AWS HPC Blog
Category: Compute
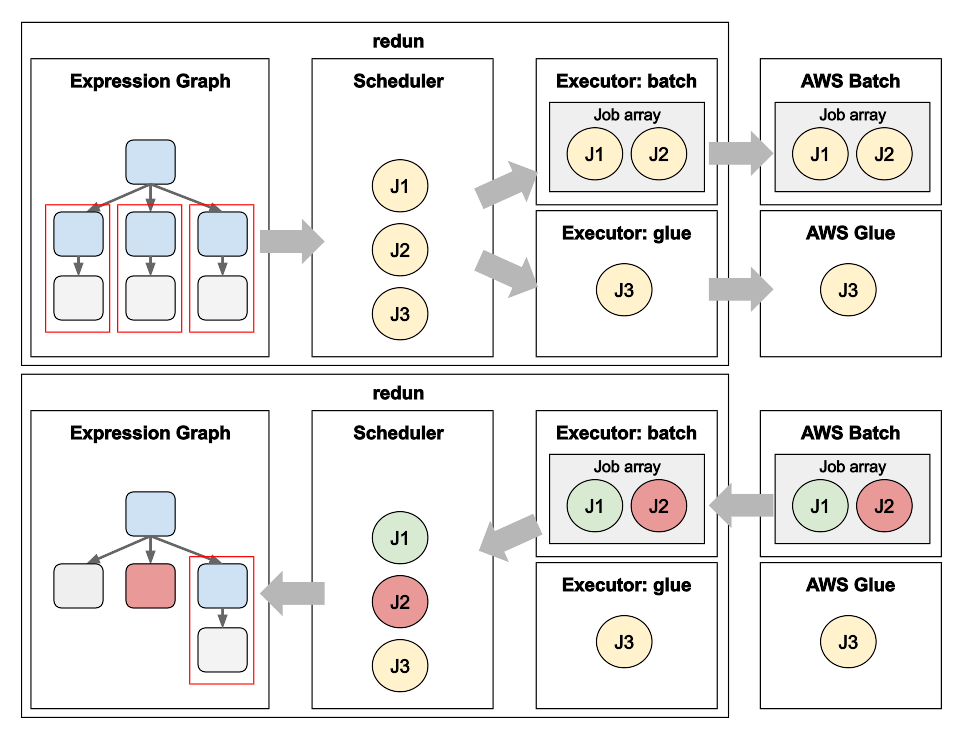
Data Science workflows at insitro: how redun uses the advanced service features from AWS Batch and AWS Glue
Matt Rasmussen, VP of Software Engineering at insitro, expands on his first post on redun, insitro’s data science tool for bioinformatics, to describe how redun makes use of advanced AWS features. Specifically, Matt describes how AWS Batch’s Array Jobs is used to support workflows with large fan-out, and how AWS Glue’s DynamicFrame is used to run computationally heterogenous workflows with different back-end needs such as Spark, all in the same workflow definition.

Data Science workflows at insitro: using redun on AWS Batch
Matt Rasmussen, VP of Software Engineering at insitro describes their recently released, open-source data science framework, redun, which allows data scientists to define complex scientific workflows that scale from their laptop to large-scale distributed runs on serverless platforms like AWS Batch and AWS Glue. I this post, Matt shows how redun lends itself to Bioinformatics workflows which typically involve wrapping Unix-based programs that require file staging to and from object storage. In the next blog post, Matt describes how redun scales to large and heterogenous workflows by leveraging AWS Batch features such as Array Jobs and AWS Glue features such as Glue DynamicFrame.

Migrating to AWS ParallelCluster v3 – Updated CLI interactions
The AWS ParallelCluster version 3 CLI differs significantly from ParallelCluster version 2. This post provides some guidance on mapping between versions to help you with migrating to ParallelCluster 3. We also summarize new CLI features in ParallelCluster 3 to expose the things you just couldn’t do previously.

Choosing between AWS Batch or AWS ParallelCluster for your HPC Workloads
It’s an understatement that AWS has a lot of services (more than 200 at the time of this post!). We’re usually the first to point out that there’s more than one way to solve a problem. HPC is no different in this regard, because we offer a choice: customers can run their HPC workloads using AWS […]
Optimize your Monte Carlo simulations using AWS Batch
Introduction Monte Carlo methods are a class of methods based on the idea of sampling to study mathematical problems for which analytical solutions may be unavailable. The basic idea is to create samples through repeated simulations that can be used to derive approximations about a quantity we’re interested in, and its probability distribution. In this […]
GROMACS performance on Amazon EC2 with Intel Ice Lake processors
We recently launched two new Amazon EC2 instance families based on Intel’s Ice Lake – the C6i and M6i. These instances provide higher core counts and take advantage of generational performance improvements on Intel’s Xeon scalable processor family architectures. In this post we show how GROMACS performs on these new instance families. We use similar methodologies as for previous posts where we characterized price-performance for CPU-only and GPU instances (Part 1, Part 2, Part 3), providing instance recommendations for different workload sizes.

Introducing AWS ParallelCluster multiuser support via Active Directory
Today we’re announcing the release of AWS ParallelCluster 3.1 which now supports multiuser authentication based on Active Directory (AD). Starting with v3.1.1 clusters can be configured to use an AD domain managed via one of the AWS Directory Service options like Simple AD or AWS Managed Microsoft AD (MSAD). This blog post describes the new feature, and gives an example of a configuration block for ParallelCluster 3 configuration files.
How to Arm a world-leading forecast model with AWS Graviton and Lambda
The Met Office is the UK’s National Meteorological Service, providing 24×7 world-renowned scientific excellence in weather, climate and environmental forecasts and severe weather warnings for the protection of life and property. They provide forecasts and guidance for the public, to our government and defence colleagues as well as the private sector. As an example, if you’ve been on a plane over Europe, Middle East, or Africa; that plane took off because the Met Office (as one of two World Aviation Forecast Centres) provided a forecast. This article explains one of the ways they use AWS to collect these observations, which has freed them to focus more on top quality delivery for their customers.

Using the ParallelCluster 3 Configuration Converter
ParallelCluster 3 was a major release with several changes and a lot of new features. To help get you started migrating your clusters, we describe the config file converter tool which is part of the ParallelCluster (>= v3.0.1) command line interface (CLI).

Using Spot Instances with AWS ParallelCluster and Amazon FSx for Lustre
Processing large amounts of complex data often requires leveraging a mix of different Amazon EC2 instance types. These types of computations also benefit from shared, high performance, scalable storage like Amazon FSx for Lustre. A way to save costs on your analysis is to use Amazon EC2 Spot Instances, which can help to reduce EC2 costs up to 90% compared to On-Demand Instance pricing. This post will guide you in the creation of a fault-tolerant cluster using AWS ParallelCluster. We will explain how to configure ParallelCluster to automatically unmount the Amazon FSx for Lustre filesystem and resubmit the interrupted jobs back into the queue in the case of Spot interruption events.