AWS HPC Blog
On-demand visual login nodes – using RES with AWS Parallel Computing Service
 AWS Parallel Computing Service (AWS PCS) is a managed service that makes it easier for you to run and scale your high-performance computing (HPC) workloads and build scientific and engineering models on AWS using Slurm. You can use AWS PCS to build complete, elastic environments that integrate compute, storage, networking, and visualization tools. AWS PCS simplifies cluster operations with managed updates and built-in observability features, helping to remove the burden of maintenance.
AWS Parallel Computing Service (AWS PCS) is a managed service that makes it easier for you to run and scale your high-performance computing (HPC) workloads and build scientific and engineering models on AWS using Slurm. You can use AWS PCS to build complete, elastic environments that integrate compute, storage, networking, and visualization tools. AWS PCS simplifies cluster operations with managed updates and built-in observability features, helping to remove the burden of maintenance.
While PCS offers a familiar environment for researchers and engineers to run their compute jobs, individualized access that can scale across research projects is not always easy for every user. Login nodes need to be configured so that researchers can separately connect to the compute nodes and run jobs. Fortunately, this is something that Research and Engineering Studio on AWS (RES) was built for.
So today, we’re happy to show you two methods for integrating PCS with Research and Engineering Studio on AWS (RES). In a later post, we’ll dive into integration of storage and identity with our virtual desktops / login nodes and compute nodes.
AWS Parallel Computing Service, meet RES
RES is an open source, easy-to-use web-based portal for administrators to create and manage secure cloud-based research and engineering environments. With just a few clicks, scientists and engineers can create and connect to virtual desktops (VDIs). Linux VDI users, specifically, can take advantage of direct integration with PCS by turning their Linux VDI into a PCS login node. You can see this integration between RES and PCS in the architecture diagram in Figure 1.
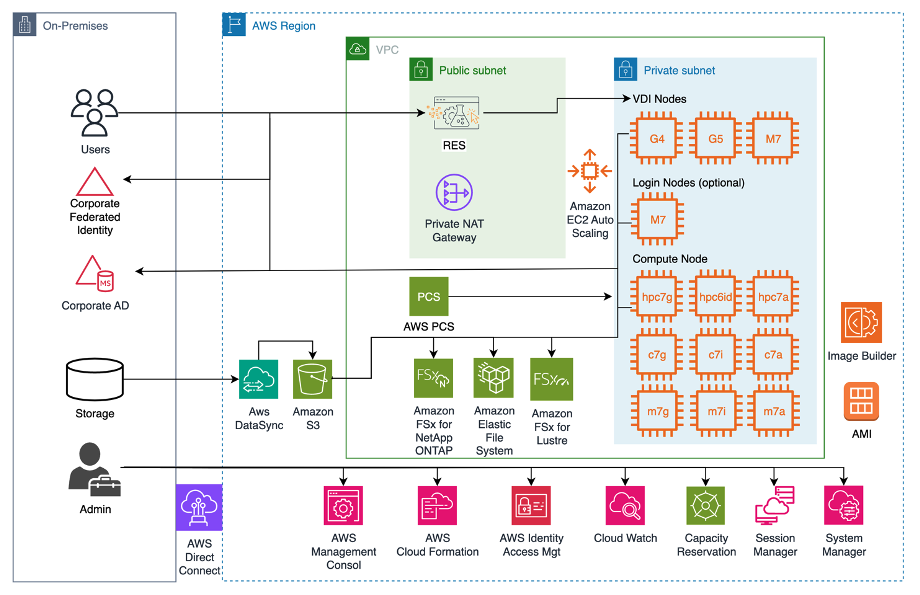
Figure 1 – RES + PCS reference architecture diagram. This diagram depicts how RES and PCS are typically deployed in a customer environment.
Users log into their RES console via their corporate Active Directory credentials and federated identity.
Users then go through RES access their personal VDI sessions, which can provide compute either directly or via PCS compute nodes.
File storage (e.g., Amazon EFS, Amazon FSx for Lustre, and/or Amazon FSx for NetApp ONTAP) are shared across the VDI (i.e., the login node) and compute nodes, with access managed centrally by AD and identity federation. S3 serves as a long-term data storage option.
Lastly, admins deploy and manage the RES and PCS infrastructure via the various other AWS services in the diagram.
Through the rest of this post, we’ll describe the two below methods to transform users’ VDIs into PCS login nodes:
- Option 1: Run a script directly from the VDI (only applies to that particular VDI session)
- Option 2: Create a Software Stack (i.e., AMI) that users can deploy on any VDI in RES [Recommended]
For both options, we’ve created a new HPC Recipe, Creating a RES-ready AWS PCS login node. This recipe is part of the HPC Recipes Library (a great resource, if you’re unfamiliar with it until now).
After you complete either of the two options, users will be able to simply connect to their VDIs via RES and directly submit Slurm jobs to their PCS clusters.
Option 1: Run a script directly from the VDI (only applies to that particular VDI)
If a given RES user already has a VDI deployed, they can simply run a script on the VDI rather than redeploying their VDI with a Software Stack created via option 2. The overall process and script can be accessed in our recipe under Manually enable PCS access on RES VDI instance (Optional). An administrator is needed for this setup as this option requires creation of a new IAM policy for the associated RES Project as well as sudo rights for running the script on the VDI itself.
This option is useful when a user wants to use a RES VDI session they already have provisioned, but is not scalable because running the script – even at boot – will take some time. To easily and more quickly enable integration between RES and PCS on creation of any Linux VDI, we recommend the second option where we create a RES Software Stack, or RES-ready AMI, that any new VDI session can deploy.
Option 2: Create a RES Software Stack (a RES-ready AMI) for any VDI session in RES [Recommended]
Careful followers of this channel might notice that this option is very similar to the method we described in another post about Integrating RES with AWS ParallelCluster. Doing this with AWS PCS is a lot simpler, though, because PCS is a fully-managed service and doesn’t need us to configure a head node.
Before you start, you’ll need the Software Stack you want to use. Follow the steps in our recipe under RES-ready AMI integrated with PCS cluster to create your Software Stack. This also allows you to pre-install RES dependencies and pre-bake software and configuration into your VDI images, improving boot times for your end users.
We start by building EC2 Image Builder components as well as the necessary Image Builder infrastructure using AWS CloudFormation. Our components retrieve the necessary dependencies for PCS and RES, like Slurm, sackd, and more. We’ll integrated these components with a base AMI using an Image Builder recipe and pipeline running on our Amazon Elastic Compute Cloud (Amazon EC2) infrastructure, to produce our final, RES-ready AMI.
EC2 Image Builder simplifies the process of building and maintaining a “golden image” by allowing us to modify and rerun our pipeline when the environment or dependencies change (such as major updates to RES). If you want to know more about Image Builder, there’s a short tutorial about it in on the HPC Tech Shorts YouTube channel.
Once Image Builder finishes creating the RES-ready AMI, a RES admin can login to create the Software Stack in two steps:
- Update a RES Project to add security groups that allow access to the PCS cluster (or create a Project if it’s your first time using RES). The
PCSClusterSGmust be added to any project that requires access to the PCS cluster. This can be added in the RES project Resource Configurations → Advanced Options → Add Security Groups configuration section. - Create a new Software Stack using the RES-ready AMI created from the Image Builder pipeline.
- Assign the Software Stack to a project. Options -> Edit Stack -> Projects
Once the software stack has been created, end-users that have access to it as part of a Project can create their own, dedicated login node virtual desktops.
Virtual desktop login node in action
End-users will access the login node virtual desktop in the same way they access any other virtual desktop.
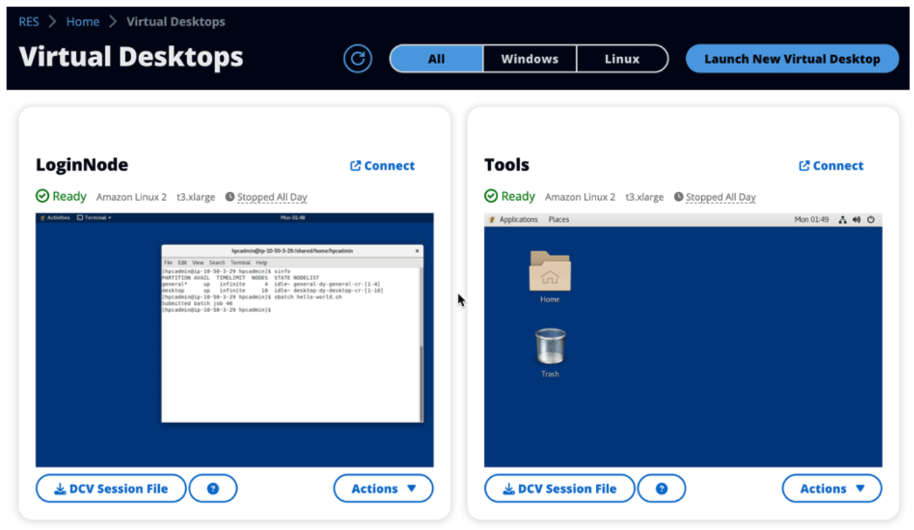
Figure 2 – The Virtual Desktops section contains a VDI (LoginNode) which is a based on a login node compatible with PCS.
Once end users have access to the login node VDI, they can interact with Slurm in the same way they’re accustomed, but via a RES VDI session. This is just like a standalone PCS Login Node with the added benefit that end-users can launch their own login node as a VDI session any time they need one.
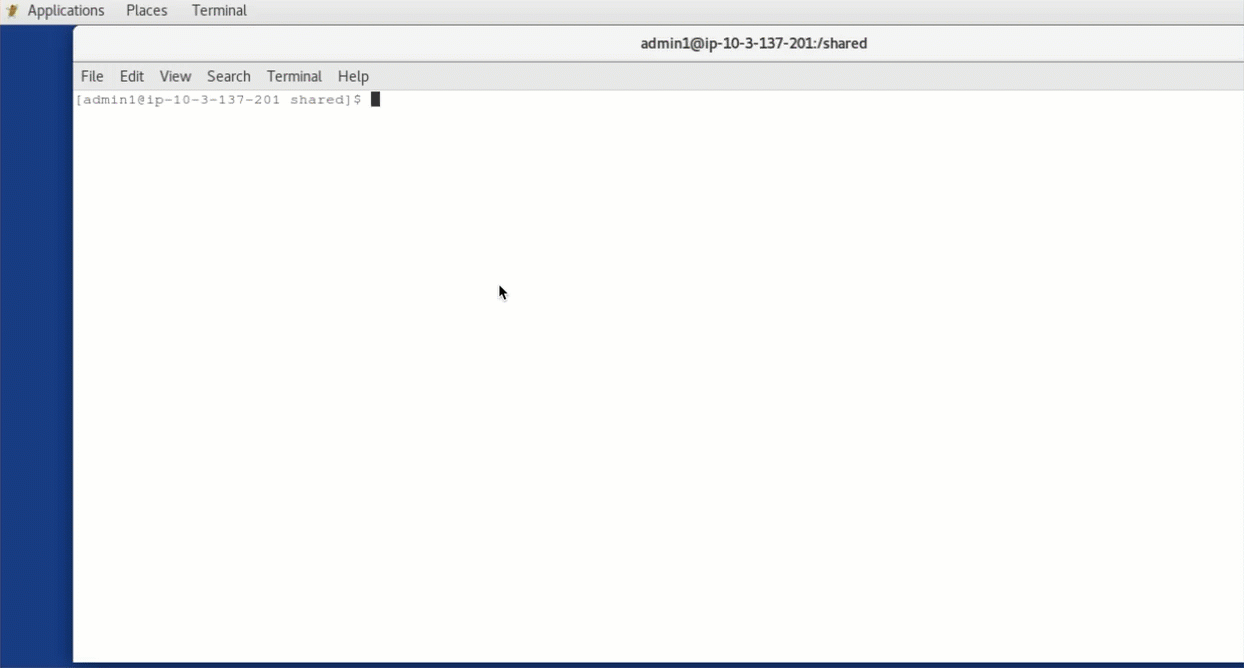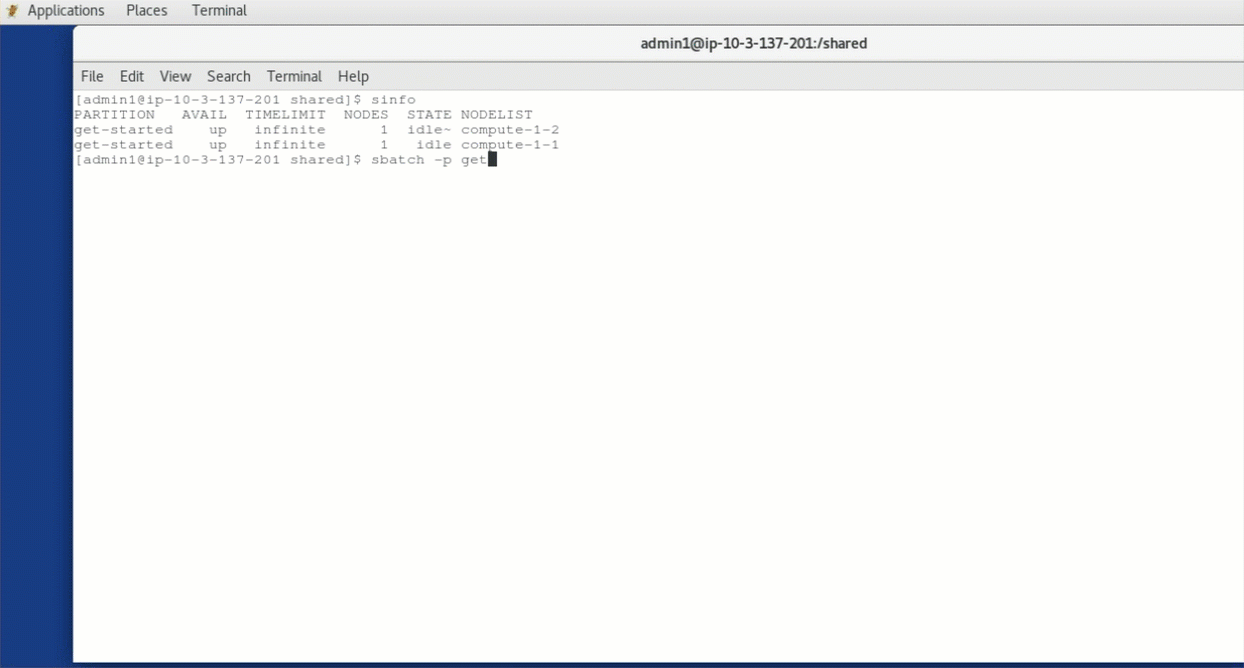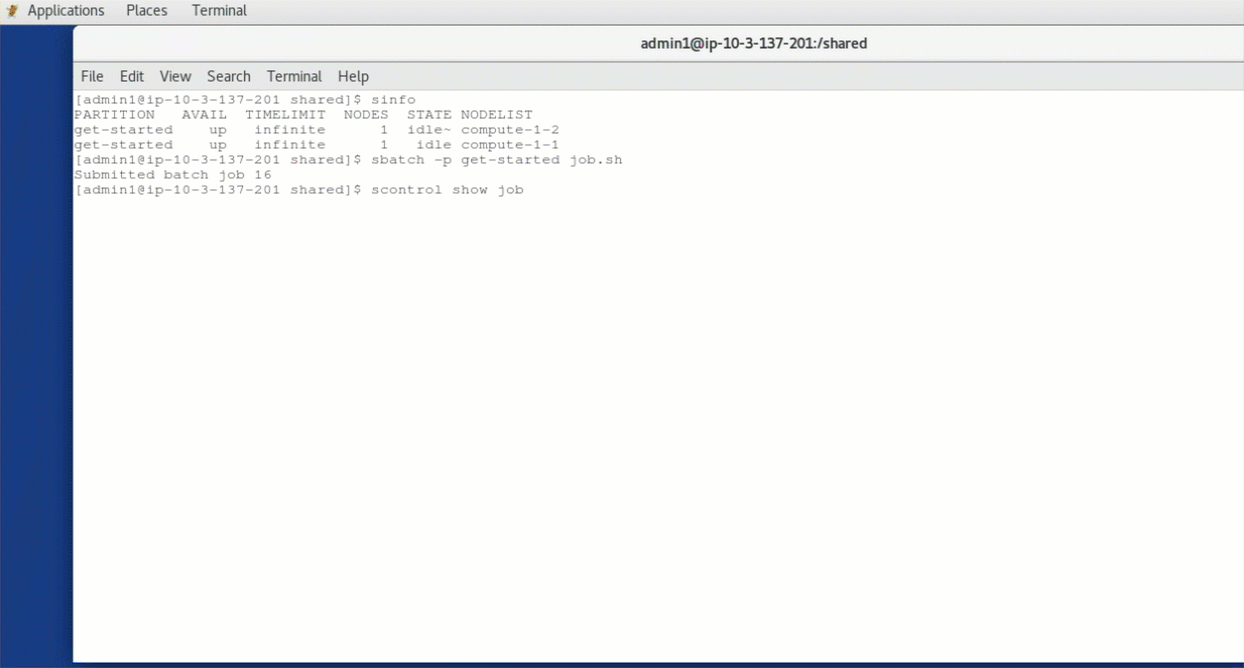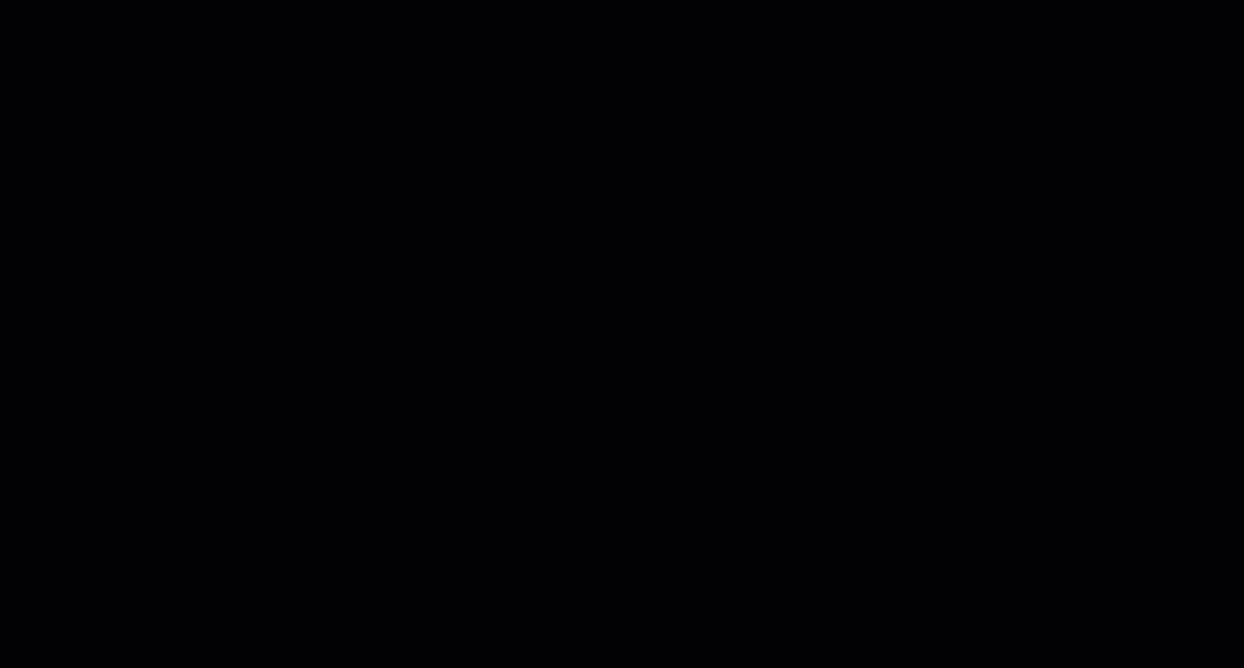
Figure 3 – A virtual desktop session showing examples of Slurm commands demonstrating the integration with PCS.
To provide access to the same shared file storage across RES and PCS, you’ll need to create a PCS launch template. This template mounts your RES file storage (Amazon EFS or perhaps Amazon FSx for Lustre) and integrates your AD to the PCS compute nodes upon job submission. While we will explore this topic in more detail in a later post, you can see examples of shared storage accessed from both a PCS compute node and the RES VDI / PCS login node in Figures 4 and 5.
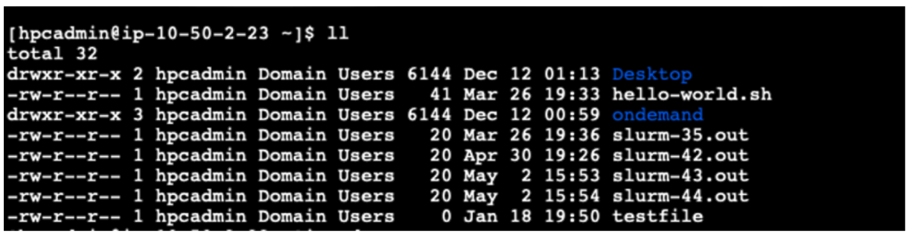
Figure 4 – A terminal session on a PCS compute node showing the user shared storage directory listing
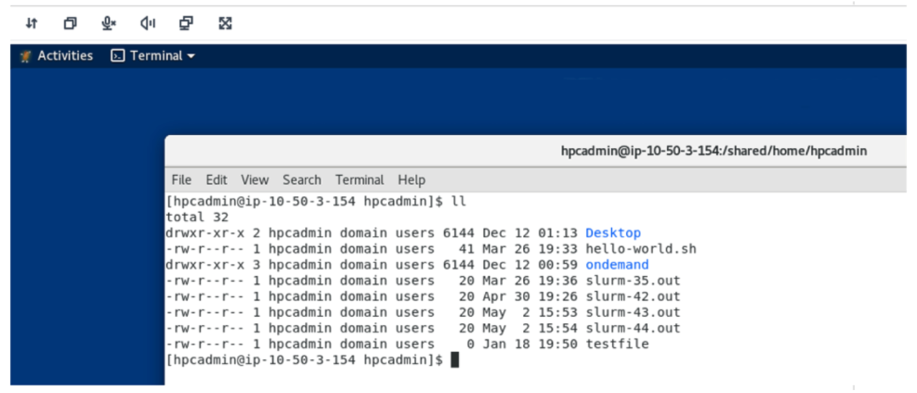
Figure 5 – A RES virtual desktop session showing the same shared storage directory accessible from the RES VDI / PCS Login Node
Conclusion
By integrating AWS PCS and Research and Engineering Studio on AWS, users can access the compute and storage they need via a simple and familiar interface.
RES provides an interface to access a virtual login node desktop and shared storage, while Slurm efficiently manages the compute jobs in AWS Parallel Computing Service. Because PCS is a fully-managed service, the integration and management experience of this solution is even simpler than our previous recipe with AWS ParallelCluster. Teams and departments can quickly get-started today and provide users with the interface and resources they need for their HPC and AIML workloads.