AWS for Industries
How a generative AI Q&A app can be used in the oil and gas sector to improve the speed and accuracy of information retrieval from documents
The oil and gas (O&G) sector, known for its stringent regulations and complex operations, relies heavily on a vast array of documentation. From engineering blueprints to compliance reports, these documents form the backbone of daily operations, project management, and regulatory adherence.
Key document categories in the industry include:
- Engineering documents: technical specifications, design drawings, and equipment manuals.
- Business documents: contacts, financial reports, and strategic plans.
- Project documents: schedules, risk assessments, and progress reports.
- Regulatory and compliance documents: safety protocols, environmental impact assessments, and permit applications.
- Operational documents: standard operating procedures, maintenance logs, and production reports.
Business challenge
O&G professionals frequently need to query the previously mentioned categories of documents and extract accurate information to fulfill various business and technical needs. Traditional keyword searches often fall short in retrieving accurate information in a timely manner, creating a demand for a semantic search with natural language query capabilities.
Foundation models (FMs) excel at natural language processing (NLP), question answering, and image analysis. Although FMs possess broad knowledge, their effectiveness can be enhanced through Retrieval Augmented Generation (RAG). RAG improves response accuracy by incorporating information from proprietary data sources, such as engineering documents belonging to an O&G company.
End-to-end RAG workflow with Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases offers a fully managed solution for implementing RAG workflows in generative AI applications. When a user submits a query, the knowledge base searches proprietary data to answer the query, performing a semantic search. Then, the retrieved information is used to improve generated responses. This technology enables organizations to build custom RAG-based applications that use their proprietary information assets. This improves the relevance and accuracy of AI-generated answers in specialized domains such as O&G.
O&G customers have a vast amount of un-structured multimodal data (text, visuals, charts, images, and tables). They can use Amazon Bedrock Knowledge Bases to analyze and extract insights from both textual and visual data, such as images, charts, diagrams, and tables. It generates semantic embeddings using the selected embedding model and stores them in the chosen vector store.
Solutions architecture
In this post we discuss the solutions architecture to build a Q&A generative AI app that can be integrated with existing line-of-business O&G applications. The Q&A app uses RAG-based customization to enhance the performance of a pre-trained FM, and deliver more relevant, accurate, and customized responses matching the use case. The RAG workflow is implemented using Amazon Bedrock Knowledge Bases.
AWS services used
- Amazon API Gateway
- AWS Lambda
- Amazon Bedrock Knowledge Bases with Amazon Titan embedding model and Anthropic Claude LLM
- Amazon OpenSearch Serverless
- Amazon S3

Architecture flow
The architecture flow has two main components: data ingestion flow and Q&A generative AI flow
Data ingestion flow (used to pre-process unstructured data)
1. The ingestion flow starts when a company document is uploaded to the S3 bucket, which is configured as the data source in Amazon Bedrock Knowledge Bases.
2. Documents are split into manageable chunks by Amazon Bedrock for efficient retrieval, and the chunks are converted to vector embeddings using an embeddings model, such as the Amazon Titan Multimodal Embeddings G1 model.
3. The embeddings are written to the Amazon OpenSearch Serverless vector database and indexed, while maintaining a mapping to the original document
Q&A generative AI workflow
4. The Q&A generative AI workflow starts when a company user accesses the Q&A app, as shown in the following diagram, and asks a question using natural language.
a. The Q&A app samples shown in the following figure can be easily deployed in an AWS account and made accessible through a web browser for authorized users by using the AWS Samples GitHub repo.
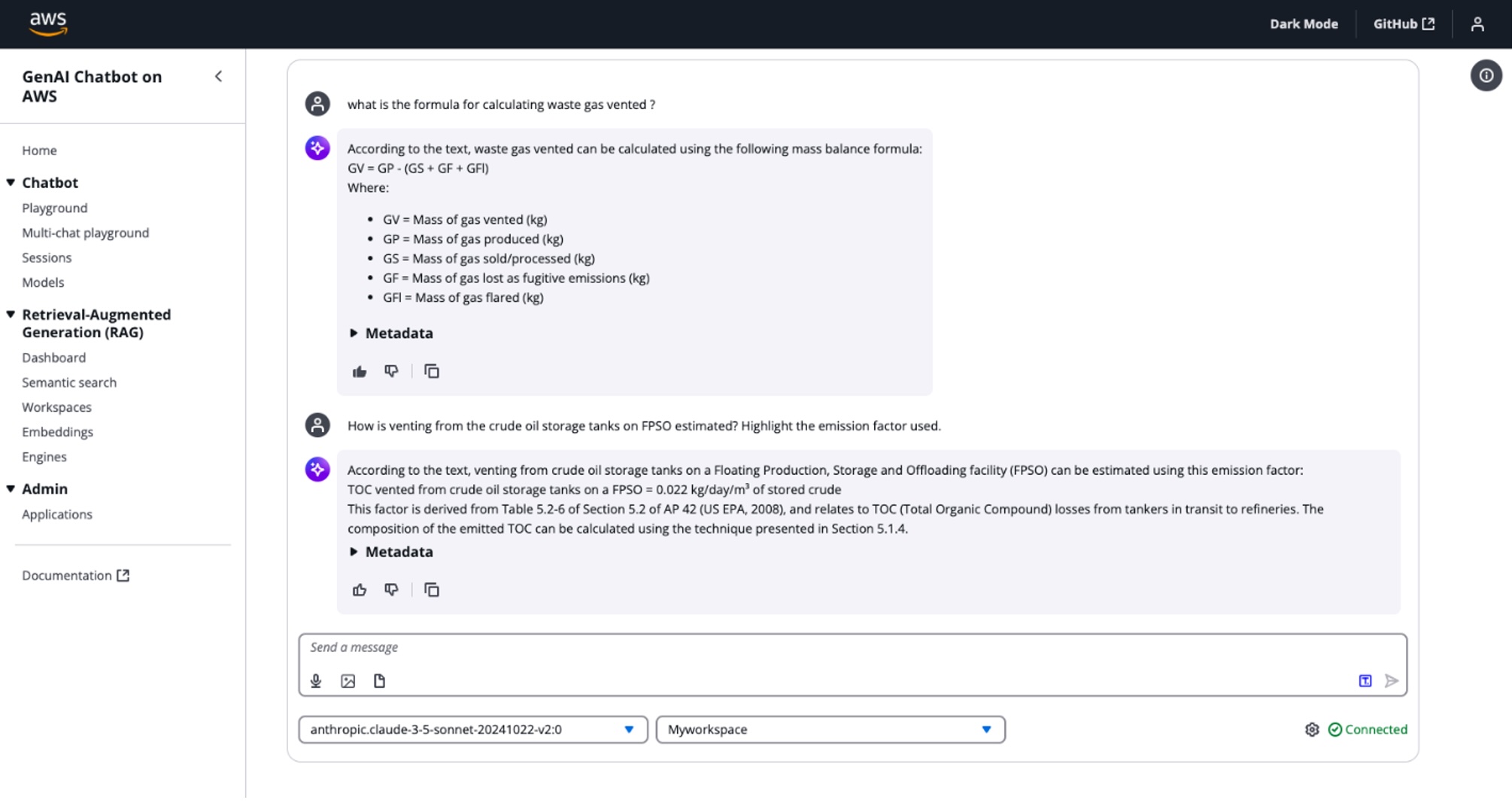

5. The Q&A app invokes a REST API and the query is sent (as a prompt) to the API Gateway, which passes it to the Lambda function as an event. The Lambda event calls the RetrieveAndGenerate API in the Amazon Bedrock Knowledge Bases to query the knowledge base and generate responses from the information it retrieves.
6. Amazon Bedrock Knowledge Bases uses an embeddings model, such as the Amazon Titan Multimodal Embeddings G1 model, to convert the user’s query to a vector.
7. The vector index of the Amazon OpenSearch serverless vector database is queried to find chunks that are semantically similar to the user’s query by comparing document vectors to the user’s query vector.
8. The prompt is augmented with the context from the chunks that are retrieved from the vector index.
9. The prompt, alongside the context, is sent to the LLM, such as Anthropic’s Claude Sonnet 3.5 LLM, to generate a response for the user.
10. The generated response (answer to the user query) is passed on to the Q&A app and the Lambda function.
11. The answer is sent to the user.
Conclusion
Speed and accuracy of retrieved information are critical for making sound business decisions in the O&G sector. In this post we showed the solution architecture for a Q&A generative AI app that uses Amazon Bedrock Knowledge Bases as the fully managed RAG solution with multimodal data support. This provides you with the flexibility to customize and improve the retrieval accuracy of the Q&A application. The information retrieved from Amazon Bedrock Knowledge Bases is provided with citations and source attribution to improve transparency and minimize hallucinations.
RAG, fine-tuning, and continuous pre-training represent different levels of FM customization. RAG is the lightest approach, providing context at inference time without modifying the model weights. Fine-tuning adapts an existing model’s behavior through further training on specific tasks or domains with labelled data, while continuous pre-training is the most intensive method, further training the base model on new unlabeled data to expand its fundamental knowledge. Choose RAG for quick deployment and maintaining model freshness using proprietary data, fine-tuning for specific tasks or output formats, such as summarizations tasks, and continuous pre-training when you need the model to deeply learn new domain-specific knowledge.
For more information, see the Amazon Bedrock User Guide Developer Guide and Amazon Bedrock API Reference.