip to be labeled. There is a state transition back from CheckForFirstLevelCompletion to TriggerLabelingFirstLevel. This allows the check for completion state to transition back when a clip wasn’t able to be labeled due to one of the preceding failure cases.
CheckForFirstLevelCompletion performs an event-driven wait by taking advantage of Step Functions task tokens. The state machine stores the current state machine run’s task token in DynamoDB upon reaching CheckForFirstLevelCompletion, then it lets a Lambda function that listens to each streaming job output SNS topic handle calling SendTaskSuccess or SendTaskFailure to the state machine run. This means that immediately after the labeling job completes on a particular clip, the clip’s state machine run becomes unblocked and flows to the next levels. The following diagram illustrates this workflow.

AWS Step Functions code samples
The following Step Functions code blocks describe the TriggerFirstLabelingLevel and CheckForFirstLevelCompletion state loop in the preceding state diagram.
The TriggerFirstLabelingLevel state runs the Lambda function that launches labeling jobs. On a successful run of the function, the state machine transitions to the CheckForFirstLevelCompletion state. On error, the state machine either retries running the function if it’s a known transient error, or transitions to the BatchError state.
The following Step Functions code block describes the CheckForFirstLevelCompletion state in the preceding state diagram. This state runs a Lambda function that waits for the completion of the labeling task. The state waits for labeling completion for 432,000 seconds (5 days), after which the state machine transitions back to TriggerLabelingFirstLevel and sends the video back into the Ground Truth SQS queue. On error, the state machine either retries running the Lambda function if the error is transient, transitions to the BatchError state if the error isn’t retry-able, or goes back to TriggerLabelingFirstLevel if the error state is expired, indicating the data item was expired from the streaming job. This last error state allows resending items immediately after expiration when the expiration occurs inside of Ground Truth.
AWS Lambda first-level labeling code samples
The TriggerFirstLabelingLevel state mentioned in the previous section calls the smgt-workflow-sf-trigger-labeling-job Lambda function to send dataset objects (like video clips) to a running streaming labeling job.
The following code block from the Lambda function describes how to launch a job from a set of frames. The lambda_handler function receives the labeling level (first-level labeling or second-level adjudication) and the parent batch ID. It filters the jobs to launch by the job level and calls the trigger_labeling_job function. Finally, it saves the labeling job metadata to the DynamoDB database if the job isn’t a retry attempt.
The following code shows the function that launches the labeling jobs trigger_labeling_job, trigger_streaming_job, and send_frames_to_streaming_job.
The trigger_labeling_job function calls the trigger_streaming_job function with parameters required for sending an annotation task to a particular labeling job. The trigger_streaming_job function gets the input SNS topic and input manifest and creates a file for output labels. It then calls the send_frames_to_streaming_job with the input SNS topic, manifest, and various IDs.
The send_frames_to_streaming_job loops through each frame, creates a deduplication key, stores the frame on DynamoDB, and publishes the frame to the output SNS topic. The logic for handling both Amazon SQS and Ground Truth expirations is encoded in this function. It can regenerate a new deduplication ID in the case of a Ground Truth expiration, or just reuse the existing deduplication ID if the retry is to keep the item from expiration in Amazon SQS.
Conclusion
In this post we described the LAVA dataset, a data collection strategy, label taxonomy, and labeling architecture for 2D bounding boxes using Ground Truth. The dataset was a result of a collaboration between the Amazon Machine Learning Solutions Lab and the Laboratory of Intelligent and Safe Automobiles (LISA Lab) at the University of California, San Diego (UCSD)
The labeling architecture solution developed for the LAVA dataset enables on-going large scale video collection and labeling efforts. The labeling architecture consists of a pipeline that manages the labeling lifecycle of a video clip from frame extraction, first and second level labeling and timeouts. This pipeline produces high-quality annotations and is flexible to changes in labeling priorities.
The Amazon ML Solutions Lab pairs your team with ML experts to help you identify and implement your organization’s highest value ML opportunities. If you’d like help accelerating your use of ML in your products and processes, please contact the Amazon ML Solutions Lab.
Acknowledgments
The authors would like to thank LISA’s dataset collection and annotation team, including Larry Ly, David Lu, Sean Liu, Jason Isa, Maitrayee Keskar, Anish Gopalan, Ethan Lee, and Tristan Philip.
About the Authors
 Ninad Kulkarni is a Data Scientist in the Amazon Machine Learning Solutions Lab. He helps customers adopt ML and AI by building solutions to address their business problems. Most recently, he has built predictive models for sports and automotive customers.
Ninad Kulkarni is a Data Scientist in the Amazon Machine Learning Solutions Lab. He helps customers adopt ML and AI by building solutions to address their business problems. Most recently, he has built predictive models for sports and automotive customers.
 Jeremy Feltracco is a Software Development Engineer with the Amazon ML Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.
Jeremy Feltracco is a Software Development Engineer with the Amazon ML Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.
 Saman Sarraf is a Data Scientist at the Amazon ML Solutions Lab. His background is in applied machine learning including deep learning, computer vision, and time series data prediction.
Saman Sarraf is a Data Scientist at the Amazon ML Solutions Lab. His background is in applied machine learning including deep learning, computer vision, and time series data prediction.
 Akshay Rangesh is a PhD candidate in Electrical & Computer Engineering at UCSD. His research interests span computer vision and machine learning, with a focus on object detection and tracking, human activity recognition, and driver safety systems in general. He is also particularly interested in sensor fusion and multi-modal approaches for real time algorithms.
Akshay Rangesh is a PhD candidate in Electrical & Computer Engineering at UCSD. His research interests span computer vision and machine learning, with a focus on object detection and tracking, human activity recognition, and driver safety systems in general. He is also particularly interested in sensor fusion and multi-modal approaches for real time algorithms.
 Ross Greer is a PhD student in Electrical & Computer Engineering at UCSD, advised by Dr. Mohan Trivedi. His research with LISA focuses on estimating and predicting driving behavior using machine learning.
Ross Greer is a PhD student in Electrical & Computer Engineering at UCSD, advised by Dr. Mohan Trivedi. His research with LISA focuses on estimating and predicting driving behavior using machine learning.
 Nachiket Deo is a PhD candidate in Electrical & Computer Engineering at UCSD. His research interests span computer vision and machine learning for autonomous driving, with a focus on intent and motion prediction of surrounding agents, and driver activity analysis for safe control transitions.
Nachiket Deo is a PhD candidate in Electrical & Computer Engineering at UCSD. His research interests span computer vision and machine learning for autonomous driving, with a focus on intent and motion prediction of surrounding agents, and driver activity analysis for safe control transitions.
 Jonathan Buck is a software engineer at Amazon. His focus is on building impactful software services and products to democratize machine learning.
Jonathan Buck is a software engineer at Amazon. His focus is on building impactful software services and products to democratize machine learning.
 Suchitra Sathyanarayana is a manager at the Amazon ML Solutions Lab, where she helps AWS customers across different industry verticals accelerate their AI and cloud adoption. She holds a PhD in Computer Vision from Nanyang Technological University, Singapore.
Suchitra Sathyanarayana is a manager at the Amazon ML Solutions Lab, where she helps AWS customers across different industry verticals accelerate their AI and cloud adoption. She holds a PhD in Computer Vision from Nanyang Technological University, Singapore.
 Mohan M. Trivedi (Life Fellow IEEE, SPIE, and IAPR) is a Distinguished Professor of Electrical and Computer Engineering at the University of California, San Diego and the founding director of the Computer Vision and Robotics Research (CVRR, est. 1986) and the Laboratory for Intelligent and Safe Automobiles (LISA, est. 2001). His research is in intelligent vehicles, intelligent transportation systems (ITS), autonomous driving, driver assistance systems, active safety, human-robot interactivity, machine vision areas. UCSD LISA was awarded the IEEE ITSS Lead Institution Award. Trivedi has served as the editor-in-chief of the Machine Vision and Applications, Senior Editor of the IEEE Trans on IV and ITSC, as well as Chairman of the Robotics Technical Committee of IEEE Computer Society and Board of
Mohan M. Trivedi (Life Fellow IEEE, SPIE, and IAPR) is a Distinguished Professor of Electrical and Computer Engineering at the University of California, San Diego and the founding director of the Computer Vision and Robotics Research (CVRR, est. 1986) and the Laboratory for Intelligent and Safe Automobiles (LISA, est. 2001). His research is in intelligent vehicles, intelligent transportation systems (ITS), autonomous driving, driver assistance systems, active safety, human-robot interactivity, machine vision areas. UCSD LISA was awarded the IEEE ITSS Lead Institution Award. Trivedi has served as the editor-in-chief of the Machine Vision and Applications, Senior Editor of the IEEE Trans on IV and ITSC, as well as Chairman of the Robotics Technical Committee of IEEE Computer Society and Board of
Governors of the IEEE ITSS and IEEE SMC societies.