Artificial Intelligence
Category: Generative AI
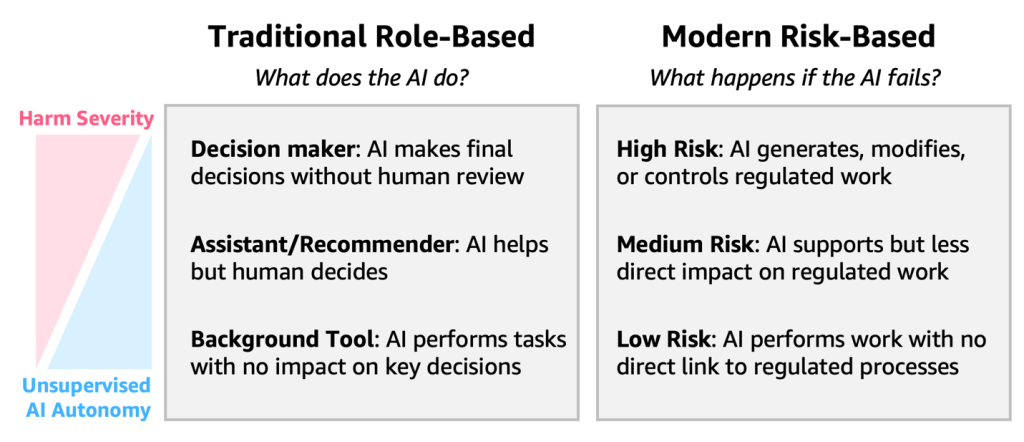
A guide to building AI agents in GxP environments
The regulatory landscape for GxP compliance is evolving to address the unique characteristics of AI. Traditional Computer System Validation (CSV) approaches, often with uniform validation strategies, are being supplemented by Computer Software Assurance (CSA) frameworks that emphasize flexible risk-based validation methods tailored to each system’s actual impact and complexity (FDA latest guidance). In this post, we cover a risk-based implementation, practical implementation considerations across different risk levels, the AWS shared responsibility model for compliance, and concrete examples of risk mitigation strategies.
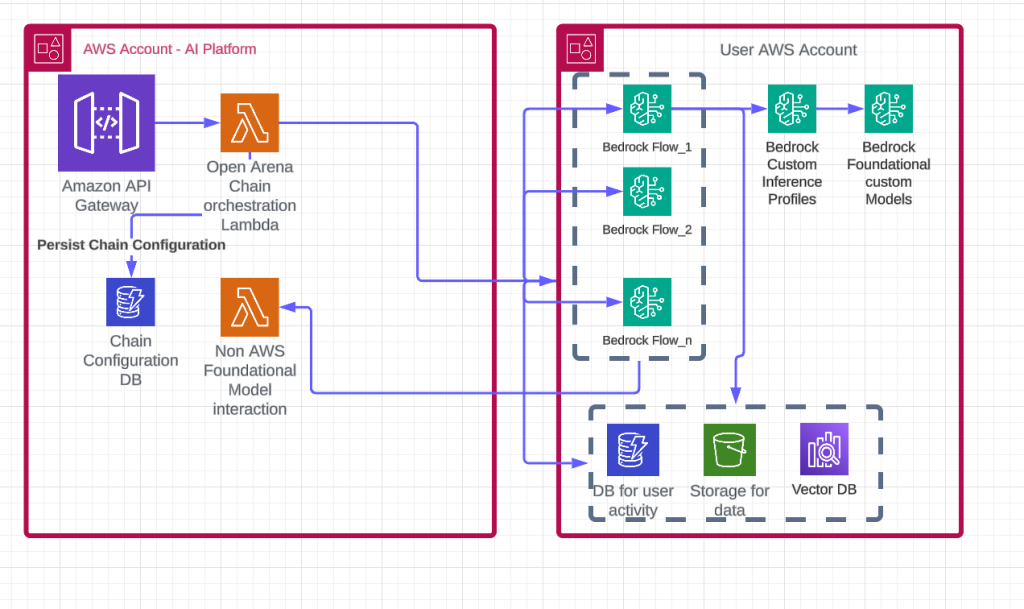
Democratizing AI: How Thomson Reuters Open Arena supports no-code AI for every professional with Amazon Bedrock
In this blog post, we explore how TR addressed key business use cases with Open Arena, a highly scalable and flexible no-code AI solution powered by Amazon Bedrock and other AWS services such as Amazon OpenSearch Service, Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, and AWS Lambda. We’ll explain how TR used AWS services to build this solution, including how the architecture was designed, the use cases it solves, and the business profiles that use it.

Introducing structured output for Custom Model Import in Amazon Bedrock
Today, we are excited to announce the addition of structured output to Custom Model Import. Structured output constrains a model’s generation process in real time so that every token it produces conforms to a schema you define. Rather than relying on prompt-engineering tricks or brittle post-processing scripts, you can now generate structured outputs directly at inference time.

Custom Intelligence: Building AI that matches your business DNA
In 2024, we launched the Custom Model Program within the AWS Generative AI Innovation Center to provide comprehensive support throughout every stage of model customization and optimization. Over the past two years, this program has delivered exceptional results by partnering with global enterprises and startups across diverse industries—including legal, financial services, healthcare and life sciences, […]
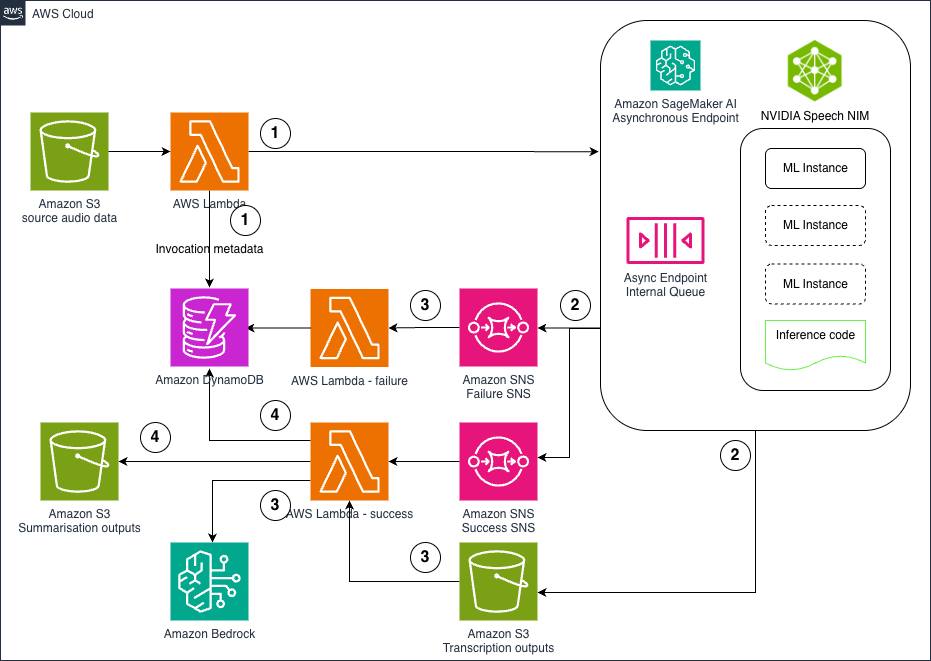
Hosting NVIDIA speech NIM models on Amazon SageMaker AI: Parakeet ASR
In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale .
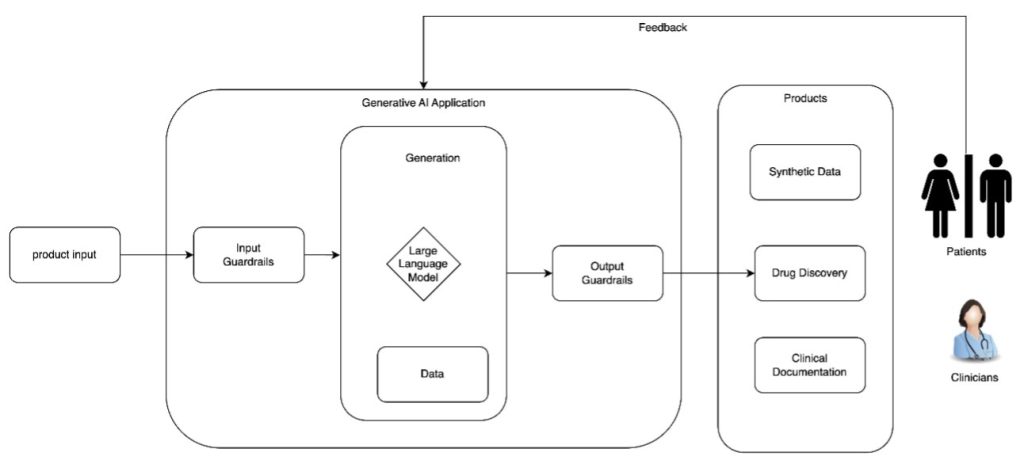
Responsible AI design in healthcare and life sciences
In this post, we explore the critical design considerations for building responsible AI systems in healthcare and life sciences, focusing on establishing governance mechanisms, transparency artifacts, and security measures that ensure safe and effective generative AI applications. The discussion covers essential policies for mitigating risks like confabulation and bias while promoting trust, accountability, and patient safety throughout the AI development lifecycle.

Beyond pilots: A proven framework for scaling AI to production
In this post, we explore the Five V’s Framework—a field-tested methodology that has helped 65% of AWS Generative AI Innovation Center customer projects successfully transition from concept to production, with some launching in just 45 days. The framework provides a structured approach through Value, Visualize, Validate, Verify, and Venture phases, shifting focus from “What can AI do?” to “What do we need AI to do?” while ensuring solutions deliver measurable business outcomes and sustainable operational excellence.

Incorporating responsible AI into generative AI project prioritization
In this post, we explore how companies can systematically incorporate responsible AI practices into their generative AI project prioritization methodology to better evaluate business value against costs while addressing novel risks like hallucination and regulatory compliance. The post demonstrates through a practical example how conducting upfront responsible AI risk assessments can significantly change project rankings by revealing substantial mitigation work that affects overall project complexity and timeline.

Build a proactive AI cost management system for Amazon Bedrock – Part 2
In this post, we explore advanced cost monitoring strategies for Amazon Bedrock deployments, introducing granular custom tagging approaches for precise cost allocation and comprehensive reporting mechanisms that build upon the proactive cost management foundation established in Part 1. The solution demonstrates how to implement invocation-level tagging, application inference profiles, and integration with AWS Cost Explorer to create a complete 360-degree view of generative AI usage and expenses.

Build a proactive AI cost management system for Amazon Bedrock – Part 1
In this post, we introduce a comprehensive solution for proactively managing Amazon Bedrock inference costs through a cost sentry mechanism designed to establish and enforce token usage limits, providing organizations with a robust framework for controlling generative AI expenses. The solution uses serverless workflows and native Amazon Bedrock integration to deliver a predictable, cost-effective approach that aligns with organizational financial constraints while preventing runaway costs through leading indicators and real-time budget enforcement.