Artificial Intelligence
Category: Amazon Kendra
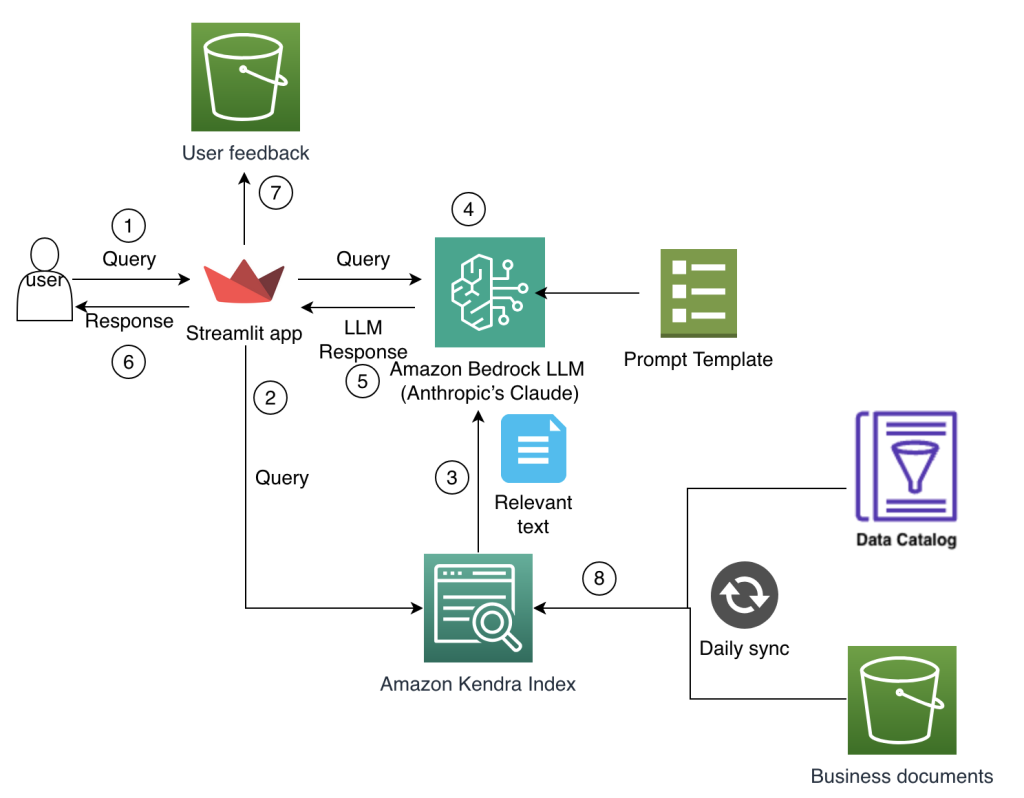
How Amazon Finance built an AI assistant using Amazon Bedrock and Amazon Kendra to support analysts for data discovery and business insights
The Amazon Finance technical team develops and manages comprehensive technology solutions that power financial decision-making and operational efficiency while standardizing across Amazon’s global operations. In this post, we explain how the team conceptualized and implemented a solution to these business challenges by harnessing the power of generative AI using Amazon Bedrock and intelligent search with Amazon Kendra.

Build a multi-interface AI assistant using Amazon Q and Slack with Amazon CloudFront clickable references from an Amazon S3 bucket
There is consistent customer feedback that AI assistants are the most useful when users can interface with them within the productivity tools they already use on a daily basis, to avoid switching applications and context. Web applications like Amazon Q Business and Slack have become essential environments for modern AI assistant deployment. This post explores how diverse interfaces enhance user interaction, improve accessibility, and cater to varying preferences.

Develop a RAG-based application using Amazon Aurora with Amazon Kendra
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLM’s knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of data preparation is required, which involves a big learning curve. In this post, we walk you through how to convert your existing Aurora data into an index without needing data preparation for Amazon Kendra to perform data search and implement RAG that combines your data along with LLM knowledge to produce accurate responses.

Introducing Amazon Kendra GenAI Index – Enhanced semantic search and retrieval capabilities
Amazon has introduced the Amazon Kendra GenAI Index, a new offering designed to enhance semantic search and retrieval capabilities for enterprise AI applications. This index is optimized for Retrieval Augmented Generation (RAG) and intelligent search, allowing businesses to build more effective digital assistants and search experiences.

Build a generative AI Slack chat assistant using Amazon Bedrock and Amazon Kendra
In this post, we describe the development of a generative AI Slack application powered by Amazon Bedrock and Amazon Kendra. This is designed to be an internal-facing Slack chat assistant that helps answer questions related to the indexed content.

Introducing document-level sync reports: Enhanced data sync visibility in Amazon Kendra
In this post, we show you how the new document-level report in Amazon Kendra provides enhanced visibility and observability into the document processing lifecycle during data source sync jobs.

Enhance your media search experience using Amazon Q Business and Amazon Transcribe
In today’s digital landscape, the demand for audio and video content is skyrocketing. Organizations are increasingly using media to engage with their audiences in innovative ways. From product documentation in video format to podcasts replacing traditional blog posts, content creators are exploring diverse channels to reach a wider audience. The rise of virtual workplaces has […]

Unleashing the power of generative AI: Verisk’s journey to an Instant Insight Engine for enhanced customer support
This post is co-written with Tom Famularo, Abhay Shah and Nicolette Kontor from Verisk. Verisk (Nasdaq: VRSK) is a leading data analytics and technology partner for the global insurance industry. Through advanced analytics, software, research, and industry expertise across over 20 countries, Verisk helps build resilience for individuals, communities, and businesses. The company is committed […]

The journey of PGA TOUR’s generative AI virtual assistant, from concept to development to prototype
This is a guest post co-written with Scott Gutterman from the PGA TOUR. Generative artificial intelligence (generative AI) has enabled new possibilities for building intelligent systems. Recent improvements in Generative AI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval. Given the data sources, LLMs provided tools […]

Build generative AI agents with Amazon Bedrock, Amazon DynamoDB, Amazon Kendra, Amazon Lex, and LangChain
Generative AI agents are capable of producing human-like responses and engaging in natural language conversations by orchestrating a chain of calls to foundation models (FMs) and other augmenting tools based on user input. Instead of only fulfilling predefined intents through a static decision tree, agents are autonomous within the context of their suite of available […]