Artificial Intelligence
Category: Amazon SageMaker
Serverless deployment for your Amazon SageMaker Canvas models
In this post, we walk through how to take an ML model built in SageMaker Canvas and deploy it using SageMaker Serverless Inference, helping you go from model creation to production-ready predictions quickly and efficiently without managing any infrastructure. This solution demonstrates a complete workflow from adding your trained model to the SageMaker Model Registry through creating serverless endpoint configurations and deploying endpoints that automatically scale based on demand .
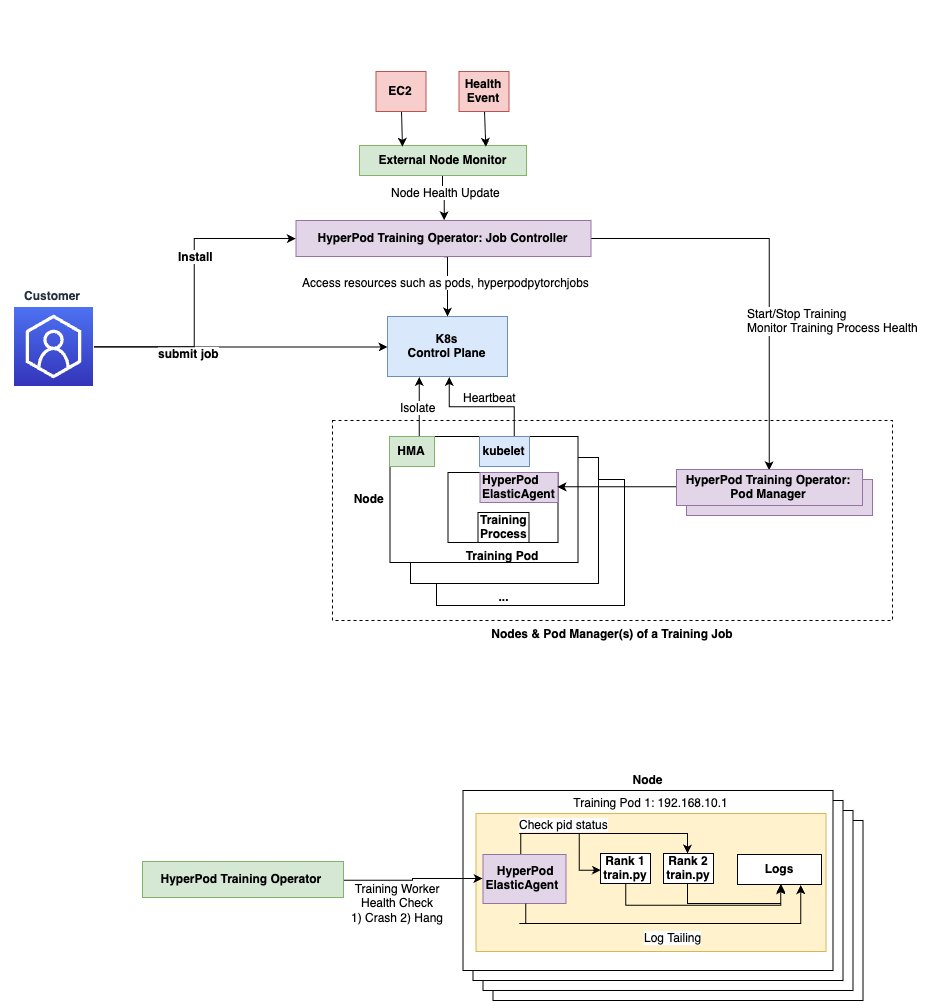
Accelerate large-scale AI training with Amazon SageMaker HyperPod training operator
In this post, we demonstrate how to deploy and manage machine learning training workloads using the Amazon SageMaker HyperPod training operator, which enhances training resilience for Kubernetes workloads through pinpoint recovery and customizable monitoring capabilities. The Amazon SageMaker HyperPod training operator helps accelerate generative AI model development by efficiently managing distributed training across large GPU clusters, offering benefits like centralized training process monitoring, granular process recovery, and hanging job detection that can reduce recovery times from tens of minutes to seconds.

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.

Scala development in Amazon SageMaker Studio with Almond kernel
This post provides a comprehensive guide on integrating the Almond kernel into SageMaker Studio, offering a solution for Scala development within the platform.
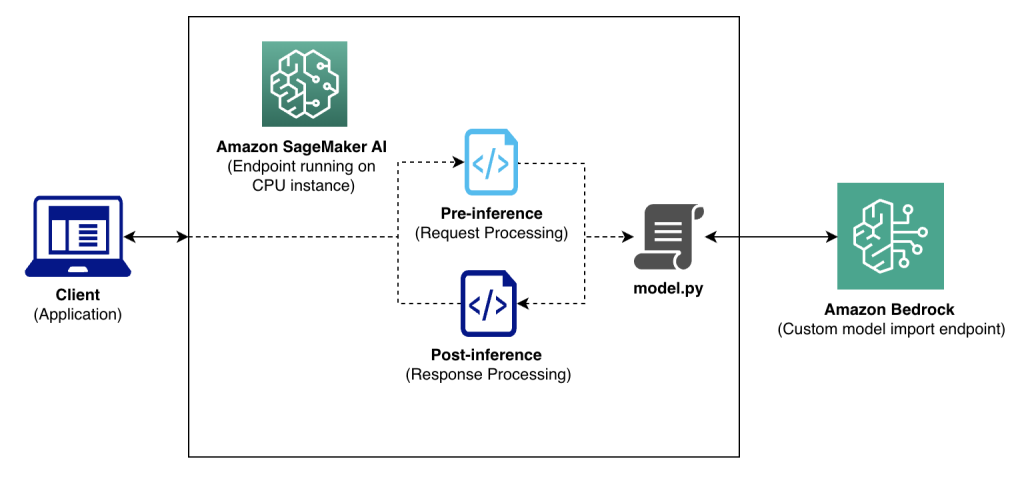
How Amazon Bedrock Custom Model Import streamlined LLM deployment for Salesforce
This post shows how Salesforce integrated Amazon Bedrock Custom Model Import into their machine learning operations (MLOps) workflow, reused existing endpoints without application changes, and benchmarked scalability. We share key metrics on operational efficiency and cost optimization gains, and offer practical insights for simplifying your deployment strategy.
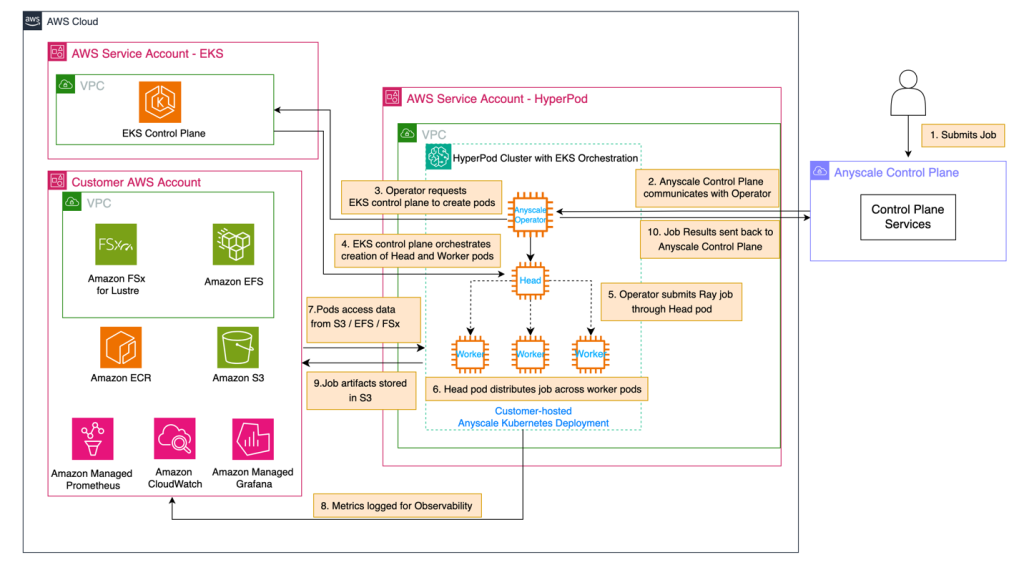
Use Amazon SageMaker HyperPod and Anyscale for next-generation distributed computing
In this post, we demonstrate how to integrate Amazon SageMaker HyperPod with Anyscale platform to address critical infrastructure challenges in building and deploying large-scale AI models. The combined solution provides robust infrastructure for distributed AI workloads with high-performance hardware, continuous monitoring, and seamless integration with Ray, the leading AI compute engine, enabling organizations to reduce time-to-market and lower total cost of ownership.
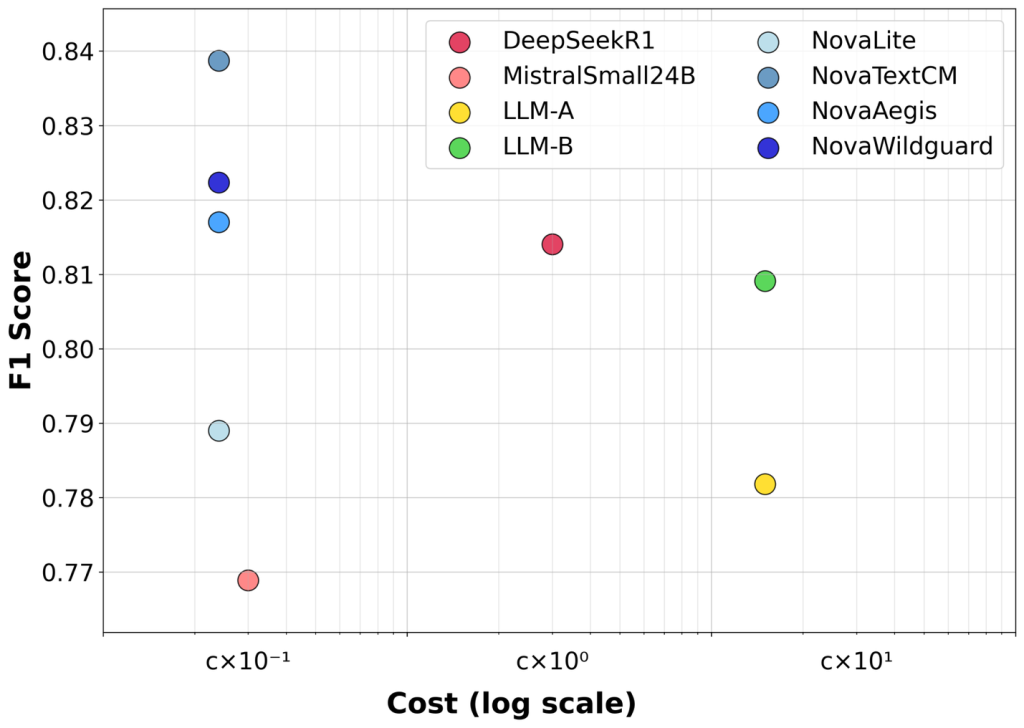
Customizing text content moderation with Amazon Nova
In this post, we introduce Amazon Nova customization for text content moderation through Amazon SageMaker AI, enabling organizations to fine-tune models for their specific moderation needs. The evaluation across three benchmarks shows that customized Nova models achieve an average improvement of 7.3% in F1 scores compared to the baseline Nova Lite, with individual improvements ranging from 4.2% to 9.2% across different content moderation tasks.
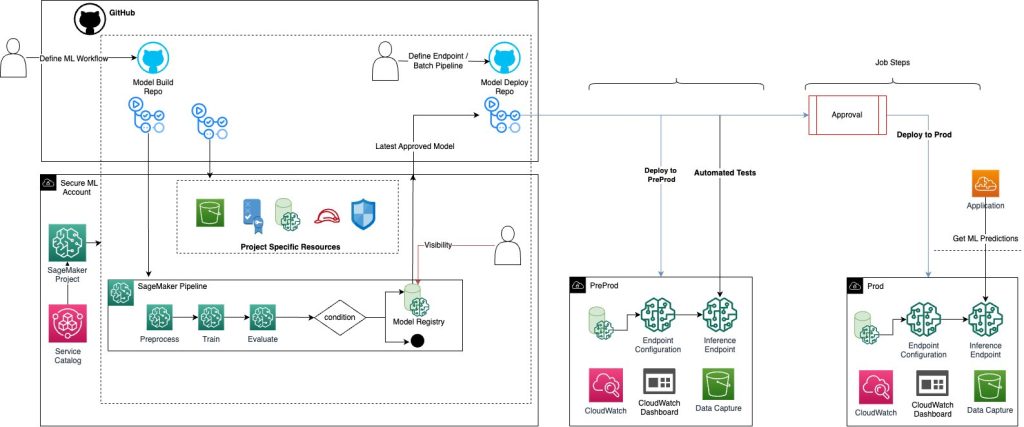
Implement a secure MLOps platform based on Terraform and GitHub
Machine learning operations (MLOps) is the combination of people, processes, and technology to productionize ML use cases efficiently. To achieve this, enterprise customers must develop MLOps platforms to support reproducibility, robustness, and end-to-end observability of the ML use case’s lifecycle. Those platforms are based on a multi-account setup by adopting strict security constraints, development best […]
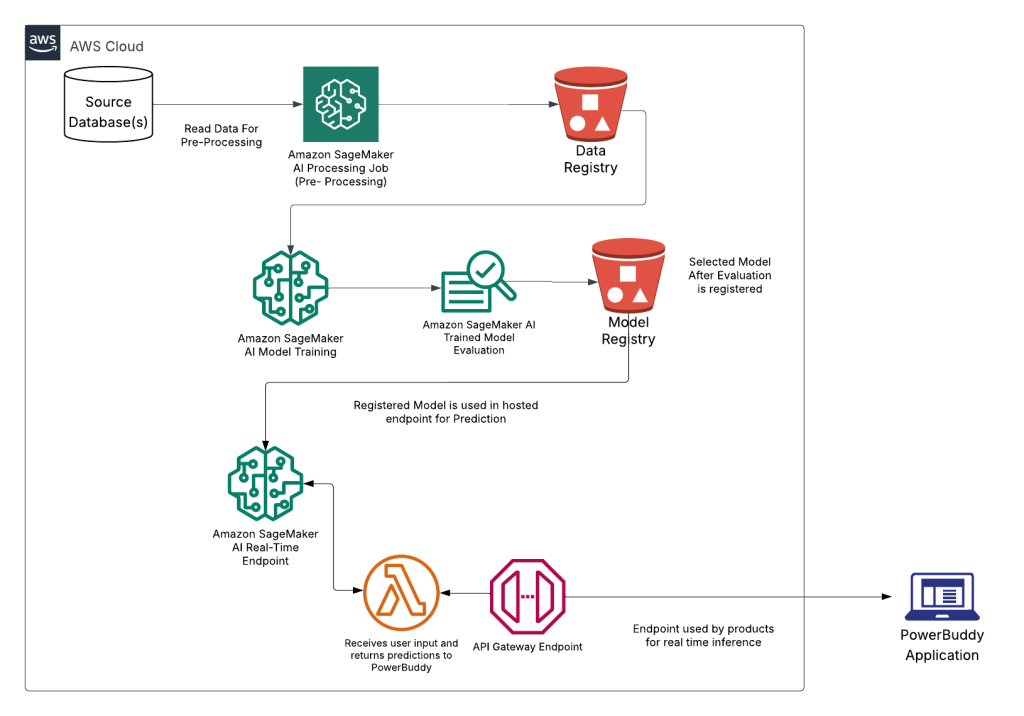
Responsible AI: How PowerSchool safeguards millions of students with AI-powered content filtering using Amazon SageMaker AI
In this post, we demonstrate how PowerSchool built and deployed a custom content filtering solution using Amazon SageMaker AI that achieved better accuracy while maintaining low false positive rates. We walk through our technical approach to fine tuning Llama 3.1 8B, our deployment architecture, and the performance results from internal validations.
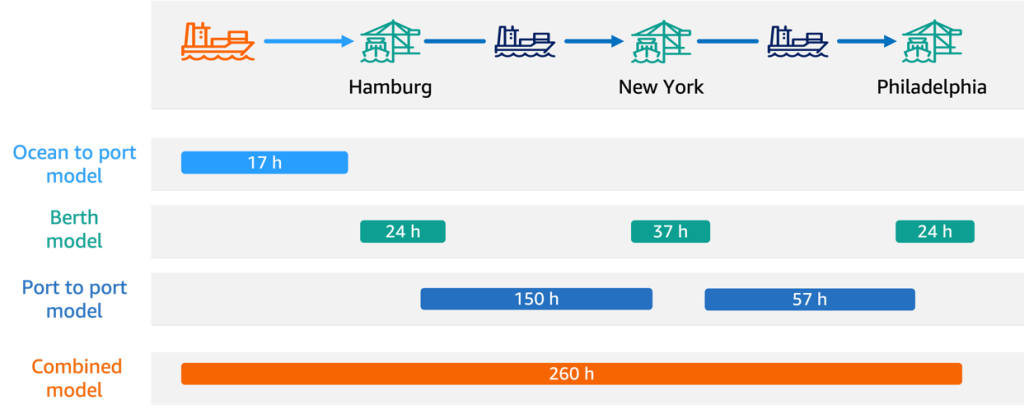
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.