AWS Machine Learning Blog
Beyond text: How Spokata uses Amazon Polly to make news and information universally accessible as real-time audio
This is a guest blog post by Zack Sherman, Founder of Spokata. In their own words, “Spokata is an automated audio platform for publishers of text-based news and information. Our software summarizes text from any publisher website, or API, and transforms it into short streaming audio, in real-time. As new text content is created we make the audio available on a publisher’s website and mobile apps, while simultaneously distributing to Amazon Alexa and terrestrial radio.”
Just as television transitioned from black and white to color, the web has been moving from a text-based medium to one dominated by sound and vision. Accordingly, content creation has both exploded and changed. Publishers of all types are struggling through this transition as they try to meet the demands of users while keeping their business models intact.
On-demand audio is attracting significant interest from publishers as mobile listening grows and in-car technology begins to disrupt traditional radio. This trend is most visible in the mainstream adoption of podcasts. But podcasts are just the beginning of a rapidly emerging, and diverse, ecosystem of new digital audio formats. Amazon Echo and advanced text-to-speech services such as Amazon Polly are enabling the creation of these new audio products.
In this blog post we describe how Spokata leverages these Amazon technologies to make text-based news and information universally accessible as real-time audio.
What if all the text on the internet were the raw material for a new kind of audio experience?
Spokata capitalizes on the space where on-demand audio excels, but it goes further — into the smallest possible moments — when you only have a minute or two. Listening to a single news article can take more than five minutes, so we created a new kind of short audio format. We studied millions of news articles to develop a summarization methodology that works automatically and with near perfect accuracy across multiple types of content.
The Spokata SaaS platform summarizes text from any publisher’s website and transforms it into short streaming audio, in real time. As new text content is created, the Spokata API makes the audio available on a publisher’s website and mobile apps, while simultaneously distributing to Amazon Echo and other smart devices. The applications for our technology cover a broad range of content types: news, traffic, weather, movie reviews, recipes, educational, or training content — virtually any form of information that exists in text.
Spokata gives users real-time access to trusted sources of information, and publishers an automated, high margin, method of content creation. The only requirement for using Spokata is to have a website and insert a few lines of code – our platform takes care of the rest.
The core mission at Spokata is to create media, using software, and pass those efficiencies along to content creators. So, we needed a fresh approach to the fundamental economics of media production. Digital video costs upwards of $1000 per minute. Podcast budgets can certainly exceed that cost on a per episode basis, depending on production value. In order to compete, we felt strongly that Spokata’s audio should cost pennies to produce, not dollars. Text-to-speech allows these assets to be leveraged into real-time audio with almost no effort and for a fraction of the cost to produce video, podcasts, or even text.
Facing technological obstacles
At the outset, we faced a number of technological obstacles to fulfilling this mandate.
Scale
There are thousands of news providers, publishing thousands of articles every month. At the beginning we were unsure that a viable business could be built with such large requirements for processing and delivery. Predictable pricing for storage, content delivery, and text conversion allow us to forecast our costs and plan for a service that can scale to serve millions of users and process millions of articles.
Delivery
Automatic real-time delivery is another cornerstone of our platform. We combine the low latency of Amazon CloudFront with the flexibility of Amazon EC2 to ensure that our product is globally available and that we can add resources as they are needed. These solutions also allow us to continually add more audio endpoints so publishers can reach their audience everywhere they are listening.
Voice quality
The right text-to-speech solution for Spokata has to deliver quality beyond just sounding “less like a machine.” At the most fundamental level, the wide variety of content types coming from thousands of publishers requires massive adaptability. Emphasis, intonation, and pronunciation all need to operate with high accuracy to create an experience with which people want to engage. Speed is another big concern. Audio files have to be generated and made available for streaming near instantaneously. We evaluated every solution on the market and found Amazon Polly outperformed on all of these qualitative attributes.
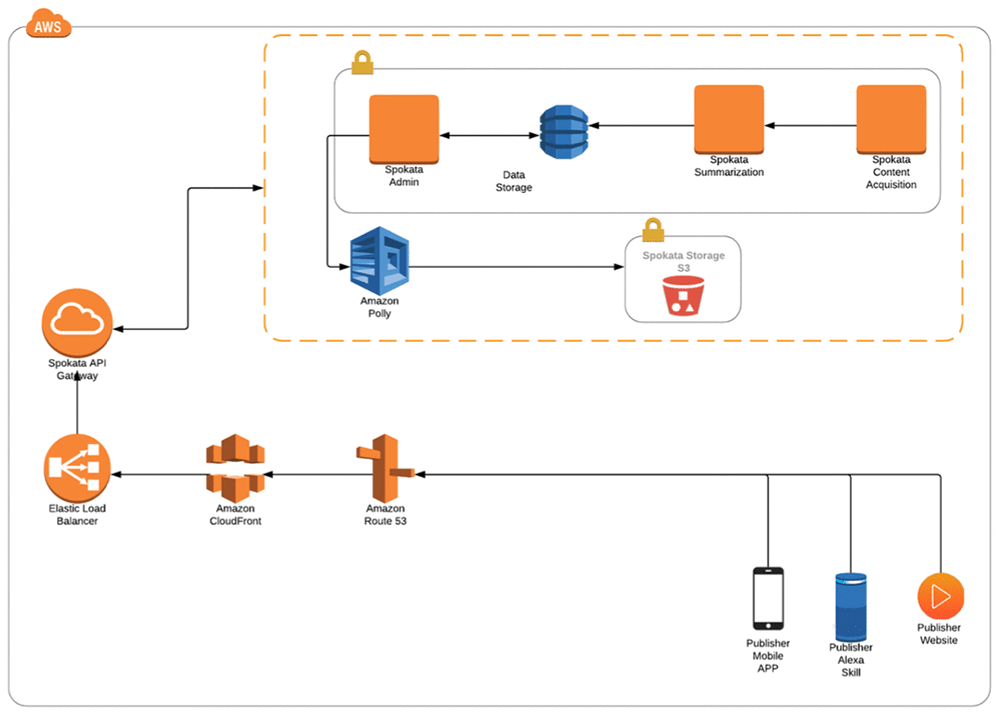
The Solution
To acquire text content, we provide publishers with a simple JSON structure so we receive their text content as it is published.
Incoming API Call
After their API endpoint is set up, a few lines of JavaScript activate our player on the relevant article page.
Spokata Player Code
The original article text is passed through our summarization algorithm and reduced by 80 percent creating a short, fact-based summary. All that information is then stored in our database in text form.
The summarizations are passed to Amazon Polly where MP3 files are generated and stored in our Amazon S3 bucket. Our outgoing API call then makes the necessary data and audio available for streaming on each of the relevant endpoints.
Outgoing API Call
We built our own content management system to administer the platform and consolidate all of our data. Some publishers might want audio delivered just to their mobile app or just to the web. From here we can manage these settings, create custom “intros” and “outros,” monitor our use of resources in real time, and see how content is performing using our analytics panels.
Listen now to an audio sample with custom intro and outro.
| Listen now Voiced by Amazon Polly |
As we continue to roll out Spokata to publishers, we have a number of development efforts under way. Amazon Polly allows us to further customize our audio output using Speech Synthesis Markup Language (SSML) and lexicons. We are building this into our workflow to make our audio even more precise.
Automated translation tools are becoming increasingly accurate. We are experimenting with Amazon Translate so publishers can reach audiences in their native language. The next update to the Spokata platform integrates background music and “avatars,” which introduce themselves at the beginning of the stream.
Listen now to an audio sample with background music and avatar intro.
| Listen now Voiced by Amazon Polly |
The quality of text-to-speech has rapidly advanced since we began development of the platform. We anticipate that Amazon Polly will soon make text-to-speech largely indistinguishable from human voice–allowing us to reach an even larger audience with the best listening experience.
Conclusion
Just a few years ago, the massive gap (in terms of consumption and revenue) between digital video and television seemed insurmountable. The fact that digital video has now eclipsed traditional forms of consumption paints a bright picture for the near-term evolution of the on-demand audio marketplace. Radio, in particular, has yet to see the type of disruption we are witnessing now in video. This change has certainly commenced and will accelerate rapidly over the coming year.
Accurate, real-time delivery of news and information is a critical function for the technology community to solve. By making this content easier to consume, we aspire to drive informed decision making while enabling publishers to thrive through yet another digital transition.