Artificial Intelligence
Category: Artificial Intelligence

Deploy GPT-OSS models with Amazon Bedrock Custom Model Import
In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications.
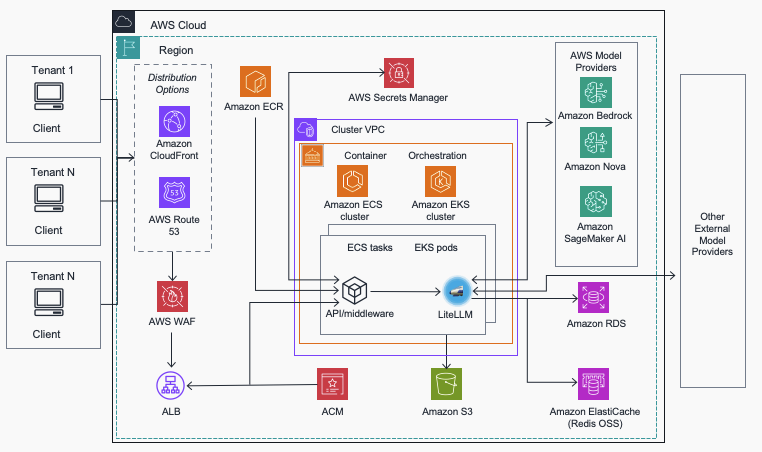
Streamline AI operations with the Multi-Provider Generative AI Gateway reference architecture
In this post, we introduce the Multi-Provider Generative AI Gateway reference architecture, which provides guidance for deploying LiteLLM into an AWS environment to streamline the management and governance of production generative AI workloads across multiple model providers. This centralized gateway solution addresses common enterprise challenges including provider fragmentation, decentralized governance, operational complexity, and cost management by offering a unified interface that supports Amazon Bedrock, Amazon SageMaker AI, and external providers while maintaining comprehensive security, monitoring, and control capabilities.

Deploy geospatial agents with Foursquare Spatial H3 Hub and Amazon SageMaker AI
In this post, you’ll learn how to deploy geospatial AI agents that can answer complex spatial questions in minutes instead of months. By combining Foursquare Spatial H3 Hub’s analysis-ready geospatial data with reasoning models deployed on Amazon SageMaker AI, you can build agents that enable nontechnical domain experts to perform sophisticated spatial analysis through natural language queries—without requiring geographic information system (GIS) expertise or custom data engineering pipelines.
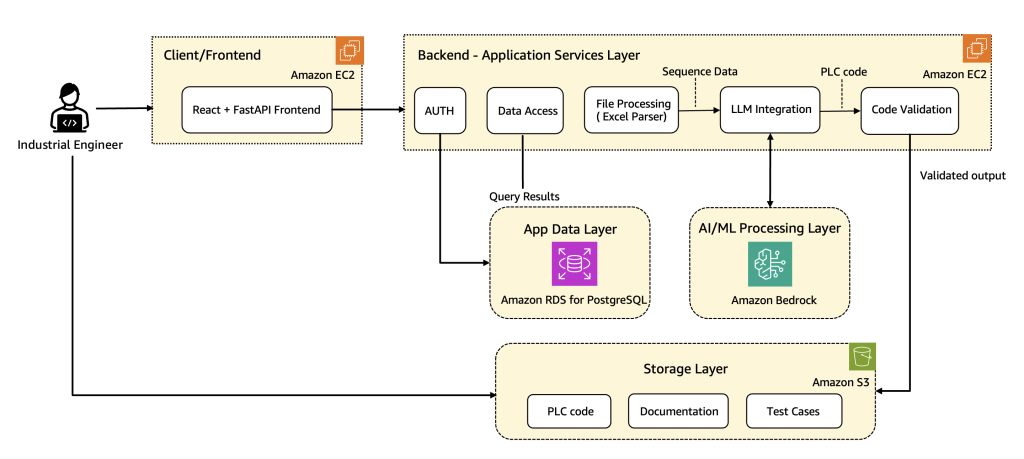
How Wipro PARI accelerates PLC code generation using Amazon Bedrock
In this post, we share how Wipro implemented advanced prompt engineering techniques, custom validation logic, and automated code rectification to streamline the development of industrial automation code at scale using Amazon Bedrock. We walk through the architecture along with the key use cases, explain core components and workflows, and share real-world results that show the transformative impact on manufacturing operations.
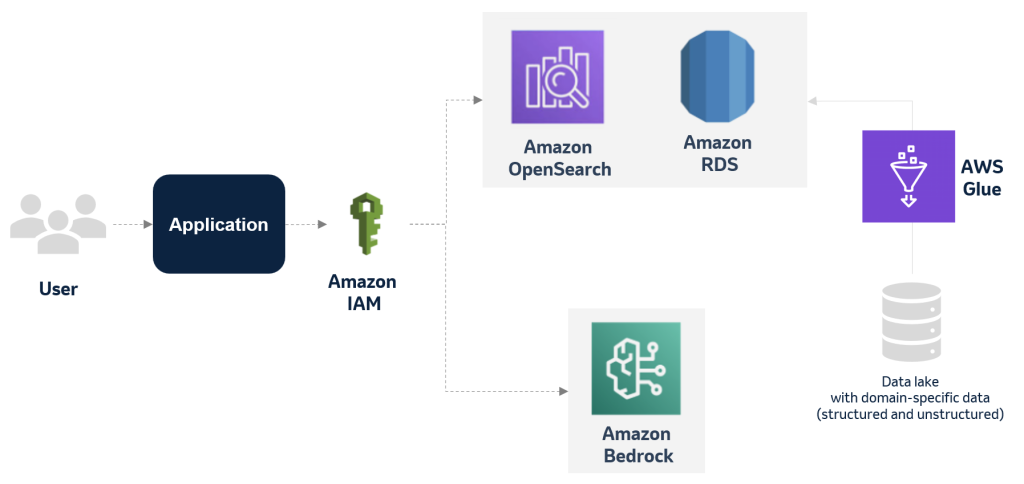
MSD explores applying generative Al to improve the deviation management process using AWS services
This blog post has explores how MSD is harnessing the power of generative AI and databases to optimize and transform its manufacturing deviation management process. By creating an accurate and multifaceted knowledge base of past events, deviations, and findings, the company aims to significantly reduce the time and effort required for each new case while maintaining the highest standards of quality and compliance.
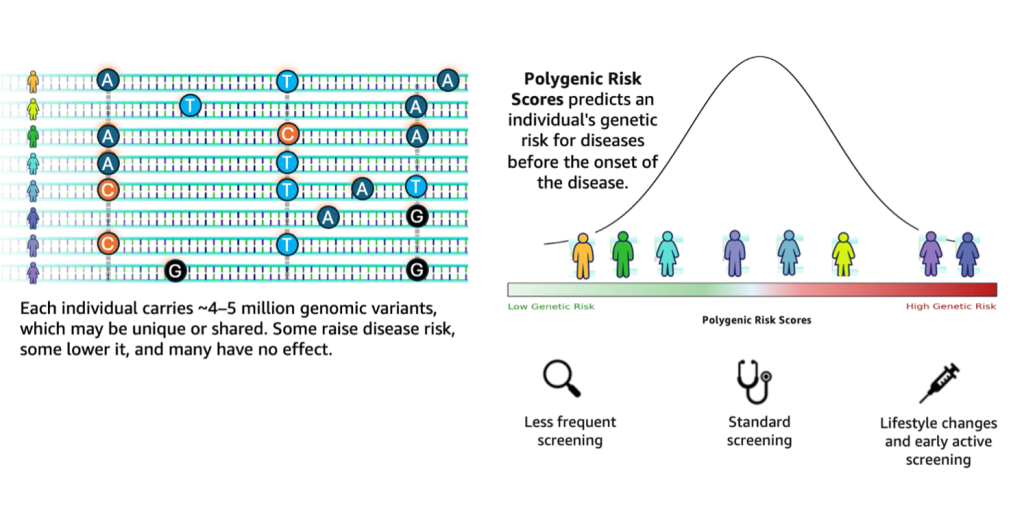
Accelerating genomics variant interpretation with AWS HealthOmics and Amazon Bedrock AgentCore
In this blog post, we show you how agentic workflows can accelerate the processing and interpretation of genomics pipelines at scale with a natural language interface. We demonstrate a comprehensive genomic variant interpreter agent that combines automated data processing with intelligent analysis to address the entire workflow from raw VCF file ingestion to conversational query interfaces.
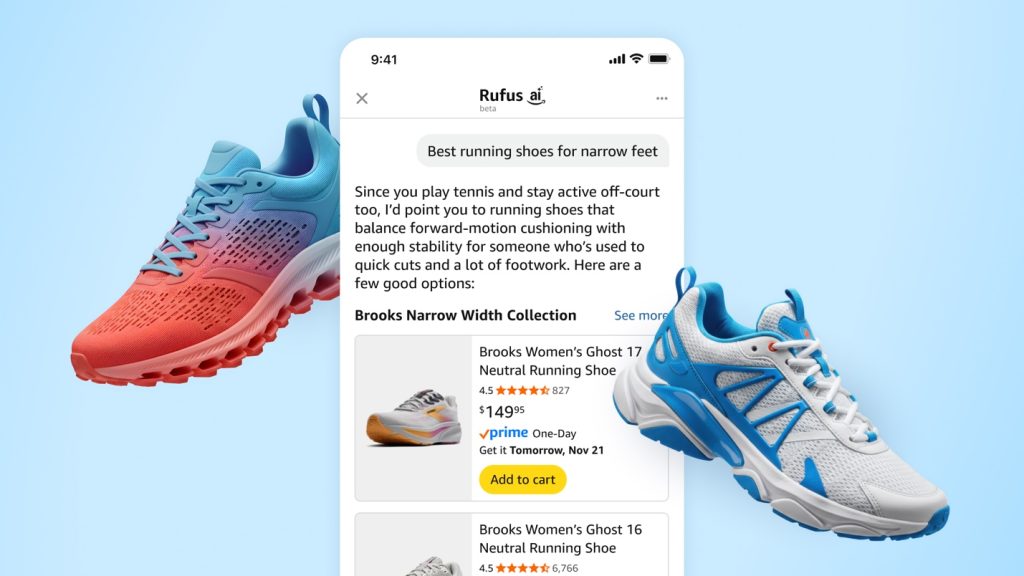
How Rufus scales conversational shopping experiences to millions of Amazon customers with Amazon Bedrock
Our team at Amazon builds Rufus, an AI-powered shopping assistant which delivers intelligent, conversational experiences to delight our customers. More than 250 million customers have used Rufus this year. Monthly users are up 140% YoY and interactions are up 210% YoY. Additionally, customers that use Rufus during a shopping journey are 60% more likely to […]

How Care Access achieved 86% data processing cost reductions and 66% faster data processing with Amazon Bedrock prompt caching
In this post, we demonstrate how healthcare organizations can securely implement prompt caching technology to streamline medical record processing while maintaining compliance requirements.

Claude Code deployment patterns and best practices with Amazon Bedrock
In this post, we explore deployment patterns and best practices for Claude Code with Amazon Bedrock, covering authentication methods, infrastructure decisions, and monitoring strategies to help enterprises deploy securely at scale. We recommend using Direct IdP integration for authentication, a dedicated AWS account for infrastructure, and OpenTelemetry with CloudWatch dashboards for comprehensive monitoring to ensure secure access, capacity management, and visibility into costs and developer productivity .
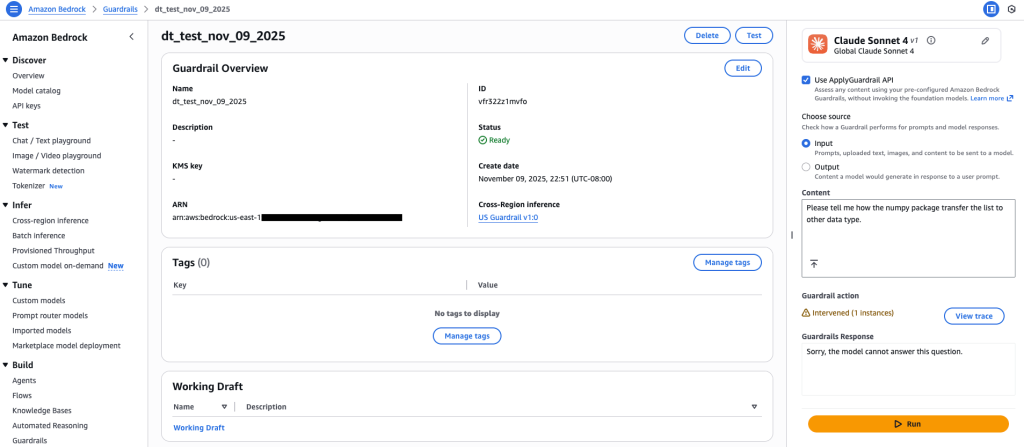
Amazon Bedrock Guardrails expands support for code domain
Amazon Bedrock Guardrails now extends its safety controls to protect code generation across twelve programming languages, addressing critical security challenges in AI-assisted software development. In this post, we explore how to configure content filters, prompt attack detection, denied topics, and sensitive information filters to safeguard against threats like prompt injection, data exfiltration, and malicious code generation while maintaining developer productivity .