Artificial Intelligence
Category: Amazon SageMaker
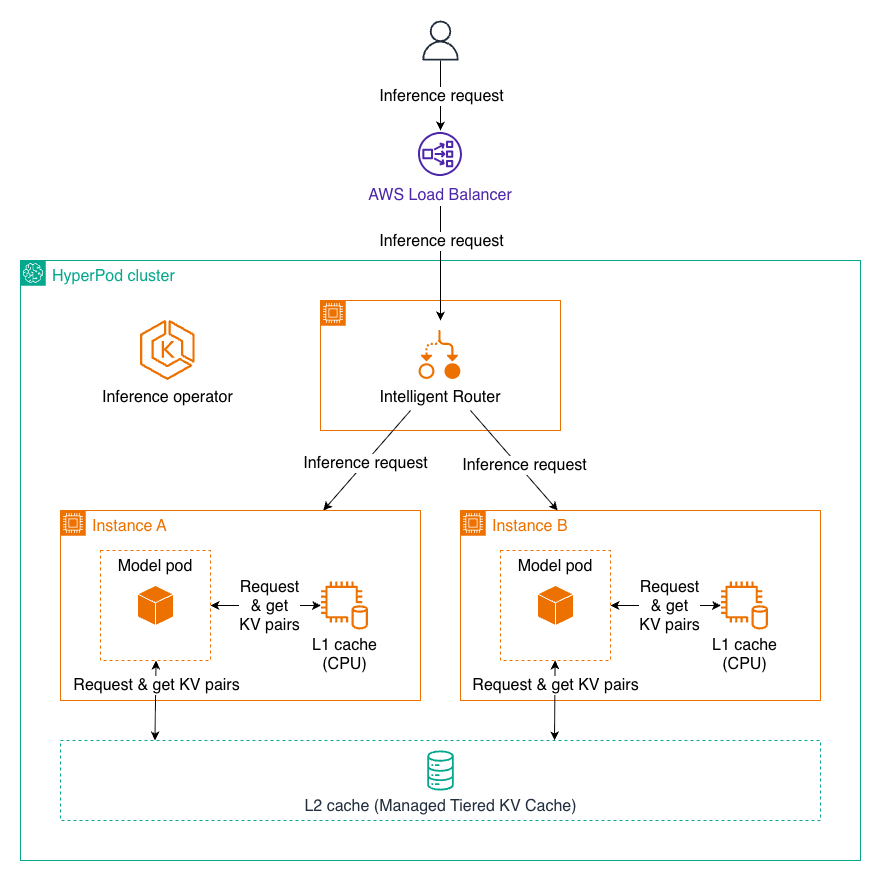
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.

How Condé Nast accelerated contract processing and rights analysis with Amazon Bedrock
In this post, we explore how Condé Nast used Amazon Bedrock and Anthropic’s Claude to accelerate their contract processing and rights analysis workstreams. The company’s extensive portfolio, spanning multiple brands and geographies, required managing an increasingly complex web of contracts, rights, and licensing agreements.

University of California Los Angeles delivers an immersive theater experience with AWS generative AI services
In this post, we will walk through the performance constraints and design choices by OARC and REMAP teams at UCLA, including how AWS serverless infrastructure, AWS Managed Services, and generative AI services supported the rapid design and deployment of our solution. We will also describe our use of Amazon SageMaker AI and how it can be used reliably in immersive live experiences.
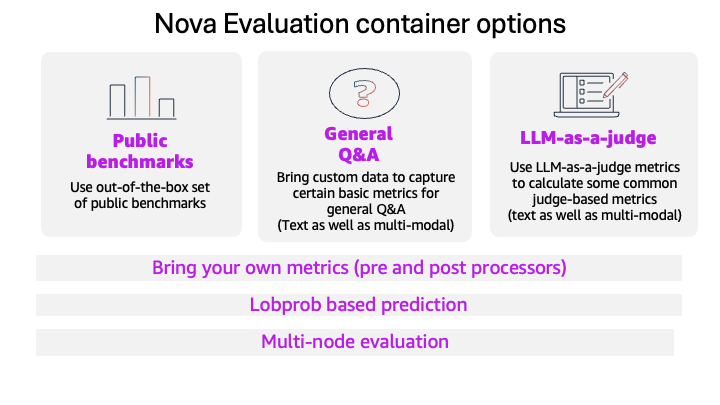
Evaluate models with the Amazon Nova evaluation container using Amazon SageMaker AI
This blog post introduces the new Amazon Nova model evaluation features in Amazon SageMaker AI. This release adds custom metrics support, LLM-based preference testing, log probability capture, metadata analysis, and multi-node scaling for large evaluations.
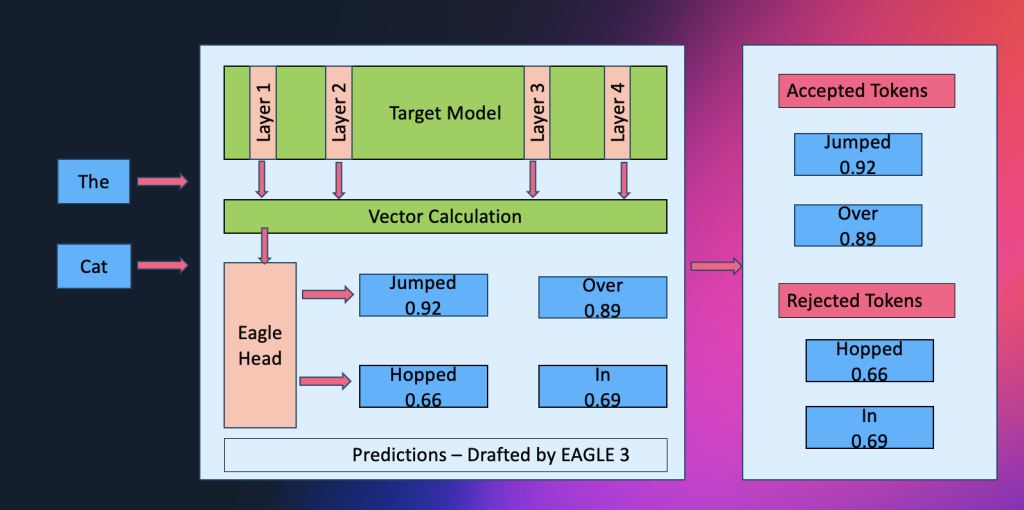
Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference
Amazon SageMaker AI now supports EAGLE-based adaptive speculative decoding, a technique that accelerates large language model inference by up to 2.5x while maintaining output quality. In this post, we explain how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI, covering the solution architecture, optimization workflows using your own datasets or SageMaker’s built-in data, and benchmark results demonstrating significant improvements in throughput and latency.
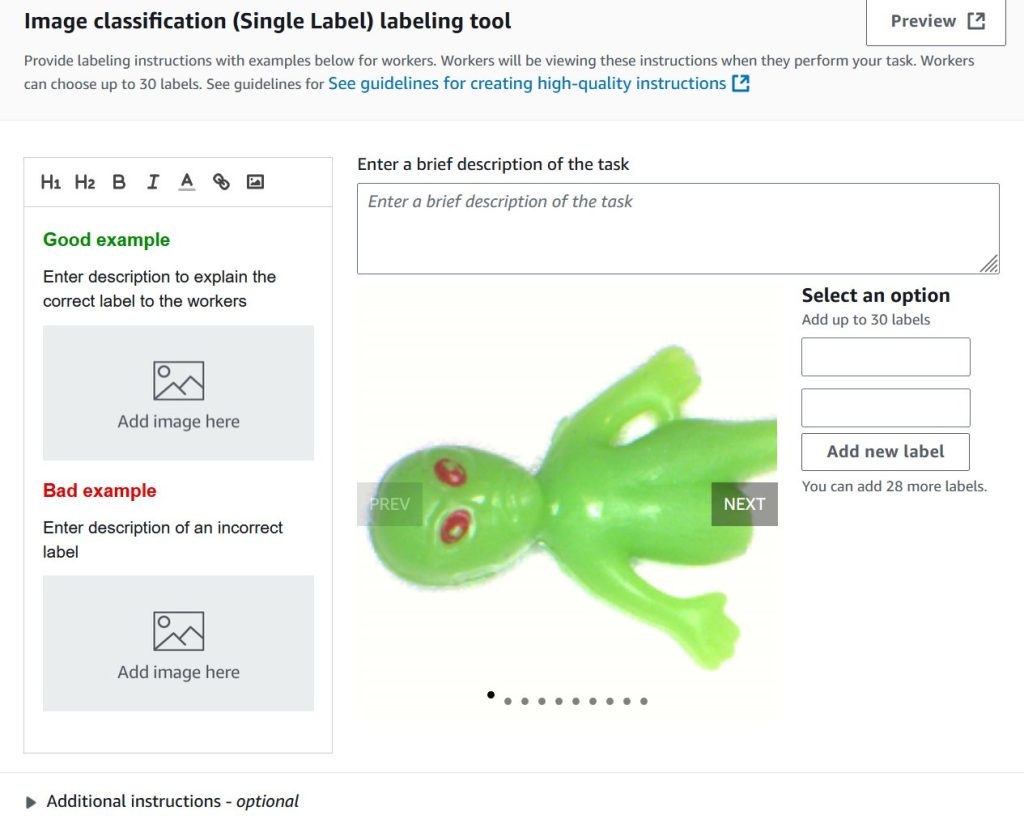
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.

Introducing bidirectional streaming for real-time inference on Amazon SageMaker AI
We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference.

Warner Bros. Discovery achieves 60% cost savings and faster ML inference with AWS Graviton
Warner Bros. Discovery (WBD) is a leading global media and entertainment company that creates and distributes the world’s most differentiated and complete portfolio of content and brands across television, film and streaming. In this post, we describe the scale of our offerings, artificial intelligence (AI)/machine learning (ML) inference infrastructure requirements for our real time recommender systems, and how we used AWS Graviton-based Amazon SageMaker AI instances for our ML inference workloads and achieved 60% cost savings and 7% to 60% latency improvements across different models.
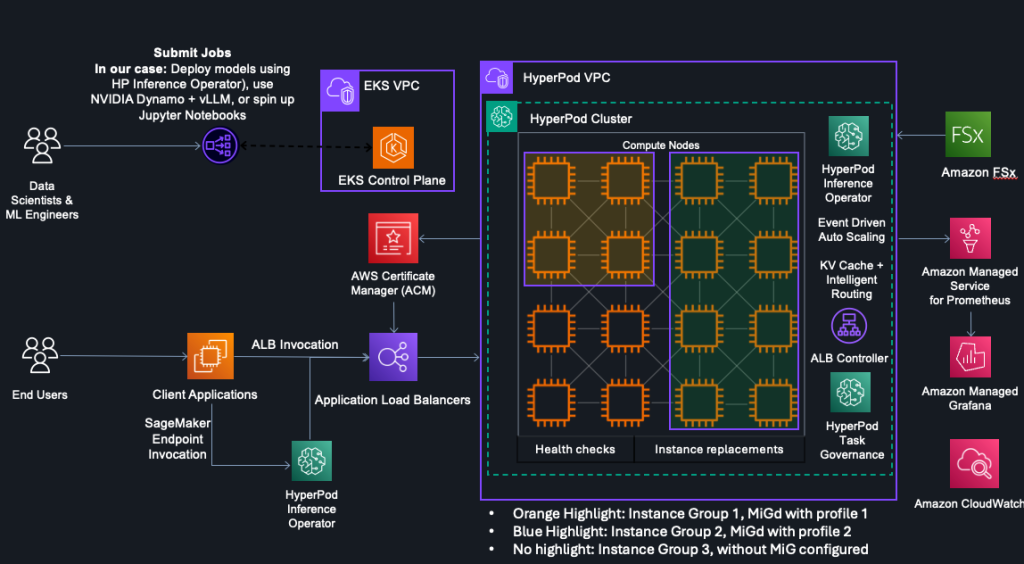
HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasks
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.

Power up your ML workflows with interactive IDEs on SageMaker HyperPod
Amazon SageMaker HyperPod clusters with Amazon Elastic Kubernetes Service (EKS) orchestration now support creating and managing interactive development environments such as JupyterLab and open source Visual Studio Code, streamlining the ML development lifecycle by providing managed environments for familiar tools to data scientists. This post shows how HyperPod administrators can configure Spaces for their clusters, and how data scientists can create and connect to these Spaces.