Artificial Intelligence

Author: Shreyas Subramanian
Shreyas Subramanian is a Principal data scientist and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.

Intelligently search your Jira projects with Amazon Kendra Jira cloud connector
July 2023: This post was reviewed for accuracy. Organizations use agile project management platforms such as Atlassian Jira to enable teams to collaborate to plan, track, and ship deliverables. Jira captures organizational knowledge about the workings of the deliverables in the issues and comments logged during project implementation. However, making this knowledge easily and securely […]
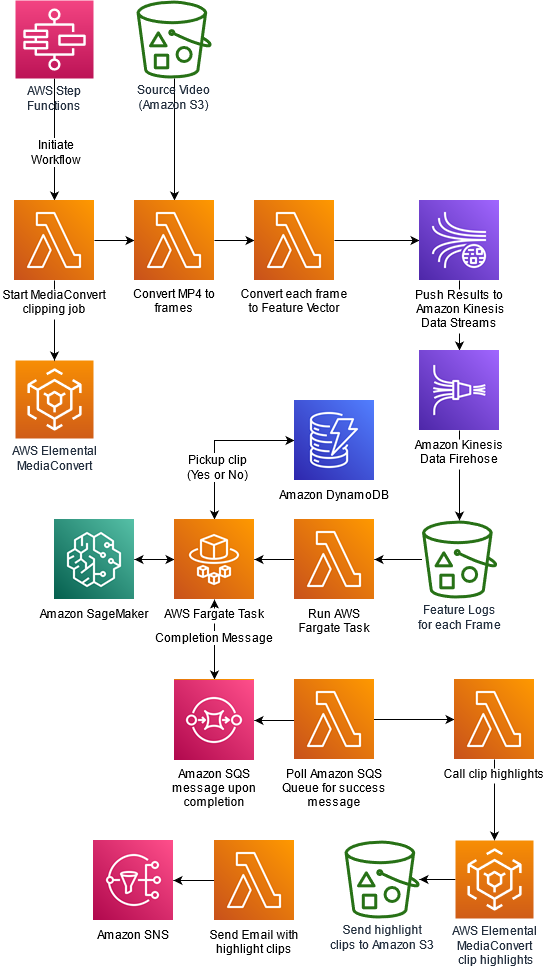
Automatically detect sports highlights in video with Amazon SageMaker
July 2023: Please refer to the Media Replay Engine (MRE) solution presented in this Github repo instead, for the latest and more efficient solution for this use case. MRE is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live and video-on-demand (VOD) content. Extracting highlights from a […]

Define and run Machine Learning pipelines on Step Functions using Python, Workflow Studio, or States Language
May 2024: This post was reviewed and updated for accuracy. You can use various tools to define and run machine learning (ML) pipelines or DAGs (Directed Acyclic Graphs). Some popular options include AWS Step Functions, Apache Airflow, KubeFlow Pipelines (KFP), TensorFlow Extended (TFX), Argo, Luigi, and Amazon SageMaker Pipelines. All these tools help you compose […]

Build reusable, serverless inference functions for your Amazon SageMaker models using AWS Lambda layers and containers
July 2023: This post was reviewed for accuracy. Please refer to Deploying ML models using SageMaker Serverless Inference, a new inference option that enables you to easily deploy machine learning models for inference without having to configure or manage the underlying infrastructure. In AWS, you can host a trained model multiple ways, such as via […]
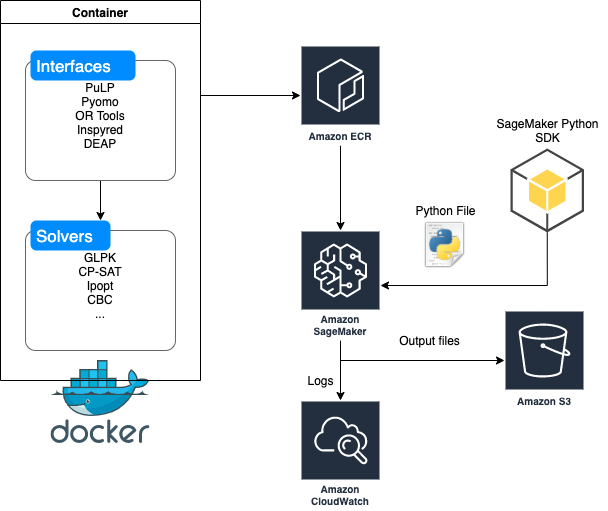
Solving numerical optimization problems like scheduling, routing, and allocation with Amazon SageMaker Processing
July 2023: This post was reviewed for accuracy. In this post, we discuss solving numerical optimization problems using the very flexible Amazon SageMaker Processing API. Optimization is the process of finding the minimum (or maximum) of a function that depends on some inputs, called design variables. This pattern is relevant to solving business-critical problems such […]

Running on-demand, serverless Apache Spark data processing jobs using Amazon SageMaker managed Spark containers and the Amazon SageMaker SDK
July 2023: This post was reviewed for accuracy. Apache Spark is a unified analytics engine for large scale, distributed data processing. Typically, businesses with Spark-based workloads on AWS use their own stack built on top of Amazon Elastic Compute Cloud (Amazon EC2), or Amazon EMR to run and scale Apache Spark, Hive, Presto, and other […]
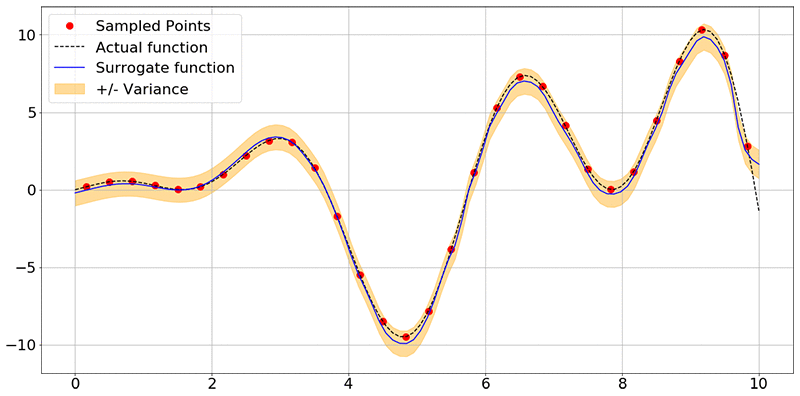
Building a deep neural net–based surrogate function for global optimization using PyTorch on Amazon SageMaker
July 2023: This post was reviewed for accuracy. Optimization is the process of finding the minimum (or maximum) of a function that depends on some inputs, called design variables. Customer X has the following problem: They are about to release a new car model to be designed for maximum fuel efficiency. In reality, thousands of […]
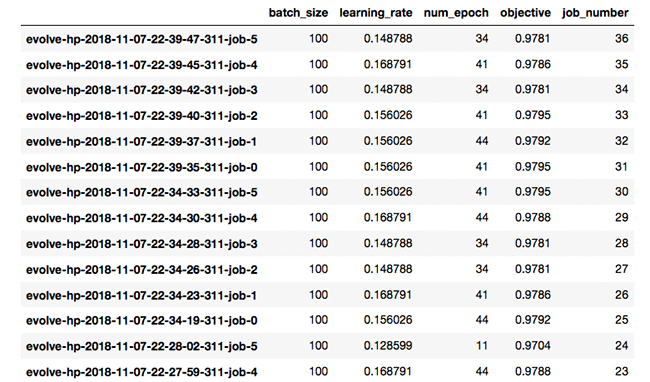
Bring your own hyperparameter optimization algorithm on Amazon SageMaker
July 2023: This post is outdated. We recommend referring to Amazon SageMaker Automatic Model Tuning now supports three new completion criteria for hyperparameter optimization for the latest solution. In this blog post, we’ll discuss how to implement custom, state-of-the-art hyperparameter optimization (HPO) algorithms to tune models on Amazon SageMaker. Amazon SageMaker includes a built-in HPO […]