AWS for Industries
Liveness Detection to Improve Fraud Prevention in Financial Institutions with Amazon Rekognition
Note: We recommend customers to explore Amazon Rekognition Face Liveness, a new feature to deter fraud in facial verification, that is now generally available. Face Liveness detects spoofs presented to the camera (e.g. printed photos, digital photos or videos, or 3D masks) and spoofs that bypass the camera (e.g. pre-recorded real or deepfake videos). Face Liveness returns a high-quality selfie frame for downstream Amazon Rekognition Face Matching or Age Estimation analysis. Customers can easily add Face Liveness to their React web, native iOS, and native Android applications using open-source AWS Amplify SDKs. Face Liveness automatically scales up or down based on demand and customers pay only for the face liveness checks performed. No infrastructure management, hardware-specific implementation, or machine learning (ML) expertise is required. Face Liveness uses ML models trained on diverse datasets to support high accuracy across user skin tones, ancestries, and devices. Learn more at thinkwithwp.com/rekognition/face-liveness

Facial recognition is one of the common forms of biometrics employed across industries for fraud prevention. Fundamentally, facial recognition uses algorithms to distinguish an individual user’s unique features from those of similar faces in a “gallery” lineup. Facial biometrics are increasingly popular with financial institutions that are trying to balance between enhanced fraud prevention and a high-quality user experience.
In a previous blog post, we outlined a reference architecture for improving fraud prevention; onboarding workflows; registering customers; and payments authorization. It centered around “liveness detection,” which uses anti-spoofing technology to validate that a user is a live person. It’s employed on both mobile and web applications.
This blog post describes, step by step, how financial institutions can build a liveness detection solution to improve fraud prevention in payment-authorization systems. It also includes implementation code to facilitate deployment.
The architecture’s core approach prompts users to perform a challenge. For instance, users must move their nose to a randomly defined target position shown on the screen. This triggers a series of verification processes that validate if:
- There was an image of one—and only one—face captured;
- A user kept his or her face at the center of the image and at the appropriate distance;
- A user moved his or her nose to the target position;
- A user performed a head rotation movement, mimicking a three-dimensional system.
Advantages
This version of the liveness detection architecture lets financial institutions take advantage of the following characteristics:
- Face proximity check
- A new API to upload user images (frames) directly, instead of first uploading them to an Amazon S3 bucket
- JSON Web Token (JWT) verification throughout the challenge signed with a secret stored in AWS Secrets Manager
- Random definition of the nose target position that is easy to reach
- Utilization of Euclidean distance and head-rotation to verify challenge
- Frame upload in the background byclient (API application) during the challenge (for optimization)
- Face tracking that checks the position inside the bounding-box
Architecture
We used Amazon Rekognition to detect facial details that verify the challenge. The architecture is serverless and is composed of the following services: Amazon API Gateway, AWS Lambda, Amazon DynamoDB, Amazon Simple Storage Service (S3), and AWS Secrets Manager.
The final challenge verification runs on the cloud. The architecture also allows you to run the challenge locally on the client so that you can provide real-time feedback to your end users as they interact with the device camera.
This is a diagram of the architecture with a description of its components:

- Client:The designated API application captures user images (frames), runs the challenge locally, and invokes Amazon API Gateway to verify the challenge in the cloud
- Amazon API Gateway: REST HTTP API invoked by the client
- AWS Lambda: Function, invoked by Amazon API Gateway, that implements the challenge verification in the cloud
- Amazon DynamoDB: Database that stores challenge data
- Amazon S3:Stores user images
- Amazon Rekognition: Deep learning-powered image recognition service that analyses user images
- AWS Secrets Manager: Service that stores the secret used to sign tokens
Liveness detection challenge workflow
Here are additional details of the challenge workflow:
Starting a new challenge
When the user initiates a new action that requires a challenge, this challenge is initiated by the client app. The client invokes the API, passing the user’s ID and image dimensions from the device camera. The API then returns the challenge parameters, so the client can prompt the user with instructions on how to perform the challenge. See the details below:

- User initiates the challenge on the client.
- The client issues a POST HTTP request to the
/startAPI endpoint, passing the user ID and the device camera image dimensions. API Gateway forwards the request to the challenge function. - The challenge function receives the request and generates coordinates for the face area and the random nose-target position, and analyzes the image’s dimensions. It also generates a challenge ID and a security token, signed with a secret stored in AWS Secrets Manager. The challenge function stores the challenge parameters in the challenges table (Amazon DynamoDB) and returns them to the client.
- The client receives the challenge parameters and displays the device camera preview to the user, along with instructions on how to perform the challenge.
Performing the challenge
As users interact with the device camera, the client runs the challenge locally, uploading frames, one by one, capped by a configurable rate. See the details below:

- A user interacts with the device camera, as it captures images.
- The client issues a PUT HTTP request to the
/{challengeId}/framesAPI endpoint, passing the image and the token. The API Gateway forwards the request to the challenge function. - The challenge function validates the token. If it is valid, it stores the image in the frames bucket (Amazon S3). It also updates the challenge record in the challenges table (Amazon DynamoDB) with the image URL.
These steps are repeated for the other images, until the challenge finishes locally (the user moves his/her nose to the target area or the challenge times out).
Verifying the challenge
After users successfully complete challenges locally, the client invokes the API for the final verification in the cloud. See the details below:

- The user follows the instructions and completes the challenge (that is, the user moves his/her nose to the target area). However, at this point, the challenge is completed only on the client.
- The client issues a POST HTTP request to the
/{challengeId}/verifyAPI endpoint, passing the token, to start the challenge verification in the cloud. API Gateway forwards the request to the challenge function. - The challenge function validates the token. If it is valid, it looks up the challenge data in the challenges table(Amazon DynamoDB) and invokes Amazon Rekognition to analyze the images stored in the frames bucket (Amazon S3). The challenge function then verifies the challenge. The final result (success or fail) is returned to the client.
- The client displays the final result to the user.
During the final verification, the challenge function invokes, for each frame image, the DetectFaces operation from Amazon Rekognition image. For each face detected, the operation returns the facial details. From all details captured from DetectFaces operation, we use the bounding box coordinates of the face, facial landmarks (nose coordinates), and pose (face rotation).
The challenge function needs those details to detect some spoofing attempts like photos, 2D masks and videos, following the workflow depicted below. This reference architecture for liveness detection cannot detect 3D masks, or identify the texture. You can also do verification using other captured details, like emotional expressions; general attributes (for example: smiles, open eyes); image quality; and demographic data.

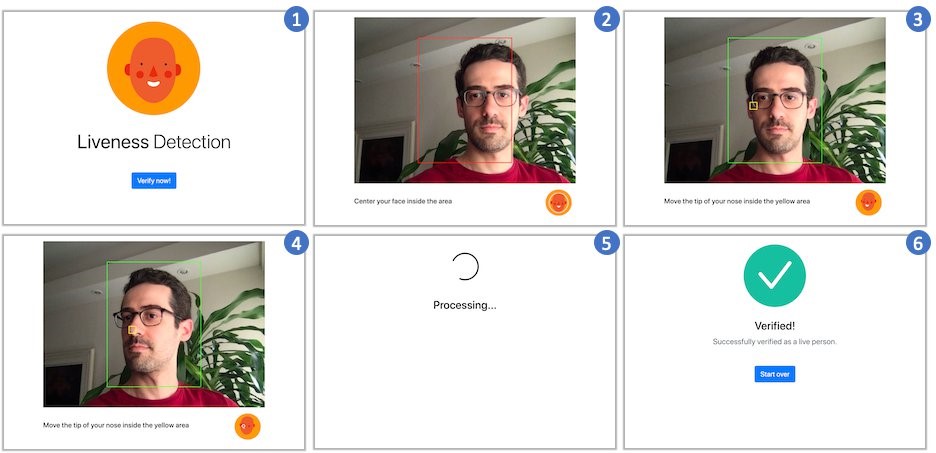
Here are some screenshots of a user performing the challenge:
Please be aware of some considerations about this sample implementation:
- The solution provided here is not secure against all spoofing. Therefore, before deploying to production, thoroughly test it to validate if it meets your security requirements.
- You can enhance the verification logic to make your solution more robust against spoofing. For instance, you can check if the positions of the nose landmark change in a continuous and linear manner from one frame to the next.
- The architecture does not include user authentication, as it considers the user as already logged in before initiating the liveness detection challenge. If needed, you can add facial authentication into the user authentication workflow, using Amazon Cognito and Amazon Rekognition. For more information, please refer to this blog post.
- Depending on your requirements, you can remove the S3 bucket from the architecture and, instead of storing the user images, call Amazon Rekognition as soon as the client sends an image. You can then store the result in the DynamoDB table and use it during the verification step. Another option is to use the IndexFaces operation, from Amazon Rekognition, to detect faces in an image and keep the information about facial features that are detected in a gallery collection.
Artifacts
We provide a working implementation of the reference architecture, written in Python, along with a JavaScript web client application. Thanks to the decoupled nature of this architecture, you can easily apply the same logic to create other clients, including native mobile apps.
For the full code, please refer to the GitHub repository. You can clone, change, deploy, and run it yourself.
Prerequisites
The implementation is provided in the form of an AWS Serverless Application Model (SAM) stack template. In order to deploy it to your AWS account, you need to install and configure the AWS CLI and AWS SAM CLI. The application build process also requires the installation of Docker and Node.js.
Cleanup
If you don’t want to continue using the application, take the following steps to clean up its resources and avoid further charges.
- Empty the Amazon S3 buckets created by the stack, deleting all contained objects
- Delete the SAM stack on the AWS CloudFormation console
Conclusion
In this blog post (part 2 of 2), we walked you through a complete liveness detection architecture with Amazon Rekognition and other serverless components. Financial institutions can use it to add facial recognition to systems that require stronger authentication. The architecture is also amenable to extensions and improvements.
It’s worth highlighting some recommendations and characteristics about this architecture:
- 1–2 seconds for response time (customer perception);
- 5–15 FPS (frames per second) captured is enough to detect liveness;
- The size of each frame is approximately 15-20 kB;
- Possible to avoid spoofing linked to photos, mobile photos, videos, ID, and 2D masks;
- Able to detect liveness—even when using medical masks and sunglasses;
- A serverless architecture, and the processing for each frame costs less than $0.01 USD.
The starting point for building the solution was to attend to a growing demand for advanced fraud prevention from a majority of Latin American financial institutions. We’re able to deliver on this through cross-sectional work by the AWS R&D Innovation LATAM team and the solutions architect focused on financial services (LATAM).
To learn more, see the Liveness Detection Framework, a solution that helps you implement liveness detection mechanisms into your applications by means of an extensible architecture. The solution’s architecture is similar to the architecture described in this blog post.