AWS HPC Blog
Whisper audio transcription powered by AWS Batch and AWS Inferentia
Update [May 2025]: An enhanced version of this solution was published that offers improved performance and additional optimizations. Check out our new post “Enhanced Performance for Whisper Audio Transcription on AWS Batch and AWS Inferentia” to learn about the latest improvements.
 OpenAI’s Whisper model is a popular and highly accurate automatic speech recognition (ASR) model, based on the transformer architecture. It’s released under the MIT license and available for commercial use.
OpenAI’s Whisper model is a popular and highly accurate automatic speech recognition (ASR) model, based on the transformer architecture. It’s released under the MIT license and available for commercial use.
Many customers want to host the Whisper model on AWS but don’t need real-time or continuous online inference. This is great, because it opens an opportunity for reducing cost by processing audio as a batch workload asynchronously using AWS Batch. Customers can go even further to tune their cost by using AWS Inferentia – a custom silicon option built by AWS. (If you do need real-time or continuous online inference, check out our previous blog post on that topic).
In this post, we’ll explore how to set up and deploy a scalable, performant, and cost-efficient solution for batch audio transcription using the Whisper model deployed on demand using an AWS Batch compute environment – powered by AWS Inferentia. We’ll describe how to implement this solution as an event-driven architecture, triggering the pipeline automatically when audio files arrive in Amazon Simple Storage Service (Amazon S3). We’ll describe how to build a Docker image that includes a script to prepare audio files for inference using AWS Inferentia. And we’ll provide you with a cloud formation template that can automate the deployment of this solution so you can start experimenting in a few minutes.
Solution Overview
AWS Batch
AWS Batch is a fully managed batch computing service that plans, schedules, and runs your containerized batch ML, simulation, and analytics workloads across the full range of AWS compute offerings, such as Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Services (Amazon EKS), AWS Fargate, and Amazon EC2 Spot or On-Demand Instances. AWS Batch lets developers, scientists, and engineers across industries efficiently run hundreds of thousands of batch computing jobs while optimizing compute resources.
AWS Inferentia overview
Amazon Elastic Compute Cloud (Amazon EC2) Inf2 instances are purpose-built for deep learning (DL) inference. They deliver high performance at the lowest cost in Amazon EC2 for generative artificial intelligence (AI) models, including large language models (LLMs) and vision transformers. You can use Inf2 instances to run your inference applications for text summarization, code generation, video and image generation, speech recognition, personalization, fraud detection, and more.
Inf2 instances are powered by AWS Inferentia2, the second-generation AWS Inferentia chip. The AWS Neuron SDK helps developers deploy models on AWS Inferentia chips by integrating natively with frameworks like PyTorch and TensorFlow.
Overall architecture
Next, let’s review the architecture for our solution. we’ve made the code and step-by-step guide for implementing this available in GitHub.
Figure 1 below shows the event-driven Whisper audio transcription pipeline solution using Amazon EventBridge and AWS Batch. Since Batch creates a containerized compute environment, it requires us to build and stage a container image in Amazon Elastic Container Registry (Amazon ECR). In the Batch job definition, we specify the container image, the Amazon Machine Image (AMI), and Amazon EC2 instance type.
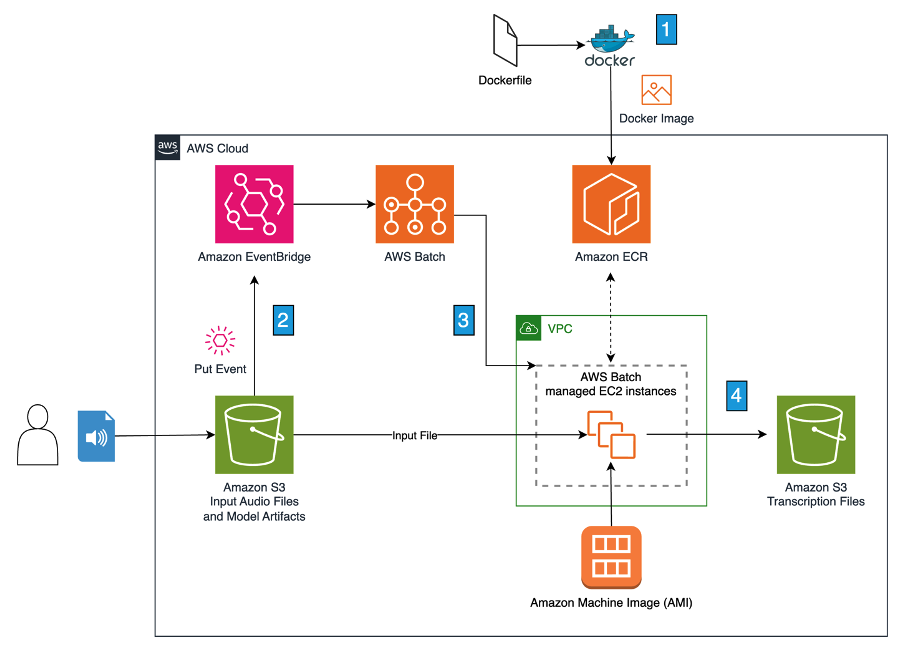
Figure 1. Event-driven audio transcription pipeline with Amazon EventBridge and AWS Batch
We’ll discuss each numbered architecture feature.
- Build docker image and push to Amazon ECR – We build the docker image at design time and push it to ECR. The docker image includes all the libraries and python script code to retrieve the model artifacts and the audio file from Amazon S3 and process it using the Whisper model encoder and decoder.
- Add audio transcription job to AWS Batch job queue on file upload – When an audio file is uploaded to Amazon S3 in the designated Bucket and folder, EventBridge captures the PutEvent and triggers Batch to add the file to its job queue.
- Batch launches compute environment to process queued jobs – If there’s no active compute environment (CE), Batch will provision a managed CE to process each job in the queue until the queue is empty. The CE is created using an Amazon EC2 Inf2 instance, an AMI that includes the Neuron SDK libraries, and the container image uploaded to ECR in the first step. These configurations are defined in the Batch Job Definition file.
- Batch processes job and writes transcription to Amazon S3 output location – The compute environment processes each audio file and writes a transcription file to an Amazon S3 bucket. Once the job queue is empty, Batch shuts down the instances in the CE.
Next, we’ll demonstrate how to implement this solution.
Implementing the solution
Before proceeding, ensure you’ve satisfied the following prerequisites.
Prerequisites
- Create an AWS account if you don’t already have one and sign in. Create a user using AWS Identity Center (successor to AWS Single Sign-On) with full administrator permissions as described in Add users. Sign in to the AWS Management Console using the Identity Center user you just created.
- Install the AWS Command Line Interface (AWS CLI) on your local development machine and create a profile for the admin user as described at Set Up the AWS CLI.
- Install Docker on your local machine.
- Clone Our GitHub repository to your local machine.
With these prerequisites satisfied, you can proceed with configuring the solution.
Choose AMI
The AMI we will choose for our AWS Batch compute environment will be an Amazon Linux AMI that is ECS-optimized. This AMI has Neuron drivers pre-installed to support AWS Inferentia2 instances. Remember that AMIs are region-specific, and since we are using the us-east-1 Region, we will use this community AMI published by AWS: ami-07979ad4c774a29ab. We can search and find this AMI in the Application and OS Images (Amazon Machine Image) catalog search in the Amazon EC2 Launch an instance screen (shown in Figure 2 below).
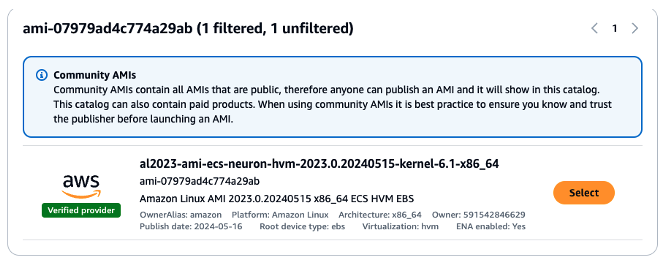
Figure 2. Amazon Linux AMI with Neuron drivers preinstalled
Build the Docker image
After cloning the GitHub repo, locate the Dockerfile. Notice that the referenced base image installs the AWS Neuron SDK for PyTorch 1.13.1 on AWS Inferentia.
FROM public.ecr.aws/neuron/pytorch-inference-neuronx:1.13.1-neuronx-py310-sdk2.18.1-ubuntu20.04
We will build the image using the following command:
docker build --no-cache -t whisper:latest .If successful, the output from the build should look like Figure 3 below.
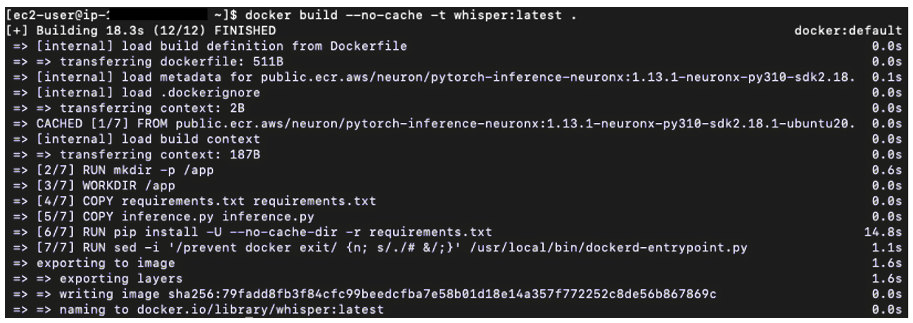
Figure 3. Successful build of the docker image
Push image to ECR
With the image built locally, we need to create a repository in ECR and push our image to it so that it will be accessible for Batch to use when launching compute environments.
aws ecr create-repository --repository-name whisperWe then tag the Docker image to match the repository URL.
docker tag whisper:latest [your-account-id].dkr.ecr.[your-region].amazonaws.com/whisper:latestFinally, we push the image to the Amazon ECR repository.
docker push [your-account-id].dkr.ecr.[your-region].amazonaws.com/whisper:latestCreate model artifacts
We provide a script called export-model.py that will create the encoder and decoder model files that will be used in our inference script. Let’s take a look at the code in this script.
First, we download a sample dataset to use for our Neuron trace.
# Load a sample from the dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
# sample #3 is ~9.9seconds and produces 33 output tokens + pad token
sample = dataset[3]["audio"]
input_features = processor(sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt").input_features
Next, we set the parameters. For our example, we choose the whisper-large-v3 checkpoint of the Whisper model, using the suffix to dynamically create the unique identifier for the model.
# select the desired model size
#suffix="tiny"
#suffix="small"
#suffix="medium"
suffix="large-v3"
model_id=f"openai/whisper-{suffix}"
Next, we load the tokenizer and model.
processor = WhisperProcessor.from_pretrained(model_id)
model = WhisperForConditionalGeneration.from_pretrained(model_id, torchscript=True)
The batch size controls how many files should be processed in parallel. In our solution, we are processing one file at a time, so we will set the batch_size to 1.
batch_size=1The output_attentions parameter is a flag that specifies whether the model will return the attention weights for each layer of the model. You need this if you want to add timestamps or perform debugging. You pay a penalty in latency for producing this output so we will set this to false.
output_attentions=FalseThe maximum decoder length specifies the maximum number of tokens the model will produce. Since we’re not concerned with metering output tokens, we’ll set this to the maximum of 448.
max_dec_len=448In the script file, you’ll notice that we simplify the encoder and decoder functions to make them work with Neuron devices. These simplified functions will replace existing methods but are designed to be backwards compatible. We will also need a new variable called forward_neuron to invoke the model on inf2. For brevity, we’re only showing the encoder function here:
def enc_f(self, input_features, attention_mask, **kwargs):
if hasattr(self, 'forward_neuron'):
out = self.forward_neuron(input_features, attention_mask)
else:
out = self.forward_(input_features, attention_mask, return_dict=True)
return BaseModelOutput(**out)
We define the name of the model artifact.
model_filename=f"whisper_{suffix}_{batch_size}_neuron_encoder.pt"To export the model, we need to run a trace using the torch_neuronx library.
neuron_encoder = torch_neuronx.trace(
model.model.encoder,
inp,
compiler_args='--model-type=transformer --enable-saturate-infinity --auto-cast=all',
compiler_workdir='./enc_dir',
inline_weights_to_neff=False)
neuron_encoder.save(model_filename)
Similarly, we need to do the same for the decoder.
model_filename=f"whisper_{suffix}_{batch_size}_{max_dec_len}_neuron_decoder.pt"
neuron_decoder = torch_neuronx.trace(
model.model.decoder,
inp,
compiler_args='--model-type=transformer --enable-saturate-infinity --auto-cast=all',
compiler_workdir='./dec_dir',
inline_weights_to_neff=True)
neuron_decoder.save(model_filename)
Once we save these .pt files to the local drive we can copy them to an Amazon S3 location designated for model artifacts. The AWS CloudFormation template presented in the next section creates the Batch job with the encoder and decoder files referenced as environment variables (shown in Figure 4 below).
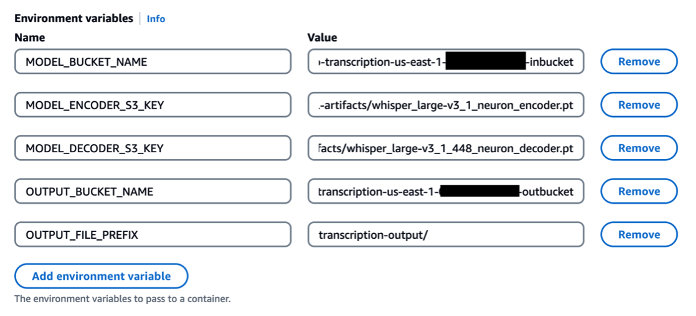
Figure 4. Configurable environment variables shown from the AWS Batch console
For a step-by-step guide on creating these model artifacts, refer to the README.md file of the Git repo.
Deploy the solution
You can use the CloudFormation template to accelerate the deployment of this solution with these steps:
- Choose Launch Stack below to launch the solution in the us-east-1 Region:

- For Stack name, enter a unique stack name.
- Set the parameters.
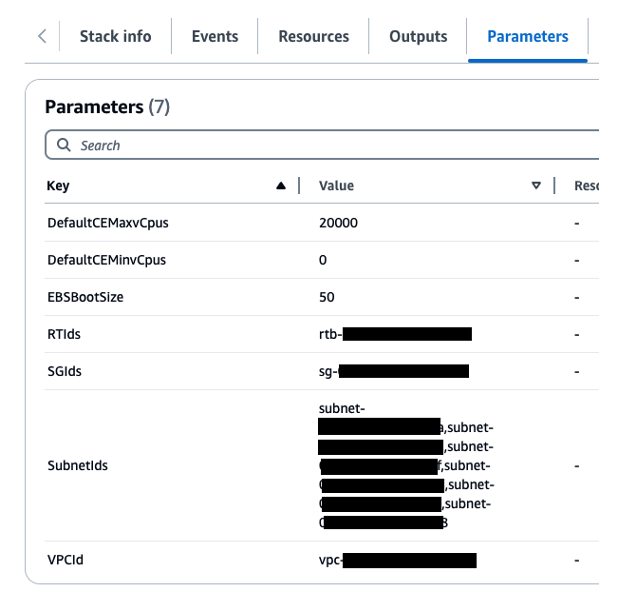
Figure 5. Parameter values for the CFT
- Acknowledge the capabilities.
- Choose Create stack.
Before moving on, let’s take a look at the inference.py script to understand how it processes the audio files.
Inference.py
First we’ll specify the number of Neuron cores. For the inf2.8xlarge instance, there is one Neuron chip with 2 cores.
import os
os.environ['NEURON_RT_NUM_CORES']='2'
Using the torchaudio package, we’re able to generate waveforms from the audio and create chunks of 30 second clips.
import torchaudio
# copy from s3
s3_client.download_file(input_bucket_name, input_file_key, input_file_key.split("/")[-1])
audio_path = input_file_key.split("/")[-1]
# Load the audio file
waveform, sample_rate = torchaudio.load(audio_path)
# Ensure the audio is in the correct format (mono, 16kHz)
if waveform.shape[0] > 1:
waveform = torch.mean(waveform, dim=0, keepdim=True)
if sample_rate != 16000:
waveform = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)(waveform)
# chunk the audio
chunk_size = 30*16000 # 30 seconds * 16000 samples / second
chunks = waveform.split(chunk_size, dim=1)
We send each chunk to the model for inference and append it to the transcriptions array object.
transcriptions = []
for chunk in chunks:
inputs = processor(chunk.squeeze().numpy(), sampling_rate=16000, return_tensors="pt")
with torch.no_grad():
predicted_ids = model.generate(inputs.input_features)
transcription = processor.decode(predicted_ids[0])
transcriptions.append(transcription)
Finally, we combine the transcriptions into a text file and write it out to Amazon S3.
# Extract the file name from the S3 object key
audio_path = input_file_key.split("/")[-1]
# Combine the transcriptions
full_transcription = " ".join(transcriptions)
# Append txt to original file name and write transcription file locally
output_filename = audio_path + '.txt'
file = open(output_filename, 'w')
file.write(full_transcription)
file.close()
# write to S3
s3_client.put_object(Body=full_transcription, Bucket=output_bucket_name, Key=output_file_prefix + output_filename)
Testing the solution
To test our audio transcription, we used audio files of interviews from NASA’s Expedition 46, which began in 2015. This was the 46th mission to the International Space Station (ISS) and the last expedition of the ISS year-long mission. These audio files were released into the public domain by NASA and are available for download from the Internet Archive.
This mission included two Russian cosmonauts who were interviewed in the preflight news conference. This also allowed us to test Whisper’s transcription for both English and Russian.
Upload audio files
We selected 5 audio files totaling 3 GB and uploaded them to our audio-input folder of our Amaz$on S3 bucket.
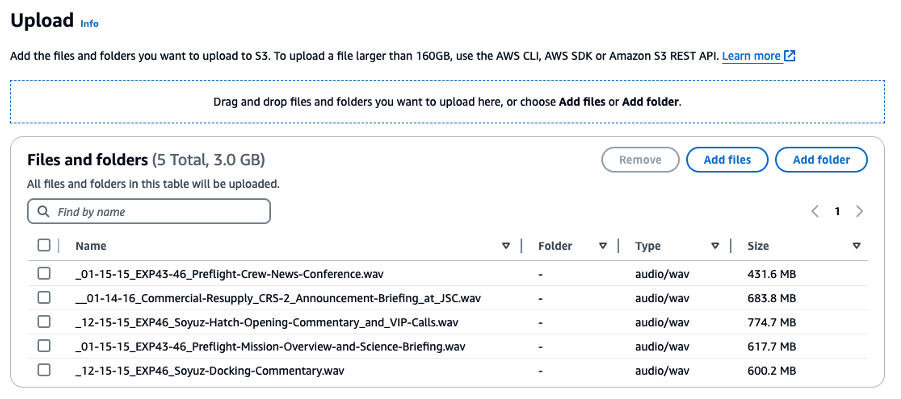
Figure 6. Audio files uploaded to the Amazon S3 input folder
As each upload completes, event triggers from Amazon EventBridge added them to our AWS Batch job queue.
Monitor AWS Batch job processing
We can verify that our jobs are being processed by monitoring the Batch dashboard.
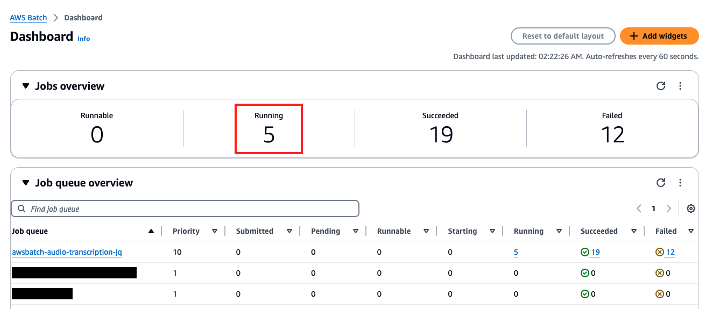
Figure 7. AWS Batch job queue dashboard
While the jobs are running, we can monitor the utilization from the Compute Environments dashboard by enabling Container Insights.
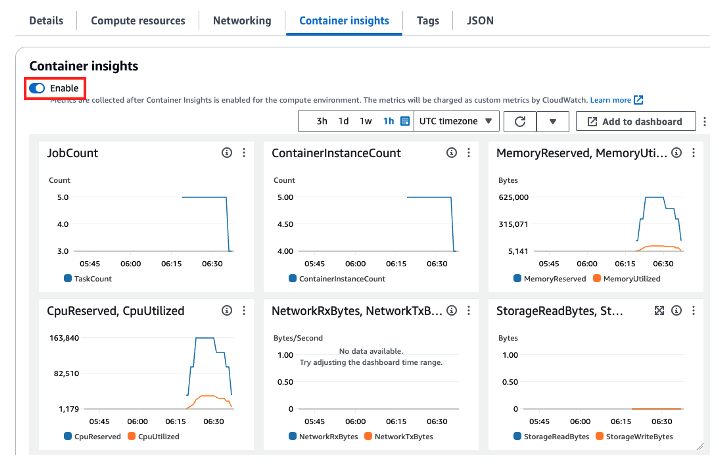
Figure 8. Monitoring the utilization of our compute environments using Container Insights
These metrics only report the utilization of the CPU and the memory in the CE. But we also need to monitor the Inferentia2 Neuron cores themselves. To do this, we installed a config script using a Batch Launch Template to push metrics to Amazon CloudWatch. This is an excerpt from the CloudFormation template.
# Configure Neuron Monitor
cat > /tmp/monitor.conf << EOF
{
"period": "1s",
"neuron_runtimes": [
{
"tag_filter": ".*",
"metrics": [
{
"type": "neuroncore_counters"
},
{
"type": "memory_used"
},
{
"type": "neuron_runtime_vcpu_usage"
},
{
"type": "execution_stats"
}
]
}
],
"system_metrics": [
{
"type": "vcpu_usage"
},
{
"type": "memory_info"
},
{
"period": "2s",
"type": "neuron_hw_counters"
}
]
}
EOF
# Run Neuron Monitor and pipe the output to Neuron Monitor CloudWatch
/opt/aws/neuron/bin/neuron-monitor -c /tmp/monitor.conf \
| /opt/aws/neuron/bin/neuron-monitor-cloudwatch.py \
--namespace neuron_monitor -d instance_id --region us-east-1 &
Now when our Batch jobs run, we can view the utilization of the Neuron cores in CloudWatch.
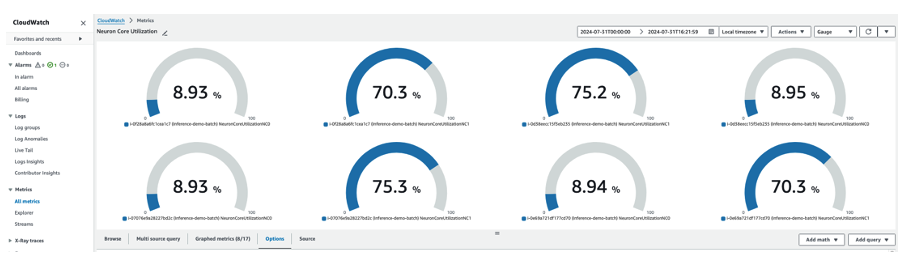
Figure 9. Validating the output transcription files written to Amazon S3
Validate the transcription
When the jobs complete, we can confirm that the output files with the transcriptions are written to our output folder in Amazon S3.
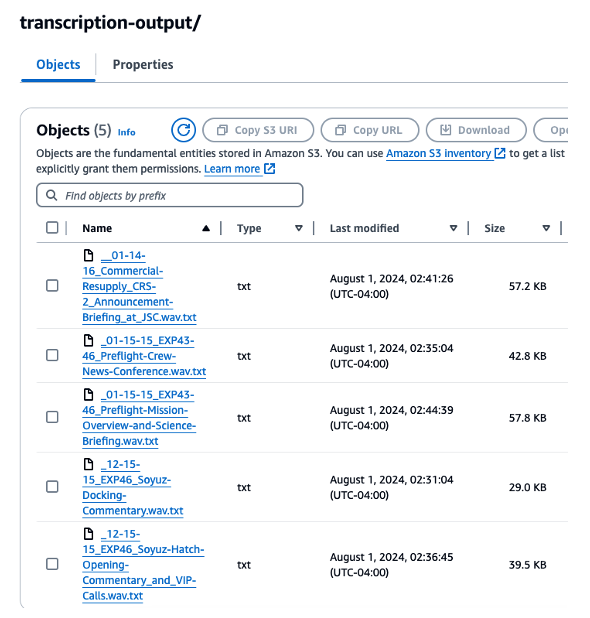
Figure 10. Validating the output transcription files written to Amazon S3
Viewing the preflight news conference transcription, we can see that our pipeline worked as expected, transcribing both English and Russian.
<|startoftranscript|><|en|><|transcribe|> The launch of Soyuz TMA-16M will return three veteran space flyers to the International Space Station, with two of them embarking on the first-ever year-long mission to this vehicle. One-year expedition crew member, retired U.S. Navy Captain Scott Kelly, has accumulated 180 days in space during three missions. Kelly piloted Space Shuttle Discovery's service mission to the Hubble Space Telescope in 1999.<|endoftext|>
Further in our transcription file, we find responses from cosmonaut Mikhail Korniyenko transcribed in Russian.
<|startoftranscript|><|ru|><|transcribe|><|notimestamps|> Как вы себя чувствуете? Я очень хорошо. Мои коллеги-клубники тоже. Мы рады, что мы здесь, завершили тренировку в США. И я уезжаю в Германию на неделю, а космонавты возвращаются в Россию на последние шесть недель тренировки перед завершением. Хорошо. Что еще?<|endoftext|>
The full transcript written to Amazon S3 demonstrates that our solution worked! The Whisper model transcribed different spoken languages in the same audio file automatically.
Clean up
To avoid further charges and to keep your environment tidy, delete the resources created for this solution:
- From the AWS CloudFormation console, delete the stack.
- Delete the audio files, log files, and transcription files from the Amazon S3 buckets.
Conclusion
In this blog post, we explored a cost-efficient solution for batch audio transcription using the Whisper model on AWS. We demonstrated how to leverage AWS Batch and AWS Inferentia2 to process audio files asynchronously, triggered by the arrival of audio files in Amazon S3. This approach allows customers who don’t require real-time or online inference to optimize costs by running the Whisper model in a batch processing environment.
If you’re using AWS Batch and AWS Inferentia2 for your batch audio transcription workloads, email us at ask-hpc@amazon.com and tell us about your experience!