AWS HPC Blog
HPC Ops: DevOps for HPC workloads in the cloud
 HPC environments are known for their computational complexity and resource-intensive workloads. Just setting up robust infrastructure for HPC applications can be a daunting task, often requiring extensive manual effort and specialized expertise.
HPC environments are known for their computational complexity and resource-intensive workloads. Just setting up robust infrastructure for HPC applications can be a daunting task, often requiring extensive manual effort and specialized expertise.
This is where HPC Operations (HPC Ops) comes into play It combines DevOps practices, Infrastructure as Code (IaC), cloud computing, and CI/CD (continuous integration and continuous deployment) to streamline and automate the entire lifecycle of HPC applications.
In this post we’ll introduce you to the key concepts of HPC Ops. CI/CD is an integral part of the story because it helps admins to provision, deploy, and manage compute resources automatically, so you get consistent and reproducible setups every time. This doesn’t just reduce the risk of human error – it can mean faster iterations, and of course: more experimentation. All of this lets you keep pace with the changing needs of your users’ workloads – boosting everyone’s productivity.
Solution overview
For this exercise, we’ll use several services, some of which you might not be familiar with.
We’ll use AWS ParallelCluster to create our clusters using blueprints expressed in a simple text configuration file. ParallelCluster is an open-source tool that makes it easy to deploy and manage HPC clusters.
AWS CloudFormation is our primary infrastructure as code (IaC) service, because it allows you to conjure nearly anything in AWS from a recipe file (or “stack”), by defining what you want and how it relates to other resources. This is a great way of baking many of the details about your preferred environment into text files that you can manage in a source-code repo.
AWS CodeCommit – a fully-managed source control service that hosts secure Git-based repositories in the AWS Cloud. AWS CodePipeline – a fully managed continuous delivery service that automates the release pipeline for applications.
Amazon Simple Storage Service (Amazon S3) will store the deployment artifacts. And we’ll lean on AWS Lambda, which lets you run code without provisioning or managing actual servers (it’s part of our “serverless” suite of tools).
Architecture of the solution
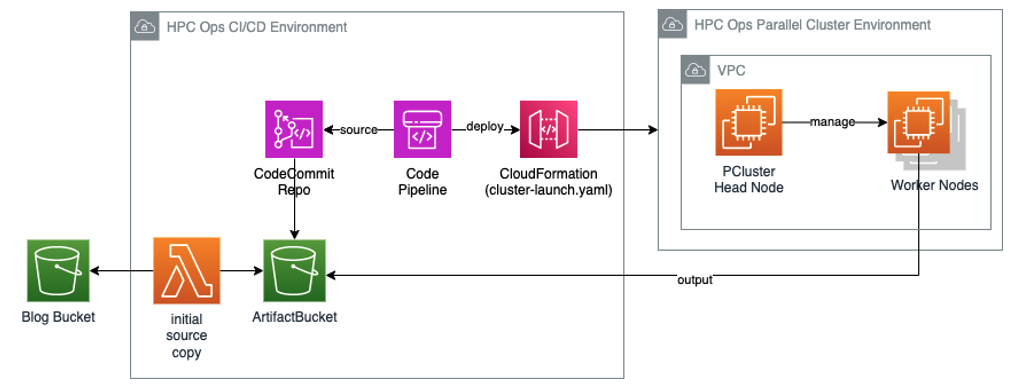
Figure 1 – The diagram illustrates the overall architecture of the CI/CD environment and the HPC Cluster environment. The work nodes in the HPC Cluster environment generate output, which is subsequently saved in the ArtifactBucket, a storage resource created during the deployment of the CI/CD environment.
In our solution, we’ll initially deploy using CloudFormation.
Integrating CI/CD practices into your workflow is crucial to make all this work. The hpc-ops-ci-cd.yaml CloudFormation template that you’ll download later simplifies this task by automating the deployment of CI/CD pipelines. This template sets up the necessary pipelines and provisions an S3 bucket, populated with essential files for initializing a CodeCommit repository.
It also creates some Identity and Access Manager (IAM) roles to support this:
CodeBuildPipelineRole– used by the code build pipeline to manage builds and build artifactsHPCDeploymentServiceRole– used by CloudFormation, triggered through CodePipeline, to create the HPC cluster, including the SSH key pair, Virtual Private Cloud (VPC), subnets, head node, and worker nodes.HPCCloudFormationStackTerminationRole– enables the worker-node-test-script.sh script to terminate the cluster and associated resources, including the VPC and subnets.
Using this template will eliminate the need for manual intervention and will handle the deployment of the HPC cluster. Once the cluster is up and running, it will automatically execute your workloads. When those workloads finish, the pipeline will terminate the cluster – saving on your costs, and automatically eliminating waste.
How does this work?
The hpc-ops-ci-cd.yaml template deploys the CI/CD pipeline and creates a CodeCommit repository. The repository stores the Cluster-launch.yaml CloudFormation launch template which (using IaC principles) defines the actual HPC cluster and workload.
When the CI/CD pipeline is kicked off (by you, or by some automation), it creates all the necessary HPC cluster infrastructure – SSH keys, networking, a head node, and cluster worker nodes. Figure 2 illustrates the responsibility of each CloudFormation template.
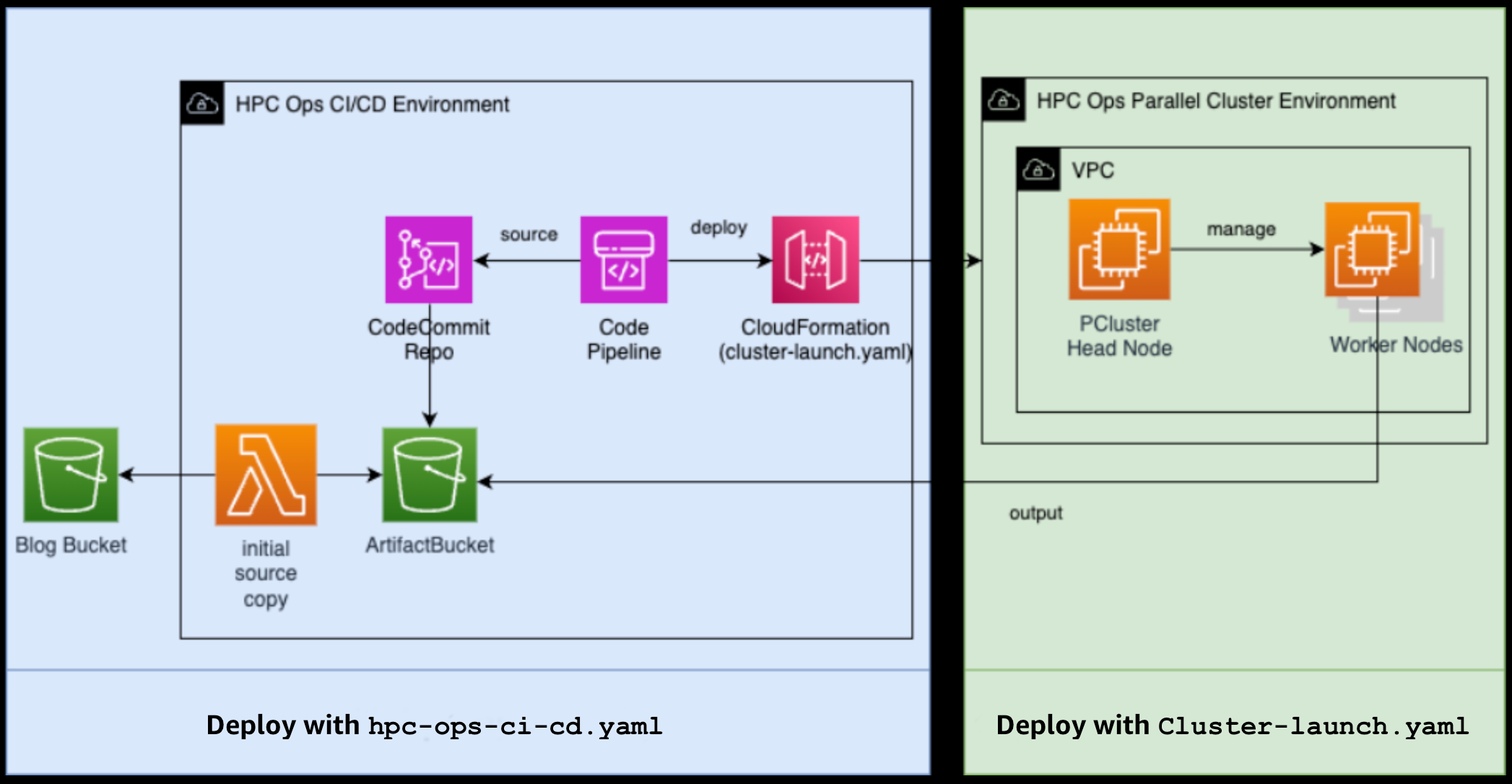
Figure 2 – The diagram illustrates the two distinct components of the HPC operations setup. The hpc-ops-ci-cd.yaml template is responsible for deploying the CI/CD infrastructure, which enables automated workflows. The Cluster-launch.yaml template handles the deployment of the actual HPC cluster environment, including the provisioning of computational resources and the execution of workloads.
To get a better understanding of what Cluster-launch.yaml does, Figure 3 illustrates the sequence of steps once the pipeline is kicked off.
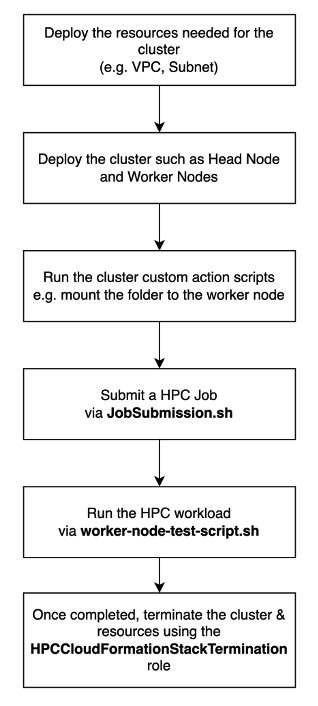
Figure 3 – By using the Cluster-launch.yaml template initiated by the CI/CD pipeline, you can automatically deploy your cluster to have workloads executed and monitored. Then, when the jobs are complete, it terminates the cluster – streamlining the entire process.
The cluster configuration itself is located inside the Cluster-launch.yaml template under Resources/PclusterCluster/Properties/ClusterConfiguration, as you can see in this snippet from the stack.
ClusterConfiguration:
. . .
HeadNode:
CustomActions:
OnNodeConfigured:
Sequence:
- Script: https://raw.githubusercontent.com/aws-samples/hpcops-automation/main/cluster-automation/job-submission.sh
Args:
- !Sub ${AWS::StackName}
- !Sub ${AWS::Region}
- !Ref CloudFormationManagementRole
. . .
Scheduling:
Scheduler: slurm
. . .
CustomActions:
OnNodeConfigured:
Sequence:
- Script: https://aws-hpc-recipes.s3.us-east-1.amazonaws.com/main/recipes/storage/mountpoint_s3/assets/install.sh
- Script: https://aws-hpc-recipes.s3.us-east-1.amazonaws.com/main/recipes/storage/mountpoint_s3/assets/mount.sh
Args:
- !Ref ArtifactBucketName
- /ArtifactBucket
This section allows you to customize configuration settings (and you can find more details about your options in the ParallelCluster configuration documentation).
In this case, we also used Mountpoint for Amazon S3 to mount an Amazon S3 bucket like a POSIX folder on the worker nodes. The worker-node-test-script.sh script then just writes output to this folder, like normal. Mounting the Amazon S3 Bucket enables the output to persist beyond the lifetime of the cluster. You can also use other AWS persistent storages like Amazon EFS or Amazon FSx for Lustre that may work better for your workload – depending on your I/O requirements.
Customizing your cluster setup and workloads is a breeze with this solution. You have the flexibility to tailor the configuration to suit your local needs and preferences – just by editing the template. This lets you create a truly personalized computing environment that caters to your users’ workloads.
When setting up your ParallelCluster environment, the job-submission.sh script plays a crucial role to initiate your workloads on the worker nodes. ParallelCluster automatically executes this after the head node configuration completes – this is in the OnNodeConfigured section in the sample config we just showed you. The script use Slurm to schedule jobs on the worker nodes. This gets your code running across multiple nodes and – since Slurm influences how ParallelCluster scales the compute fleet – optimizes your compute utilization by scaling the fleet down when jobs are done.
To see how simple this is for running your workloads, let’s look at an example worker-node-test-script.sh. This script writes log messages to the designated S3 bucket, which we mounted using Mountpoint for S3. However, the real power lies in your ability to replace the content of this script with your own workloads, which doesn’t take much work.
#!/bin/bash
echo `date +'%F %R:%S'` "INFO: Logging Setup" >&2
set -u
echo "Cluster Stack Name $1. Workload ran at $(date)" > /ArtifactBucket/output-"`date +"%d-%m-%Y-%H-%M-%S"`".txt
aws cloudformation delete-stack --stack-name $1 --region $2
exit 0
Once you deploy the solution and the workload runs, the cluster will be automatically terminated in the last step of the worker-node-test-script.sh script. If you wanted to preserve the cluster, you could simply remove the line that calls the command aws cloudformation delete-stack.
The script makes use of a role called HPCCloudFormationStackTerminationRole (which the deployment process created) to terminate the cluster after completing the workload execution. This approach follows the principle of provisioning the cluster on-demand, spinning it up only when required and decommissioning it when the workload is finished – again ensuring efficient resource use and controlling your costs.
From a security standpoint, we specifically designed this role to be assumed by the ComputeNode only, ensuring strict access control. Furthermore, its permissions are limited to deleting the CloudFormation stack created by the deployed stack. This approach adheres to the principle of least privilege – promoting best security practices by granting only the necessary access required for a function.
Deployment steps
If you want to follow along, you can find the CloudFormation template in our GitHub repo.
- Go to your CloudFormation console to create a Stack.
- Select Upload a template File under Specify template, and then click on Choose file to upload the file you downloaded from GitHub. Click on the Next button to continue.
- Follow the instructions in the AWS CloudFormation console. Select a Unique Name for the bucket or use an existing bucket that this account has access to. You can leave the rest of the parameters to their defaults, as shown in Figure 4.
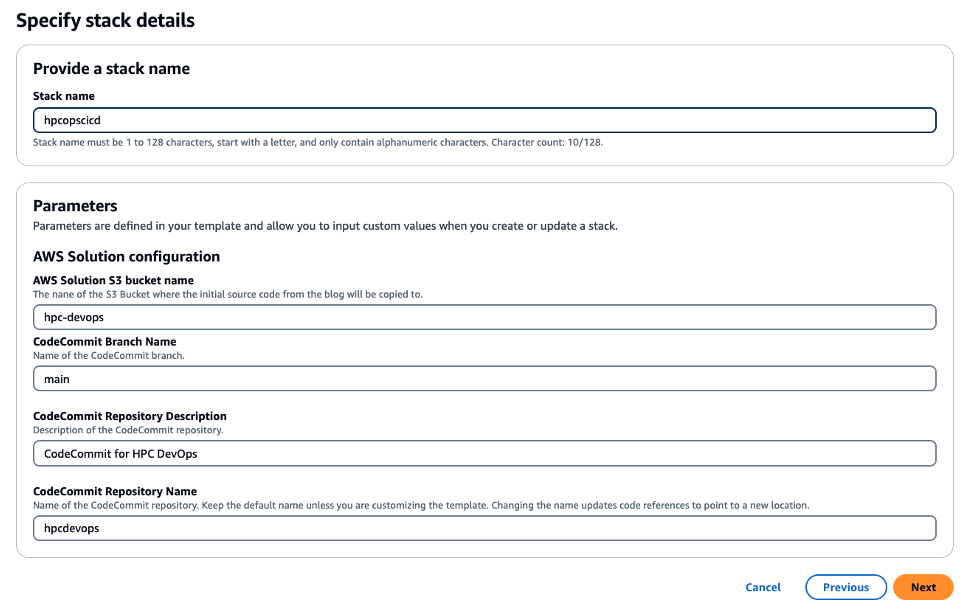
Figure 4 – The CloudFormation parameters used to create the CI/CD stack. These parameters allow the customization of various aspects of the deployment, like the artifact bucket and CodeCommit parameters.
- Check the CloudFormation deployment – On you CloudFormation console home, you’ll see several stacks that have been deployed for you similar to Figure 5. The last stack on the list is the CI/CD stack (for example, the
hpcopscicdstack). The other stacks, which have names starting withhpcdevopsare the ParallelCluster deployments. Go to each stack to inspect the resources it has created.
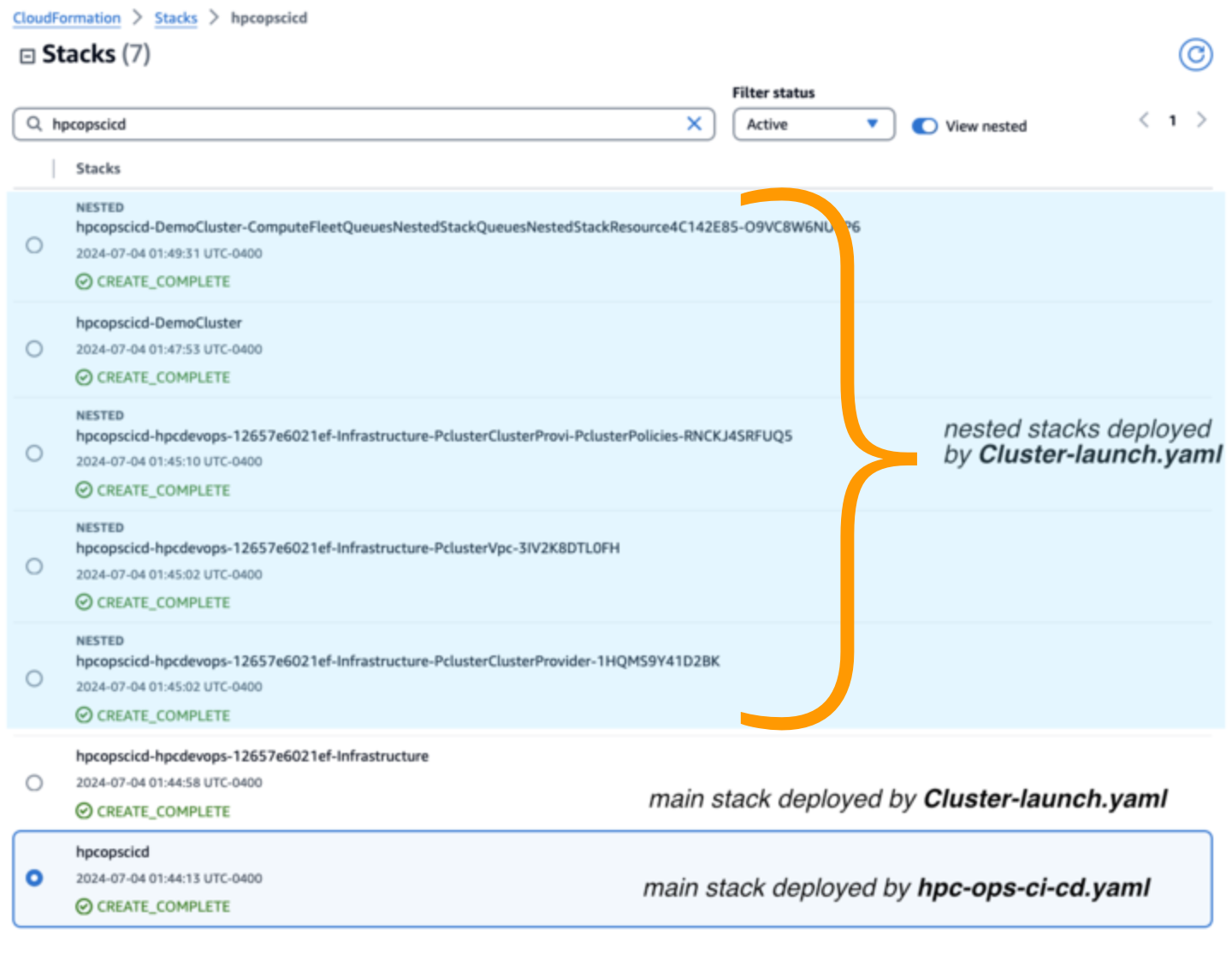
Figure 5 – The stack status for the main stack and nested stacks deployed by the hpc-ops-ci-cd.yaml and cluster-launch.yaml files in the AWS CloudFormation console.
- Check the processing result output – Once the deployment completes, the worker node will run a simple workload and output the result to a file in the bucket you provided as an input parameter to the CloudFormation template in Step 2. The output filename will be
output-<date and time of the run>.txtin the root of theArtifactBucket.
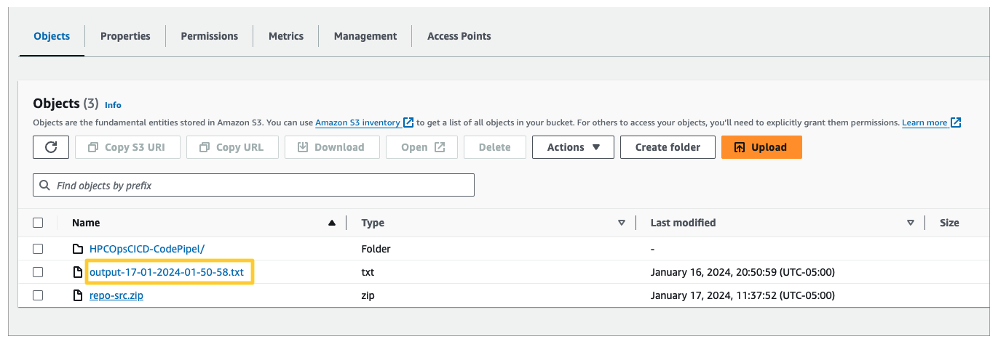
Figure 6 – the image shows the result of deploying the cluster-launch.yaml template, which is responsible for deploying the HPC cluster and running the workload. The workload output generated during the process is stored in the Artifact Bucket.
Once the workload has successfully run, the run script will shut down the cluster, as we previously described – it will delete the cluster CloudFormation stack. You can view the shutdown and deletion process in the CloudFormation console home after triggers. CloudFormation will delete the cluster stacks in order.
We’ve designed our clusters to be ephemeral to minimize the waiting time between jobs. If you need more processing power, you can add more to spin up in parallel. Then you can provide each job the exact resources it needs to run quickly.
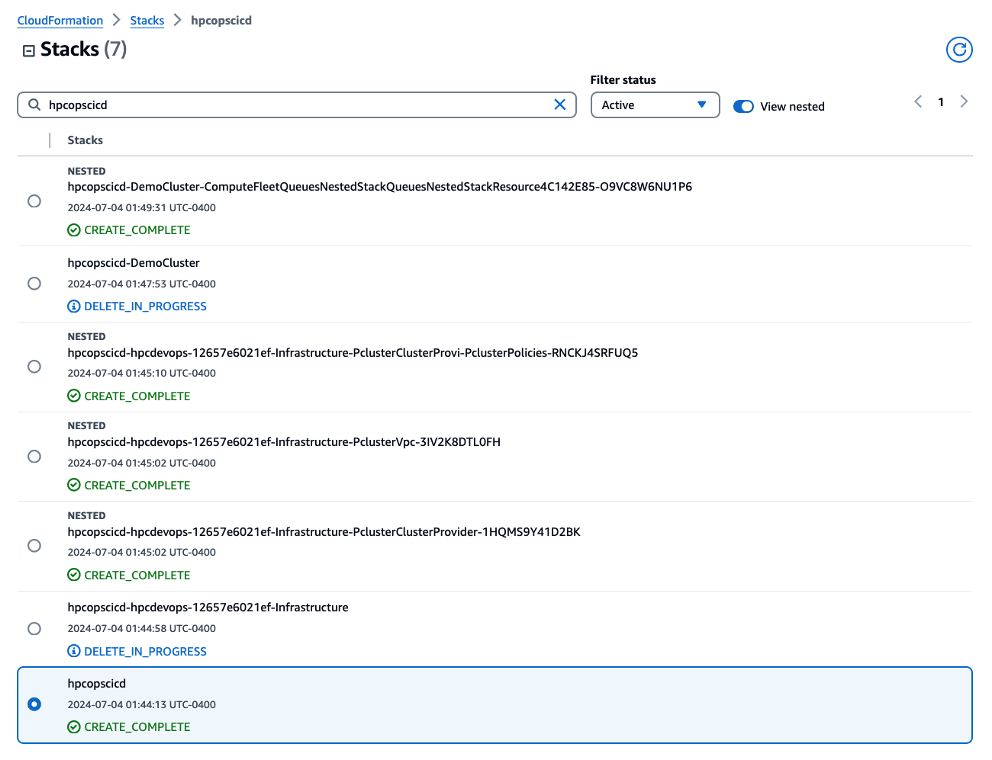
Figure 7 – The image illustrates the state of the CloudFormation stacks after the workload has been executed, and the HPC cluster is being decommissioned. The CloudFormation Console displays the stack status as “DELETE_IN_PROGRESS” for the relevant cluster stacks, indicating that the automatic termination process has been initiated.
Spinning up another cluster
To create a new cluster to process additional workloads, you can use the deployment pipeline that was set up for you. In the AWS CodePipeline console, you’ll see a pipeline that starts with the name you specified for your stack in step 2 (see Figure 8). To build a new cluster and rerun your workload on it, go to the CodePipeline page and select Release change (see Figure 8). This will trigger the pipeline to spin up a fresh cluster that you can then use for further processing.
If you want to set up an additional HPC cluster with different parameters or workloads, you can clone the existing pipeline. Cloning the pipeline lets you to run multiple clusters in parallel, each configured for different purposes or workloads with different datasets.
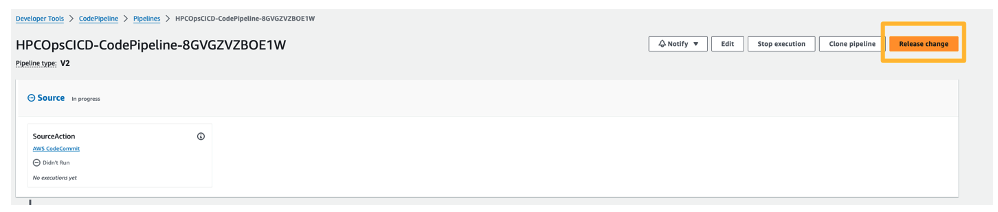
Figure 8 – By clicking on the “Release Change” button in the AWS CodePipeline created by this solution, the CI/CD pipeline will initiate a series of automated actions, including the redeployment of the HPC cluster, the execution of the desired workload, and the subsequent decommissioning of the cluster resources upon completion.
Conclusion
AWS enables automated deployment of HPC environments. This allows teams to quickly use managed services to build and access powerful capabilities. By automating environments like this, organizations can greatly reduce the time and expense they previously carried for on-premises HPC investments.
This makes robust HPC accessible for a greater number of industries and workloads that need complex computations.
Embracing automation also brings new agility to HPC teams. Instead of lengthy planning cycles, groups can spin up HPC resources quickly. If their needs change (which they almost always will), flexible AWS services allow adjusting resources up or down precisely.
By combining ease-of-use with expertise, accessibility and scalability barriers can be lowered. Cloud automation applied to HPC lets groups keep pace with shifting demands.
You can use this AWS HPC solution for your own workloads and tailor the environment specifically for your needs. you can find this blueprint in our GitHub repo.