AWS HPC Blog
Scaling your LLM inference workloads: multi-node deployment with TensorRT-LLM and Triton on Amazon EKS
This post was contributed by Aman Shanbhag from, and Kshitiz Gupta, Jiahong Liu, Rohan Varma, and Wenhan Tan from NVIDIA.
In the ever-evolving landscape of Artificial Intelligence, Large Language Models (LLMs) have been growing exponentially in size and capability. The introduction of Llama 3.1 405B, with its staggering 405 billion parameters, exemplifies this trend towards increasingly larger LLMs.
As models continue to grow, multi-node inference capabilities are increasingly important for production deployments that require real-time user experiences. NVIDIA Triton Inference Server (or just Triton from here) and NVIDIA TensorRT-LLM (likewise just TRT-LLM for brevity) enable multi-GPU, multi-node scaling, allowing developers to seamlessly deploy large models at scale using Kubernetes.
In this post, we’ll walk you through a multi-node deployment of the Llama 3.1 405B model sharded across Amazon EC2 Accelerated GPU instances. Specifically, we use two Amazon EC2 P5 instances (P5.48xlarge) on Amazon EKS, utilizing the powerful combination of NVIDIA Triton, and the NVIDIA TRT-LLM optimization toolkit, along with the Kubernetes LeaderWorkerSet (LWS).
Solution overview
Amazon EKS is a managed Kubernetes service that makes it straightforward to run Kubernetes clusters on AWS. It manages the availability and scalability of the Kubernetes control plane, and provides compute node auto scaling and lifecycle management support to help you run highly-available containerized applications.
Amazon EKS is an ideal platform for running distributed multi-node inference workloads due to its robust integration with AWS services and performance features. It seamlessly integrates with Amazon EFS, a high-throughput file system, enabling fast data access and management among nodes using Kubernetes Persistent Volume Claims (PVCs). Efficient multi-node LLM inference also requires enhanced network performance. Elastic Fabric Adapter (EFA), a network interface which offers low-latency, high-throughput connectivity between Amazon EC2 accelerated instances, is well-suited for this.
The main challenge in deploying models across multiple nodes is that, since each Kubernetes pod is restricted to a single node, an instance of a model that spans multiple nodes must also span multiple pods. Consequently, the atomic unit that needs to be ready before the model can be served and scaled is a group of pods. We will refer to this group of pods as a superpod.
Now, let’s show you how this works.
MPI and LWS for launching the NVIDIA TRT-LLM and NVIDIA Triton deployments across “superpods”
NVIDIA Triton is an open-source AI model serving platform that streamlines and accelerates the deployment of AI inference workloads in production. It helps developers reduce the complexity of model serving infrastructure, shorten the time needed to deploy new AI models, and increase AI inferencing and prediction capacity. NVIDIA TRT-LLM provides users with an easy-to-use Python SDK to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM also contains components to create Python and C++ runtimes that execute those TensorRT engines.
NVIDIA Triton and NVIDIA TRT-LLM are built to serve models in multi-node settings. They enable this functionality by leveraging Message Passing Interface (MPI), a standard for designing and launching multiple processes that communicate with each other to function as if they were one program.
However, to launch processes across nodes, MPI typically requires the hostnames of all participating nodes. Consequently, when translating this flow to Kubernetes (K8s), we need a way to create and deploy the superpods we mentioned, and generate metadata that tracks which pods/hostnames make up the superpod.
Since this functionality doesn’t exist in standard K8s, we obtain it through the LeaderWorkerSet API. We deploy the LeaderWorkerSet using the guidance in the LWS GitHub repo, and launch Triton TRT-LLM via MPI in deployment.yaml and server.py.
Gang scheduling
Gang scheduling means ensuring that all the pods that make up a model instance are ready before Triton and TRT-LLM are launched. We show how to use kubessh to achieve this in the wait_for_workers function of server.py.
Auto scaling
By default, the Horizontal Pod Autoscaler (HPA) scales individual pods. However, LWS makes it possible to scale each “superpod”. We demonstrate how you can collect GPU metrics exposed by the Triton Server to Prometheus and set up custom metrics, like queue-to-compute-ratio, in triton-metrics_prometheus-rule.yaml. For more metrics that you can scrape, check out Triton Metrics. We also demonstrate how to properly set up PodMonitors, which define the monitoring rules for a set of pods, and an HPA in pod-monitor.yaml and hpa.yaml. The key is to only scrape metrics from the leader pods.
To enable dynamically adding nodes in response to the HPA, we also set up a Cluster Autoscaler (CAS). By combining these components, the Triton server scales dynamically with request load. As the queue-to-compute ratio rises, the HPA triggers the creation of additional multi-node model instances/superpods. If sufficient resources to run these additional superpods are not available, CAS automatically adds more cluster nodes to meet the demand.
Load balancing
Although there are multiple pods in each instance of the model, only one pod within each group accepts requests. In service.yaml, we show how to correctly set up a LoadBalancer Service to allow external clients to submit requests.
Architecture
In this post, we follow the instructions provided by awsome-inference. The deployment architecture is shown in Figure 1Figure 1.
We provision a Virtual Private Cloud (VPC) and associated resources – subnets (Public and Private), NAT Gateways, and an Internet Gateway. We create an EKS cluster with a GPU node group using 2 x p5.48xlarge instances to run the model, and a CPU node group using one c5.2xlarge instance to run tasks that do not require a GPU.
We use the LeaderWorkerSet Custom Resource Definition (CRD) to partition the model across nodes into a superpod, and expose the model through a load balancer (Kubernetes Ingress of type Application Load Balancer).
Lastly, we add autoscaling by configuring the Horizontal Pod Autoscaler (HPA) for the superpods, and a Cluster Autoscaler (CAS) for the nodes.
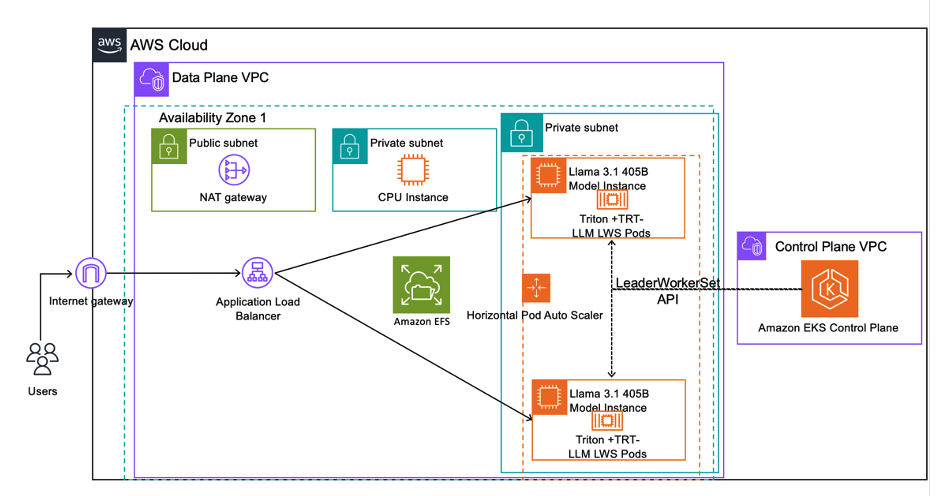
Figure 1 – This is the high-level architecture diagram of what you will be provisioning in this blog to deploy the Llama3.1-405B model across multiple P5.48xlarge EC2 instances.
Figure 2 shows a detailed view of using LWS to partition the Llama3.1-405B model.
With the LWS Controller, Kubernetes Custom Resource Definition (CRD) and Kubernetes Stateful Sets (STS), we provision the superpods, which consist of a leader pod in one GPU node, along with worker pods in the other GPU nodes. All of these pods together (that is, in one superpod) form one instance of the model.
We use Elastic Fabric Adapter (EFA) to enable minimal latency communication between these GPU nodes. We scale these superpods using the HPA and when pods are “unschedulable”, we use the CAS to provision new p5.48xlarge instances (to host new superpods). We scrape custom metrics via Prometheus for observability from the leader pods.
Finally, the Application Load Balancer routes traffic to these superpods (Kubernetes Ingress resource of type ALB).
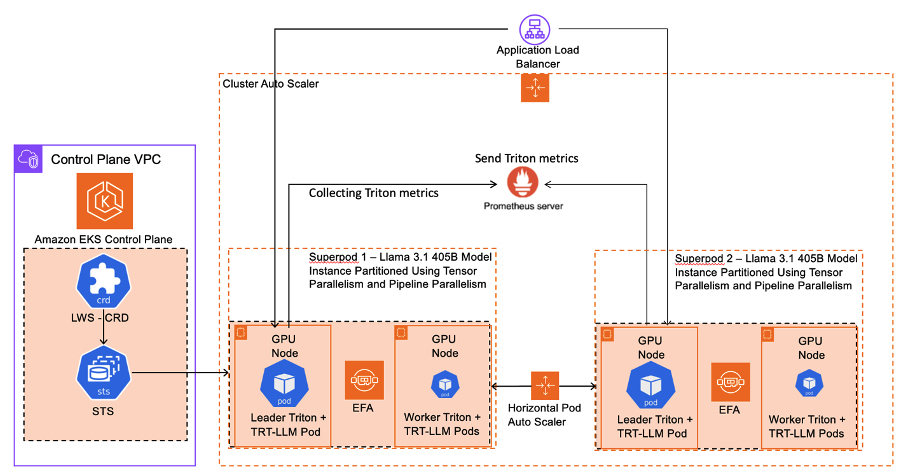
Figure 2 – Detailed view of the architecture of the Llama3.1-405B model partitioned across p5.48xlarge nodes using LeaderWorkerSet
Deploying into your AWS Account
Prerequisites
Make sure that the following packages are installed. You can find shell scripts in aws-do-eks under aws-do-eks/Container-Root/eks/ops/setup/ that will install all of these packages for you. Alternatively, you may choose to manually install these with instructions found in this README:
To get started, clone the awsome-inference GitHub repository. This repo contains reference architectures and test cases for inference on AWS. The examples cover a variety of models, use-cases, and frameworks for inference optimization.
git clone https://github.com/aws-samples/awsome-inference.gitLastly, run aws configure to authenticate with AWS. For the rest of this post, we’ll assume us-east-2 as the region to provision resources. The CloudFormation template we provided uses the fields az-a and az-b for names, which you can change as needed.
Create your VPC and EKS cluster
You can find all the resources for this sub-section in the sub-directory:
cd 1.infrastructure/In this directory, you will find the files needed to get a Virtual Private Cloud (VPC), and an EKS cluster, set up in your own environment.
To set up your VPC, go to the 0_setup_vpc/ directory, and use vpc-cf-example.yaml, which is ana AWS CloudFormation template for deploying a VPC with a pair of public and private subnets, spread across two Availability Zones (AZ). It also includes an Internet gateway, a default route on the public subnets, a pair of NAT gateways (one in each AZ), and default routes for them in the private subnets. For more information on this CloudFormation template, check out AWS CloudFormation VPC Template. To set up your infrastructure, use the following AWS CLI command:
aws cloudformation create-stack –stack-name awsome-inference-vpc –template-body file://vpc-cf-example.yaml --capabilities CAPABILITY_IAM --parameters ParameterKey=EnvironmentName,ParameterValue=awsome-inference-vpcThe CAPABILITY_IAM flag parameter tells CloudFormation that the stack template that we provide includes resources that can affect IAM permissions in your AWS Account.
You can then set up your EKS cluster using the instructions found in the README of awsome-inference/1.infrastructure. This README also includes instructions on how to create your EKS cluster using Amazon EC2 Capacity Blocks for ML. For more information on setting up your EKS cluster with Capacity Blocks, check out the Capacity Blocks section of the README. We recommend provisioning your cluster with EFA enabled instances to maximize the benefits of LWS. You can find the cluster configuration in 1_setup_cluster/multinode-triton-trtllm-inference/p5-trtllm-cluster-config.yaml, and create the cluster following these instructions. This cluster configuration provisions a managed EKS cluster of 2 x p5.48xlarge instances, reserved via On-Demand Capacity Reservations (ODCR), with the efaEnabled parameter set to true. Additionally, it provisions a managedNodeGroup with a CPU node. Feel free to modify this configuration to suit your own workload. Then execute the create cluster command:
eksctl create cluster -f p5-trtllm-cluster-config.yamlThe cluster creation process can take up to 30 minutes. To validate a successful completion of the process, run kubectl get nodes -L node.kubernetes.io/instance-type:
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE
ip-192-168-117-30.ec2.internal Ready <none> 3h10m v1.30.2-eks-1552ad0 p5.48xlarge
ip-192-168-127-31.ec2.internal Ready <none> 155m v1.30.2-eks-1552ad0 c5.2xlarge
ip-192-168-26-106.ec2.internal Ready <none> 3h23m v1.30.2-eks-1552ad0 p5.48xlarge
Create an EFS file system and mount it to your cluster
Since the model is large, we need to shard it and load it across multiple pods (deployed across multiple nodes), so that we can use them in coordination to serve inference requests. To do this, we need a common, shared storage location. We use EFS as persistent volume, and create a persistent-volume claim which we can use to mount the EFS persistent volume to pods.
Before creating the EFS file system, we will have to create an add-on to our cluster to use the EFS-CSI driver. The provided p5-trtllm-cluster-config.yaml file contains lines that include the right policies for this driver, along with the driver as an add on. If you choose to use your own cluster configuration file, you can follow the steps listed on Creating an Amazon EKS add-on to create the add-on for the EFS-CSI controller for your specific cluster configuration.
You can follow the steps listed here to create an EFS file system. Alternatively, you could use the scripts here. Once your EFS file system is provisioned and in service, you can mount it to your EKS cluster using the provided pv.yaml, claim.yaml, and storageclass.yaml files. Note: You will have to edit pv.yaml and specify the EFS volume ID before you run kubectl apply -f pv.yaml
# Storage Class
kubectl apply -f storageclass.yaml
# Persistent Volume
kubectl apply -f pv.yaml
# Persistent Volume Claim
kubectl apply -f claim.yaml
Configure your EKS cluster
Once we have your EKS cluster and EFS file system created, we can move on to configure your EKS cluster. These are the steps you would need to follow:
1. Add node label and taints
- A node label of
nvidia.com/gpu=presentto identify the nodes with NVIDIA GPUs. - A node taint of
nvidia.com/gpu=present:NoScheduleto prevent non-GPU pods from being deployed onto GPU nodes.
You can run the following to add the aforementioned labels and taints:
# Add label
kubectl label nodes $(kubectl get nodes -L node.kubernetes.io/instance-type | grep p5 | cut -d ‘ ‘ -f 1) nvidia.com/gpu=present
# Add taint
kubectl taint nodes $(kubectl get nodes -L node.kubernetes.io/instance-type | grep p5 | cut -d ‘ ‘ -f 1) nvidia.com/gpu=present:NoSchedule
2. Install the Kubernetes Node Feature Discovery Service
The Kubernetes Node Feature Discovery Service allows for the deployment of a pod onto a node with a matching taint (from what we set above).
# Create a new namespace
kubectl create namespace monitoring
# Instructions from Node Feature Discovery GitHub
helm repo add kube-nfd https://kubernetes-sigs.github.io/node-feature-discovery/charts && helm repo update
helm install -n kube-system node-feature-discovery kube-nfd/node-feature-discovery \
--set nameOverride=node-feature-discovery \
--set worker.tolerations[0].key=nvidia.com/gpu \
--set worker.tolerations[0].operator=Exists \
--set worker.tolerations[0].effect=NoSchedule
3. Install the NVIDIA Device Plugin for Kubernetes and NVIDIA GPU Feature Discovery Service
The NVIDIA Device Plugin for Kubernetes lets you automatically expose the details of your NVIDIA GPUs in your cluster, track the health of your GPUs, and run GPU enabled containers/pods within your EKS cluster. In this example, the cluster that we provisioned uses the EKS optimized AMI (Amazon Linux 2), which already has the NVIDIA drivers pre-installed. If you would like to use your own AMI which does not have the drivers pre-installed, install the NVIDIA GPU Operator first. The NVIDIA GPU Feature Discovery for Kubernetes is a service that lets you automatically generate labels for the GPUs available on the nodes in your EKS cluster. For a list of EKS optimized AMIs, check out Create nodes with optimized Amazon Linux AMIs.
# NVIDIA Device Plugin
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.15.0/deployments/static/nvidia-device-plugin.yml
# NVIDIA GPU Feature Discovery Service
cd 2.projects/multinode-triton-trtllm-inference/multinode_helm_chart/
kubectl apply -f nvidia_gpu-feature-discovery_daemonset.yaml
4. Install the Prometheus Kubernetes Stack
The Prometheus Kubernetes Stack installs the necessary components including Prometheus, Kube-State-Metrics, Grafana, etc. for Triton metrics collection.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts && helm repo update
helm install -n monitoring prometheus prometheus-community/kube-prometheus-stack \
--set tolerations[0].key=nvidia.com/gpu \
--set tolerations[0].operator=Exists \
--set tolerations[0].effect=NoSchedule
5. Install NVIDIA DCGM Exporter
The NVIDIA DCGM Exporter lets us collect GPU metrics through DCGM, the recommended way to monitor GPU status in our cluster. Note: the nvidia_dcgm-exporter_values.yaml file is located in the multinode_helm_chart/ sub-directory that we cd into earlier!
helm repo add nvidia-dcgm https://nvidia.github.io/dcgm-exporter/helm-charts && helm repo update
helm install -n monitoring dcgm-exporter nvidia-dcgm/dcgm-exporter --values nvidia_dcgm-exporter_values.yaml
6.Configure Prometheus to scrape custom metrics from the Triton Server
To configure Prometheus to scrape custom Triton metrics for use with Kubernetes’ HPA service, refer to the README for detailed instructions on installing the Prometheus Adapter.
In the triton-metrics_prometheus-rule.yaml we define the custom metric queue_compute_ratio from a formula that uses the Triton metrics collected by Prometheus. This metric represents the ratio between the time a request spends in the inference queue to the time it takes to complete once it has left the queue. In the values.yaml files for this example’s Helm chart, the HPA is configured to use this queue_compute_ratio metric provided by those rules. Feel free to change this file to modify the rules and create your own custom metrics and set them in the HPA manifest. You can run kubectl apply -f triton-metrics_prometheus-rule.yaml to configure Prometheus to scrape the metric.
With this, we have completed setting up all the components of monitoring and custom metric scraping!
7. Install the EFA Kubernetes Device Plugin
The EFA Kubernetes Device Plugins supports all Amazon EC2 instances that have EFA. This plugin detects and advertises EFA interfaces as allocatable resources to Kubernetes. For more information, check out “Run machine learning training on Amazon EKS with Elastic Fabric Adapter”. You can run the following to install this plugin
helm repo add eks https://aws.github.io/eks-charts
helm pull eks/aws-efa-k8s-device-plugin --untar
Once you pull the helm chart, follow the instructions in this README to add tolerations. Once done, install the EFA Kubernetes Device Plugin helm chart.
helm install aws-efa-k8s-device-plugin --namespace kube-system ./aws-efa-k8s-device-plugin/8. Install the Cluster Autoscaler (CAS)
In this post, we also demonstrate provisioning the CAS to scale your inference workload. This step is optional for deploying a single model instance.
When the HPA scales up to launch another superpod of 2 pods representing a new model instance, these pods would be marked as unschedulable. In response to these unschedulable pods, the CAS will add more nodes to the cluster (i.e., horizontal scaling). It also scales down when the additional nodes become free. You can install the CAS following the steps listed here.
9. Install the LeaderWorkerSet (LWS) API onto your EKS Cluster
Finally, install LWS onto your EKS cluster to use the API. LWS handles the concept of “superpods” and lets you provision a model instance across multiple nodes. You can follow the instructions on this README to get LWS set up.
Optimize your workload with TRT-LLM and deploy with Triton
1. Build the custom container image and push it to Amazon ECR
We need to build a custom image on top of the Triton TRT-LLM NGC container to include the kubessh file, server.py, and other dependencies like EFA libraries. We will then push this image to Amazon Elastic Container Registry (ECR). You can also take a look at the Dockerfile.
# Ensure you’re in the right directory
cd awsome-inference/2.projects/multinode-triton-trtllm-inference/
docker build \
--file ./multinode_helm_chart/containers/triton_trt_llm.containerfile \
--tag ${REGISTRY}${IMAGE}${TAG} \
.
Once you’ve built your custom image, push it to Amazon ECR. To learn more about pushing an image to Amazon ECR, check out this AWS Documentation.
2. Setup the Triton model repository for LLM deployment
We build the TRT-LLM engine and set up the Triton model repository inside the compute node. Follow the steps listed below, which use the provided setup_ssh_efs.yaml manifest to set up SSH access to the compute node (along with EFS). You can then use the following code block to deploy the pod and SSH into the node.
cd multinode_helm_chart/
kubectl apply -f setup_ssh_efs.yaml
kubectl exec -it setup-ssh-efs -- bash
Then, follow the instructions here to clone the Triton TRT-LLM backend repository. The steps mention <EFS_mount_path>. Run the following to get the mount path.
# Get your EFS mount path by running the command below
df -h
If you follow along with this post, your mount path should be /var/run/models.
Lastly, you can download the BF16 checkpoints of the Llama 3.1 405B model from HuggingFace by following the instructions here. You may hit “n” if asked whether you’d like to use your HuggingFace token as a git credential. Make sure to provide the HuggingFace Token for downloading the model. Downloading the model weights can take ~4 hours! Go grab a coffee or some dinner, or let it run overnight, you’ve earned the rest!
Note: update your transformers installation usiong pip install --upgrade transformers
Once you download the model weights, you will build the BF16 TRT-LLM engine for LLaMa 3.1 405B with Tensor Parallelism=8, Pipeline Parallelism=2 to run on 2 x p5.48xlarge nodes (8 x H100 GPUs each) — so a total of 16 GPUs across 2 nodes. Tensor parallelism is a model parallelism technique that distributes matrix multiplications within transformer layers across multiple GPUs. In contrast, pipeline parallelism adopts a vertical splitting strategy, dividing the model by layers. Here we use two-way pipeline parallelism to shard the model across the two nodes, and eight-way tensor parallelism to shard the model across the eight GPUs on each node. Below are the relevant TRT-LLM functions. Feel free to modify them as required by your inference workload.
First, run convert_checkpoint.py to convert the out-of-the-box Llama3.1-405B model to a TensorRT optimized one. This step can take ~2 hours to run.
python examples/llama/convert_checkpoint.py --model_dir Meta-Llama-3.1-405B \
--output_dir trt_ckpts/tp8-pp2/ \
--dtype bfloat16 \
--tp_size 8 \
--pp_size 2 \
--load_by_shard \
--workers 8
Troubleshooting Tip: If you see an error that looks like
ValueError: `rope_scaling` must be a dictionary with two fields, `type` and `factor`, got {'factor': 8.0, 'low_freq_factor': 1.0, 'high_freq_factor': 4.0, 'original_max_position_embeddings': 8192, 'rope_type': 'llama3'}Make sure you have an upgraded version of the transformers package by running.
pip install –upgrade transformersNext, build the efficient TRT-LLM engine with the required inference optimizations with the trtllm-build API call. This step can take ~1.5 hours to run.
trtllm-build --checkpoint_dir trt_ckpts/tp8-pp2/ \
--output_dir trt_engines/tp8-pp2/ \
--max_num_tokens 4096 \
--max_input_len 255000 \
--max_seq_len 256000 \
--use_paged_context_fmha enable \
--workers 8
Once we have set up TRT-LLM, we can move on to preparing the Triton model repository. We do so by modifying the config.pbtxt files. Follow the instructions listed the Deploy_Triton.md README. Make sure to provide the absolute path values for <PATH_TO_TOKENIZER> and <PATH_TO_ENGINES>. These are paths to the respective directories, not paths to the tokenizer and engine files.
Pro-tip: You can save the <PATH_TO_TOKENIZER> and <PATH_TO_ENGINES> as environment variables as described below to make modifying the config.pbtxt file easier in later steps. This example assumes that your EFS path is /var/run/models.
# Example Tokenizer Path
export PATH_TO_TOKENIZER=/var/run/models/tensorrtllm_backend/tensorrt_llm/examples/llama/Meta-Llama-3.1-405B
# Example Engine Path
export PATH_TO_ENGINE=/var/run/models/tensorrtllm_backend/tensorrt_llm/examples/llama/trt_engines/tp8-pp2
Once you have those paths saved as environment variables you can run the commands below to copy the ensemble, pre-processing, post-processing, and tensorrt_llm models to your Triton model repository.
# Assuming that your EFS mount path is /var/run/models
cd /var/run/models/tensorrtllm_backend
mkdir triton_model_repo
# Copy the models to your triton model repo directory
rsync -av --exclude='tensorrt_llm_bls' ./all_models/inflight_batcher_llm/ triton_model_repo/
Lastly, we use the fill_template.py script that’s provided as part of the tensorrtllm_backend to replace placeholder values with your PATH_TO_TOKENIZER and PATH_TO_ENGINE. We’ve provided a bash script that you can run. Feel free to edit the TensorRT-LLM specific parameters like batch size, depending on your workload.
# Replace <PATH_TO_AWSOME_INFERENCE_GITHUB> with path to where you cloned the GitHub repo
bash <PATH_TO_AWSOME_INFERENCE_GITHUB>/2.projects/multinode-triton-trtllm-inference/update_triton_configs.sh
3. Create example_values.yaml file for deployment
You can find the example_values.yaml file that we use for deploying our application here. The relevant sections of this deployment manifest are:
…
gpu: NVIDIA-H100-80GB-HBM3
gpuPerNode: 8
persistentVolumeClaim: efs-claim
tensorrtLLM:
parallelism:
tensor: 8
pipeline: 2
triton:
image:
name:${ACCOUNT}.dkr.ecr.${AWS_REGION}.amazonaws.com/triton_trtllm_multinode:24.08
resources:
cpu: 64
memory: 512Gi
efa: 32 # If you don’t want to use EFA, set this to 0
triton_model_repo_path: /var/run/models/tensorrtllm_backend/triton_model_repo
enable_nsys: false # Note if you send lots of requests, nsys report can be very large.
…
In this manifest, we specify the 8 x NVIDIA H100 GPUs available to use per node, and our previously created shared file system (EFS PVC named efs-claim in this case). Additionally, we specify the TRT-LLM parallelism parameters (tensor parallelism = 8; pipeline parallelism = 2). Lastly, we also specify the image we built and pushed to ECR, along with other pod requirements such as CPU, memory and efaEnabled pods.
4. Install the multinode-deployment Helm Chart
Before following the steps below to install the multinode-deployment LeaderWorkerSet helm chart, ensure that you delete the setup-ssh-efs pod that we previously created (with the infinite sleep), so that we have the GPU resources required to deploy the model.
kubectl delete -f multinode_helm_chart/setup_ssh_efs.yaml
We use the previously created example_values.yaml to create the Helm chart for the deployment.
kubectl delete -f multinode_helm_chart/setup_ssh_efs.yaml
We use the previously created example_values.yaml to create the Helm chart for the deployment.
helm install multinode-deployment \
--values ./multinode_helm_chart/chart/values.yaml \
--values ./multinode_helm_chart/chart/example_values.yaml \
./multinode_helm_chart/chart/.
You can find further instructions on installing this helm chart and checking up on the deployment, if needed.
Note: The value that you specify for the gpu field in example_values.yaml must match the node’s .metadata.labels.nvidia.com/gpu.product label. For example, for the P5 instances, you need to have the following label set
nvidia.com/gpu.product = NVIDIA-H100-80GB-HBM3
You can run kubectl describe nodes -L metadata.labels.nvidia.com/gpu.product to check whether or not the label exists. If it doesn’t exist, add it with:
kubectl label nodes $(kubectl get nodes -L node.kubernetes.io/instance-type | grep p5 | cut -d ‘ ‘ -f 1) nvidia.com/gpu.product=NVIDIA-H100-80GB-HBM3Then take a look at the provided values.yaml file to ensure that you set the parameters correctly.
Once you install the helm chart, you can run kubectl get pods, you should see:
NAME READY STATUS RESTARTS AGE
leaderworkerset-sample-0 1/1 Running 0 28m
leaderworkerset-sample-0-1 1/1 Running 0 28m
Note: It takes ~25-40 minutes for the Llama3.1-405B model to start up. Make sure that your pods are READY and Running before proceeding.
You can then use the following command to check Triton logs, and make sure that the Triton server is up, and ready to serve inference requests:
kubectl logs --follow leaderworkerset-sample-0Among the logs, you should see an output similar to the one below, indicating that the Triton server is ready, and the deployment was successful.
I0717 23:01:28.501008 300 server.cc:674]
+----------------+---------+--------+
| Model | Version | Status |
+----------------+---------+--------+
| ensemble | 1 | READY |
| postprocessing | 1 | READY |
| preprocessing | 1 | READY |
| tensorrt_llm | 1 | READY |
+----------------+---------+--------+
I0717 23:01:28.502835 300 grpc_server.cc:2463] "Started GRPCInferenceService at 0.0.0.0:8001"
I0717 23:01:28.503047 300 http_server.cc:4692] "Started HTTPService at 0.0.0.0:8000"
I0717 23:01:28.544321 300 http_server.cc:362] "Started Metrics Service at 0.0.0.0:8002"
5. Send a curl POST request for inference
We can view the external IP address of Load Balancer that we set up within the Helm chart by running kubectl get services. Note that we use multinode_deployment as helm chart installation name here. Your output should look something like below:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
multinode_deployment LoadBalancer 10.100.44.170 a69c447a535104f088d2e924f5523d41-634913838.us-east-1.elb.amazonaws.com 8000:32120/TCP,8001:32263/TCP,8002:31957/TCP 54m
You can send a CURL request to the ensemble TRT-LLM Llama-3.1 405B model hosted in Triton Server with the following command:
curl -X POST <ALB-DNS>:8000/v2/models/ensemble/generate -d '{"text_input": "What is machine learning?", "max_tokens": 25, "bad_words": "", "stop_words": "", "pad_id": 2, "end_id": 2}'You should see an output like this:
{"context_logits":0.0,"cum_log_probs":0.0,"generation_logits":0.0,"model_name":"ensemble","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0],"sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":" Machine learning is a branch of artificial intelligence that deals with the development of algorithms that allow computers to learn from data and make predictions or decisions without being explicitly programmed."}Note: Your output structure may vary depending on your specific TensorRT-LLM configurations. If your output consists of the inference result (that is, the answer to your prompt), you can consider the operation successful.
6. Benchmarking
If you want to run benchmarking, you can use the NVIDIA genai-perf tool. genai-perf is a command-line benchmarking tool for measuring inference metrics of models served through an inference server.
Some of the metrics provided by this tool are output token throughput, time to first token, inter token latency, and request throughput. For more information on the tool, check out the GenAI-Perf Documentation.
To run benchmarking, follow the steps provided in this README.
Once you set up your genai-perf pod and observe the logs for the pod, you should see an output like the example output in “Running genai-perf”.
Note: This is just a sample result for arbitrary configurations. These aren’t real benchmarking numbers to show performance of multi-node TRT-LLM, Triton on EKS – but this should help you to recognize what the output from genai-perf looks like.
Conclusion
In this blog post, we demonstrated how to create an EKS cluster optimized for multi-node inference using low-latency EFA networking, high-throughput EFS storage, and high-performance NVLink connected H100 GPU based P5.48xlarge instances. We showed how to deploy state-of-the-art large-scale LLMs like LLaMa 3.1 405B using multi-node Triton Inference Server and TRT-LLM within this EKS cluster. We covered the challenges of orchestrating and autoscaling multi-node LLM deployments and demonstrated how the LeaderWorkerSet architecture together with Triton’s Prometheus metrics and TRT-LLM’s optimizations address these challenges, making the process more efficient and scalable.
This example showed P5 instances, but it will also work with other NVIDIA GPU instances like P4d, P4de, G5, G6, G6e. Be sure to check out the new P5e instances on AWS, powered by 8 x NVIDIA H200 GPUs, too.
Developers can start with NVIDIA Triton and NVIDIA TensorRT-LLM today, with enterprise-grade security, support, and stability through NVIDIA AI Enterprise available in the AWS Marketplace. Visit NVIDIA AI Enterprise in the AWS marketplace or contact NVIDIA to learn more. Harness the full power of massive LLMs with multi-node serving, and power your inference stack with an architecture that can deploy, and serve, models of any size!