AWS Machine Learning Blog
Category: Compute
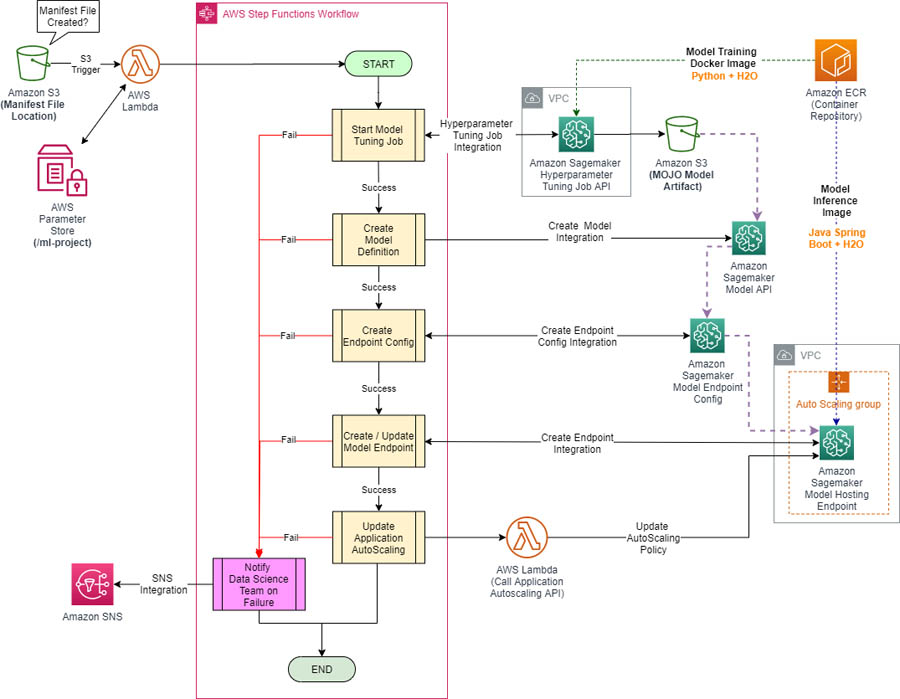
Training and serving H2O models using Amazon SageMaker
Model training and serving steps are two essential pieces of a successful end-to-end machine learning (ML) pipeline. These two steps often require different software and hardware setups to provide the best mix for a production environment. Model training is optimized for a low-cost, feasible total run duration, scientific flexibility, and model interpretability objectives, whereas model […]

Building a medical image search platform on AWS
Improving radiologist efficiency and preventing burnout is a primary goal for healthcare providers. A nationwide study published in Mayo Clinic Proceedings in 2015 showed radiologist burnout percentage at a concerning 61% [1]. In additon, the report concludes that “burnout and satisfaction with work-life balance in US physicians worsened from 2011 to 2014. More than half […]

Join AWS and NVIDIA at GTC, October 5–9
Starting Monday, October 5, 2020, the NVIDIA GPU Technology Conference (GTC) is offering online sessions for you to learn AWS best practices to accomplish your machine learning (ML), virtual workstations, high performance computing (HPC), and internet of things (IoT) goals faster and more easily. Amazon Elastic Compute Cloud (Amazon EC2) instances powered by NVIDIA GPUs […]
AWS Inferentia is now available in 11 AWS Regions, with best-in-class performance for running object detection models at scale
AWS has expanded the availability of Amazon EC2 Inf1 instances to four new AWS Regions, bringing the total number of supported Regions to 11: US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Mumbai, Singapore, Sydney, Tokyo), Europe (Frankfurt, Ireland, Paris), and South America (São Paulo). Amazon EC2 Inf1 instances are powered by AWS […]

Visualizing TensorFlow training jobs with TensorBoard
TensorBoard is an open source toolkit for TensorFlow users that allows you to visualize a wide range of useful information about your model, from model graphs; to loss, accuracy, or custom metrics; to embedding projections, images, and histograms of weights and biases. This post demonstrates how to use TensorBoard with Amazon SageMaker training jobs, write […]

How to run distributed training using Horovod and MXNet on AWS DL Containers and AWS Deep Learning AMIs
Distributed training of large deep learning models has become an indispensable way of model training for computer vision (CV) and natural language processing (NLP) applications. Open source frameworks such as Horovod provide distributed training support to Apache MXNet, PyTorch, and TensorFlow. Converting your non-distributed Apache MXNet training script to use distributed training with Horovod only […]
Amazon EC2 Inf1 instances featuring AWS Inferentia chips now available in five new Regions and with improved performance
Following strong customer demand, AWS has expanded the availability of Amazon EC2 Inf1 instances to five new Regions: US East (Ohio), Asia Pacific (Sydney, Tokyo), and Europe (Frankfurt, Ireland). Inf1 instances are powered by AWS Inferentia chips, which Amazon custom-designed to provide you with the lowest cost per inference in the cloud and lower barriers […]

Facebook uses Amazon EC2 to evaluate the Deepfake Detection Challenge
In October 2019, AWS announced that it was working with Facebook, Microsoft, and the Partnership on AI on the first Deepfake Detection Challenge. Deepfake algorithms are the same as the underlying technology that has given us realistic animation effects in movies and video games. Unfortunately, those same algorithms have been used by bad actors to […]

AWS to offer NVIDIA A100 Tensor Core GPU-based Amazon EC2 instances
Tens of thousands of customers rely on AWS for building machine learning (ML) applications. Customers like Airbnb and Pinterest use AWS to optimize their search recommendations, Lyft and Toyota Research Institute to develop their autonomous vehicle programs, and Capital One and Intuit to build and deploy AI-powered customer assistants. AWS offers the broadest and deepest […]

Reducing player wait time and right sizing compute allocation using Amazon SageMaker RL and Amazon EKS
As a multiplayer game publisher, you may often need to either over-provision resources or manually manage compute allocation when launching or maintaining an online game to avoid long player wait times. You need to develop, configure, and deploy tools that help you monitor and control the compute allocation. This post demonstrates GameServer Autopilot, a new […]