AWS HPC Blog
Launch self-supervised training jobs in the cloud with AWS ParallelCluster
Self-supervised pre-training has advanced the capabilities of computer vision tasks, becoming the most effective way to pre-train models. Labeling of large-scale datasets is time-consuming and expensive, in some cases with a limited number of unlabeled objects to annotate. Consequently, transitioning from supervised (labeled) training to self-supervised pre-training has enabled advances in accuracy without requiring additional hand-crafted labels. Using extensive datasets and large image batch sizes, these self-supervised techniques, ultimately, leads to model improvements over existing baselines.
This blog post describes the process for creating a High Performance Compute (HPC) cluster that will launch large, self-supervised training jobs, primarily leveraging two technologies: AWS ParallelCluster and the Vision Self-Supervised Learning (VISSL) library. AWS ParallelCluster is an open source cluster management tool that facilitates deploying and managing HPC clusters on AWS. VISSL is Facebook’s computer vision library for state-of-the-art self-supervised learning research with PyTorch. VISSL aims to accelerate the research cycle in self-supervised learning: from designing a new self-supervised task to evaluating the learned representations.
Background
Most data scientists are familiar with training a basic image classifier on a single GPU with thousands of images using roughly a hundred epochs and a small batch size. Conversely, self-supervised training jobs are significantly more compute intensive, typically requiring one to several thousand training steps, hundreds of thousands to millions of unlabeled images and batch sizes of several thousand images.
Our solution deploys VISSL on a scalable HPC cluster managed by AWS ParallelCluster. AWS ParallelCluster makes it convenient to spin up many instances within an easily reproducible HPC environment for self-supervised learning experimentation. The HPC environment is comprised of a Head Node and multiple GPU Compute Nodes within a Virtual Private Cloud (VPC) (Figure 1). We use Slurm as a highly scalable cluster management and job scheduling system. Attached to each node in the cluster is a FSx for Lustre file system, which makes it convenient to connect to shared storage that scales in performance for demanding workloads. Integration with Simple Storage service (S3) facilitates the easy addition or removal of training data.
Solution Overview
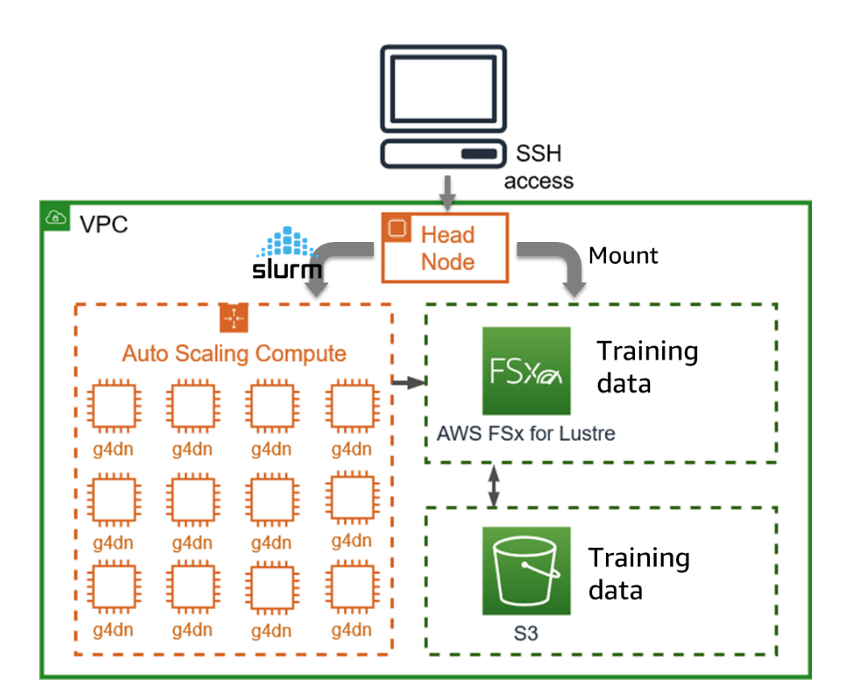
Figure 1 – The HPC environment for self-supervised learning consists of a Head Node and multiple GPU Compute Nodes within a Virtual Private Cloud (VPC). The FSx for Lustre file system, linked to Simple Storage service (S3), simplifies the addition or removal of training data.
An accompanying HPC workshop provides step-by-step instructions to create a cluster and perform an initial training job. There are several key steps involved.
Create a Virtual Private Cloud (VPC) – ParallelCluster is deployed within a pre-configured VPC.
Build a Custom AWS ParallelCluster AMI – an Amazon Machine Image (AMI) is a customizable template containing a specific software configuration that can be deployed to an Amazon Elastic Compute Cloud (EC2) instance. During the workshop, participants will use a publicly available custom-built AMI for self-supervised learning.
Create AWS ParallelCluster cluster configuration and deploy – update the cluster configuration files and use ParallelCluster to deploy and monitor its creation. ParallelCluster also deploys an Amazon FSx for Lustre file system.
Create an Amazon S3 bucket – FSx for Lustre will load datasets from a user-created Amazon Simple Storage Service (Amazon S3) bucket, where the training data is stored.
Launch a training job – once logged into the head node of the cluster, start the self-supervised training job.
Environment cleanup – once the experiments are complete, delete the created resources: Cluster, FSx for Lustre, Amazon S3, VPC.
Conclusion
In this post, we discussed the motivation for creating an AWS ParallelCluster: creating a highly scalable and reproducible cluster environment for self-supervised experiments.
We also described the major steps involved, with step-by-step instructions in an accompanying workshop. The Workshop describes: how to build a custom AMI starting from a running instance; the steps to create an FSx for Lustre system to connect to S3; how to create an AWS ParallelCluster from the generated image; and finally, steps to train on a publicly available dataset and output a pre-trained model.