Artificial Intelligence
Category: Serverless

Build and train computer vision models to detect car positions in images using Amazon SageMaker and Amazon Rekognition
Computer vision (CV) is one of the most common applications of machine learning (ML) and deep learning. Use cases range from self-driving cars, content moderation on social media platforms, cancer detection, and automated defect detection. Amazon Rekognition is a fully managed service that can perform CV tasks like object detection, video segment detection, content moderation, […]

Implement backup and recovery using an event-driven serverless architecture with Amazon SageMaker Studio
Amazon SageMaker Studio is the first fully integrated development environment (IDE) for ML. It provides a single, web-based visual interface where you can perform all machine learning (ML) development steps required to build, train, tune, debug, deploy, and monitor models. It gives data scientists all the tools you need to take ML models from experimentation […]

Automate Amazon Rekognition Custom Labels model training and deployment using AWS Step Functions
With Amazon Rekognition Custom Labels, you can have Amazon Rekognition train a custom model for object detection or image classification specific to your business needs. For example, Rekognition Custom Labels can find your logo in social media posts, identify your products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected […]

Automated exploratory data analysis and model operationalization framework with a human in the loop
Identifying, collecting, and transforming data is the foundation for machine learning (ML). According to a Forbes survey, there is widespread consensus among ML practitioners that data preparation accounts for approximately 80% of the time spent in developing a viable ML model. In addition, many of our customers face several challenges during the model operationalization phase […]
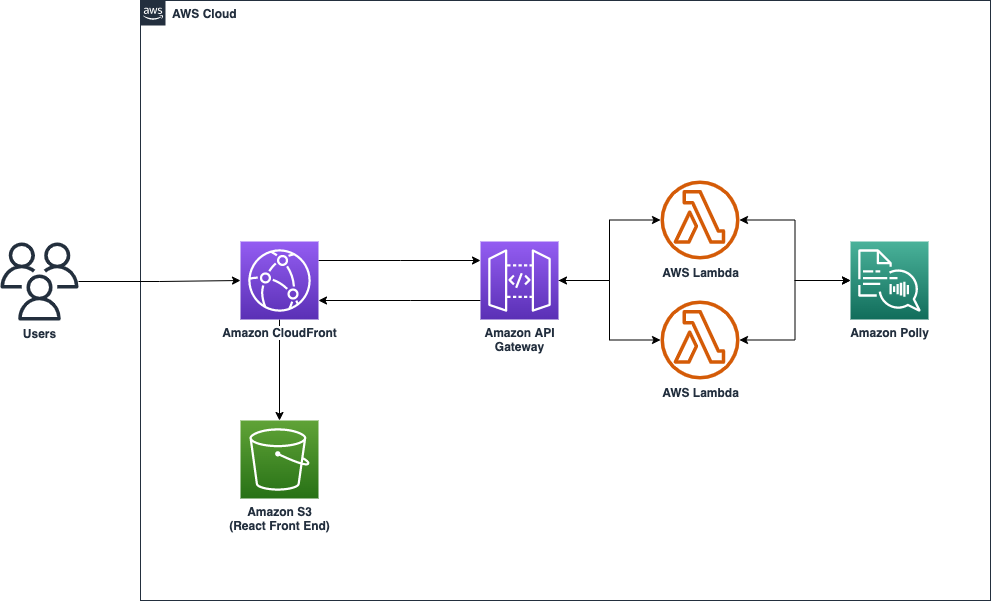
Improve organizational diversity, equity, and inclusion initiatives with Amazon Polly
Organizational diversity, equity and inclusion (DEI) initiatives are at the forefront of companies across the globe. By constructing inclusive spaces with individuals from diverse backgrounds and experiences, businesses can better represent our mutual societal needs and deliver on objectives. In the article How Diversity Can Drive Innovation, Harvard Business Review states that companies that focus […]

Increase your content reach with automated document-to-speech conversion using Amazon AI services
Reading the printed word opens up a world of information, imagination, and creativity. However, scanned books and documents may be difficult for people with vision impairment and learning disabilities to consume. In addition, some people prefer to listen to text-based content versus reading it. A document-to-speech solution extends the reach of digital content by giving […]

Reduce costs and complexity of ML preprocessing with Amazon S3 Object Lambda
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Often, customers have objects in S3 buckets that need further processing to be used effectively by consuming applications. Data engineers must support these application-specific data views with trade-offs between persisting derived copies or transforming data […]

Machine learning inference at scale using AWS serverless
With the growing adoption of Machine Learning (ML) across industries, there is an increasing demand for faster and easier ways to run ML inference at scale. ML use cases, such as manufacturing defect detection, demand forecasting, fraud surveillance, and many others, involve tens or thousands of datasets, including images, videos, files, documents, and other artifacts. […]

Using container images to run TensorFlow models in AWS Lambda
TensorFlow is an open-source machine learning (ML) library widely used to develop neural networks and ML models. Those models are usually trained on multiple GPU instances to speed up training, resulting in expensive training time and model sizes up to a few gigabytes. After they’re trained, these models are deployed in production to produce inferences. […]