AWS Machine Learning Blog
Category: Amazon Textract

Using Amazon Textract with Amazon Augmented AI for processing critical documents
Documents are a primary tool for record keeping, communication, collaboration, and transactions across many industries, including financial, medical, legal, and real estate. For example, millions of mortgage applications and hundreds of millions of tax forms are processed each year. Documents are often unstructured, which means the content’s location or format may vary between two otherwise […]

Amazon Textract becomes PCI DSS certified, and retrieves even more data from tables and forms
Amazon Textract automatically extracts text and data from scanned documents, and goes beyond simple optical character recognition (OCR) to also identify the contents of fields and information in tables, without templates, configuration, or machine learning experience required. Customers such as Intuit, PitchBook, Change Healthcare, Alfresco, and more are already using Amazon Textract to automate their […]
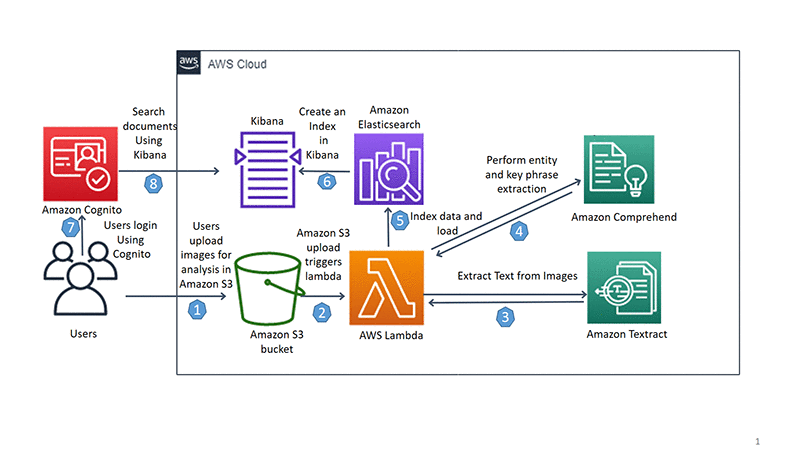
Building an NLP-powered search index with Amazon Textract and Amazon Comprehend
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Organizations in all industries have a large number of physical documents. It can be difficult to extract text from a scanned document when it contains formats such as tables, forms, paragraphs, and check boxes. Organizations have been addressing these problems […]
Amazon Textract is now HIPAA eligible
Today, Amazon Web Services (AWS) announced that Amazon Textract, a machine learning service that quickly and easily extracts text and data from forms and tables in scanned documents, is now eligible for healthcare and life science workloads that require HIPAA compliance. This launch builds upon the existing portfolio of AWS artificial intelligence services that are […]
Generating searchable PDFs from scanned documents automatically with Amazon Textract
Amazon Textract is a machine learning service that makes it easy to extract text and data from virtually any document. Textract goes beyond simple optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables. This allows you to use Amazon Textract to instantly “read” virtually any type […]
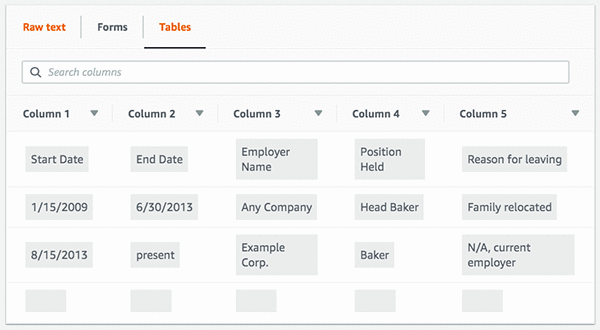
Automatically extract text and structured data from documents with Amazon Textract
September 2022: Post was reviewed for accuracy. December 2021: This post has been updated with the latest use cases and capabilities for Amazon Textract. September 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Documents are a primary tool for record keeping, communication, collaboration, and transactions across many industries, including financial, […]