AWS DevOps & Developer Productivity Blog
Using AWS CodePipeline for deploying container images to AWS Lambda Functions
AWS Lambda launched support for packaging and deploying functions as container images at re:Invent 2020. In the post working with Lambda layers and extensions in container images, we demonstrated packaging Lambda Functions with layers while using container images. This post will teach you to use AWS CodePipeline to deploy docker images for microservices architecture involving multiple Lambda Functions and a common layer utilized as a separate container image. Lambda functions packaged as container images do not support adding Lambda layers to the function configuration. Alternatively, we can use a container image as a common layer while building other container images along with Lambda Functions shown in this post. Packaging Lambda functions as container images enables familiar tooling and larger deployment limits.
Here are some advantages of using container images for Lambda:
- Easier dependency management and application building with container
- Install native operating system packages
- Install language-compatible dependencies
- Consistent tool set for containers and Lambda-based applications
- Utilize the same container registry to store application artifacts (Amazon ECR, Docker Hub)
- Utilize the same build and pipeline tools to deploy
- Tools that can inspect Dockerfile work the same
- Deploy large applications with AWS-provided or third-party images up to 10 GB
- Include larger application dependencies that previously were impossible
When using container images with Lambda, CodePipeline automatically detects code changes in the source repository in AWS CodeCommit, then passes the artifact to the build server like AWS CodeBuild and pushes the container images to ECR, which is then deployed to Lambda functions.
Architecture Diagram
DevOps Architecture
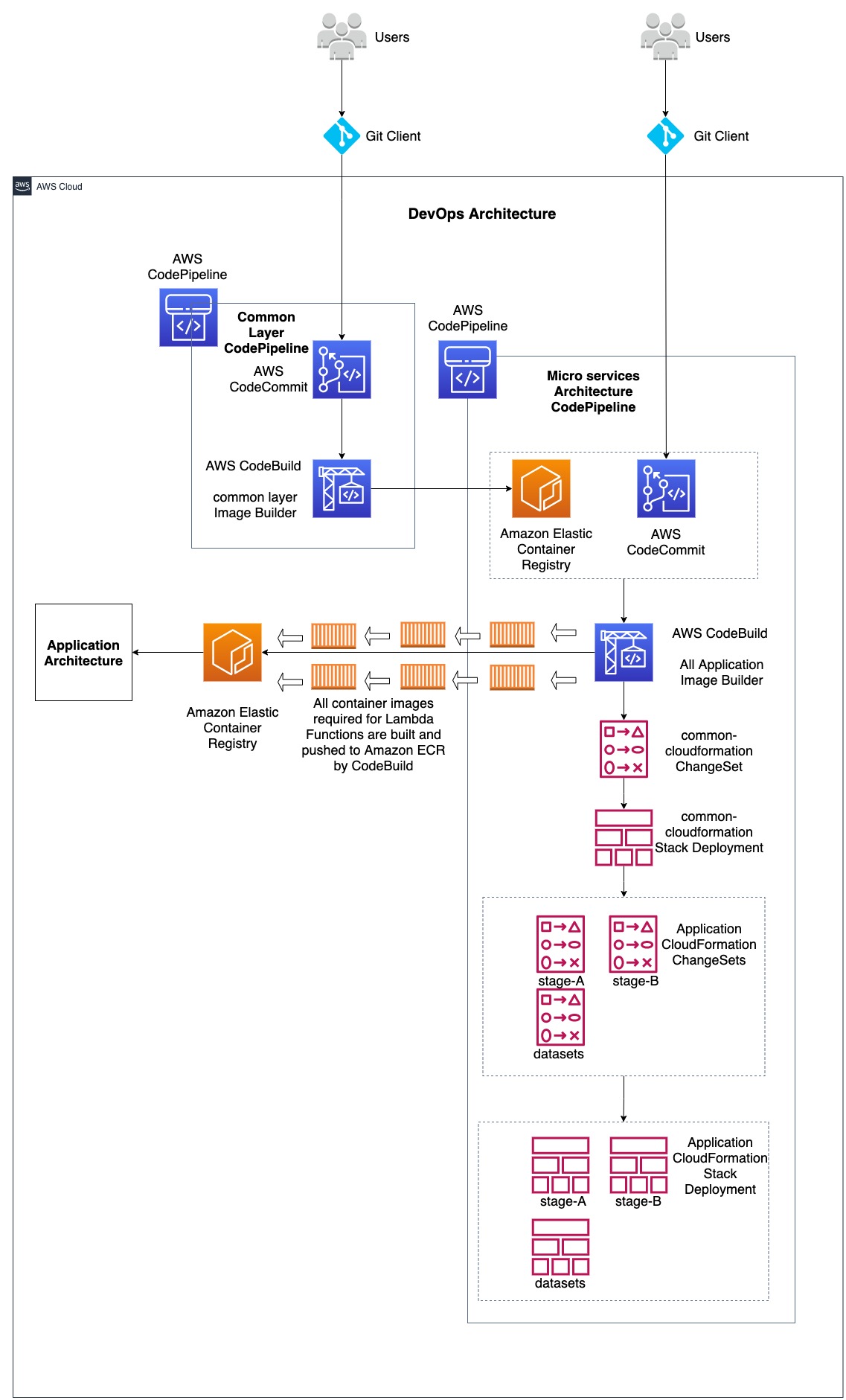
Application Architecture

In the above architecture diagram, two architectures are combined, namely 1, DevOps Architecture and 2, Microservices Application Architecture. DevOps architecture demonstrates the use of AWS Developer services such as AWS CodeCommit, AWS CodePipeline, AWS CodeBuild along with Amazon Elastic Container Repository (ECR) and AWS CloudFormation. These are used to support Continuous Integration and Continuous Deployment/Delivery (CI/CD) for both infrastructure and application code. Microservices Application architecture demonstrates how various AWS Lambda Functions that are part of microservices utilize container images for application code. This post will focus on performing CI/CD for Lambda functions utilizing container containers. The application code used in here is a simpler version taken from Serverless DataLake Framework (SDLF). For more information, refer to the AWS Samples GitHub repository for SDLF here.
DevOps workflow
There are two CodePipelines: one for building and pushing the common layer docker image to Amazon ECR, and another for building and pushing the docker images for all the Lambda Functions within the microservices architecture to Amazon ECR, as well as deploying the microservices architecture involving Lambda Functions via CloudFormation. Common layer container image functions as a common layer in all other Lambda Function container images, therefore its code is maintained in a separate CodeCommit repository used as a source stage for a CodePipeline. Common layer CodePipeline takes the code from the CodeCommit repository and passes the artifact to a CodeBuild project that builds the container image and pushes it to an Amazon ECR repository. This common layer ECR repository functions as a source in addition to the CodeCommit repository holding the code for all other Lambda Functions and resources involved in the microservices architecture CodePipeline.
Due to all or the majority of the Lambda Functions in the microservices architecture requiring the common layer container image as a layer, any change made to it should invoke the microservices architecture CodePipeline that builds the container images for all Lambda Functions. Moreover, a CodeCommit repository holding the code for every resource in the microservices architecture is another source to that CodePipeline to get invoked. This has two sources, because the container images in the microservices architecture should be built for changes in the common layer container image as well as for the code changes made and pushed to the CodeCommit repository.
Below is the sample dockerfile that uses the common layer container image as a layer:
ARG ECR_COMMON_DATALAKE_REPO_URL
FROM ${ECR_COMMON_DATALAKE_REPO_URL}:latest AS layer
FROM public.ecr.aws/lambda/python:3.8
# Layer Code
WORKDIR /opt
COPY --from=layer /opt/ .
# Function Code
WORKDIR /var/task
COPY src/lambda_function.py .
CMD ["lambda_function.lambda_handler"]
where the argument ECR_COMMON_DATALAKE_REPO_URL should resolve to the ECR url for common layer container image, which is provided to the --build-args along with docker build command. For example:
export ECR_COMMON_DATALAKE_REPO_URL="0123456789.dkr.ecr.us-east-2.amazonaws.com/dev-routing-lambda"
docker build --build-arg ECR_COMMON_DATALAKE_REPO_URL=$ECR_COMMON_DATALAKE_REPO_URL .Deploying a Sample
- Step1: Clone the repository Codepipeline-lambda-docker-images to your workstation. If using the zip file, then unzip the file to a local directory.
-
git clone https://github.com/aws-samples/codepipeline-lambda-docker-images.git
-
- Step 2: Change the directory to the cloned directory or extracted directory. The local code repository structure should appear as follows:
-
cd codepipeline-lambda-docker-images
-

- Step 3: Deploy the CloudFormation stack used in the template file
CodePipelineTemplate/codepipeline.yamlto your AWS account. This deploys the resources required for DevOps architecture involving AWS CodePipelines for common layer code and microservices architecture code. Deploy CloudFormation stacks using the AWS console by following the documentation here, providing the name for the stack (for exampledatalake-infra-resources) and passing the parameters while navigating the console. Furthermore, use the AWS CLI to deploy a CloudFormation stack by following the documentation here. - Step 4: When the CloudFormation Stack deployment completes, navigate to the AWS CloudFormation console and to the Outputs section of the deployed stack, then note the CodeCommit repository urls. Three CodeCommit repo urls are available in the CloudFormation stack outputs section for each CodeCommit repository. Choose one of them based on the way you want to access it. Refer to the following documentation Setting up for AWS CodeCommit. I will be using the git-remote-codecommit (grc) method throughout this post for CodeCommit access.
- Step 5: Clone the CodeCommit repositories and add code:
-
- Common Layer CodeCommit repository: Take the value of the Output for the key oCommonLayerCodeCommitHttpsGrcRepoUrl from
datalake-infra-resourcesCloudFormation Stack Outputs section which looks like below:
- Common Layer CodeCommit repository: Take the value of the Output for the key oCommonLayerCodeCommitHttpsGrcRepoUrl from

-
- Clone the repository:
git clone codecommit::us-east-2://dev-CommonLayerCode
- Change the directory to dev-CommonLayerCode
cd dev-CommonLayerCode
- Add contents to the cloned repository from the source code downloaded in Step 1. Copy the code from the CommonLayerCode directory and the repo contents should appear as follows:
- Clone the repository:

-
- Create the main branch and push to the remote repository
git checkout -b main git add ./ git commit -m "Initial Commit" git push -u origin main - Application CodeCommit repository: Take the value of the Output for the key oAppCodeCommitHttpsGrcRepoUrl from datalake-infra-resources CloudFormation Stack Outputs section which looks like below:
- Create the main branch and push to the remote repository

-
- Clone the repository:
git clone codecommit::us-east-2://dev-AppCode
- Change the directory to dev-CommonLayerCode
cd dev-AppCode
- Add contents to the cloned repository from the source code downloaded in Step 1. Copy the code from the ApplicationCode directory and the repo contents should appear as follows from the root:
- Clone the repository:

- Create the main branch and push to the remote repository
git checkout -b main git add ./ git commit -m "Initial Commit" git push -u origin main
-
What happens now?
- Now the Common Layer CodePipeline goes to the InProgress state and invokes the Common Layer CodeBuild project that builds the docker image and pushes it to the Common Layer Amazon ECR repository. The image tag utilized for the container image is the value resolved for the environment variable available in the AWS CodeBuild project CODEBUILD_RESOLVED_SOURCE_VERSION. This is the CodeCommit git Commit Id in this case.
For example, if the CommitId in CodeCommit isf1769c87, then the pushed docker image will have this tag along withlatest - buildspec.yaml files appears as follows:
version: 0.2 phases: install: runtime-versions: docker: 19 pre_build: commands: - echo Logging in to Amazon ECR... - aws --version - $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) - REPOSITORY_URI=$ECR_COMMON_DATALAKE_REPO_URL - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) - IMAGE_TAG=${COMMIT_HASH:=latest} build: commands: - echo Build started on `date` - echo Building the Docker image... - docker build -t $REPOSITORY_URI:latest . - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$IMAGE_TAG post_build: commands: - echo Build completed on `date` - echo Pushing the Docker images... - docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - Now the microservices architecture CodePipeline goes to the InProgress state and invokes all of the application image builder CodeBuild project that builds the docker images and pushes them to the Amazon ECR repository.
- To improve the performance, every docker image is built in parallel within the codebuild project. The buildspec.yaml executes the build.sh script. This has the logic to build docker images required for each Lambda Function part of the microservices architecture. The docker images used for this sample architecture took approximately 4 to 5 minutes when the docker images were built serially. After switching to parallel building, it took approximately 40 to 50 seconds.
- buildspec.yaml files appear as follows:
version: 0.2 phases: install: runtime-versions: docker: 19 commands: - uname -a - set -e - chmod +x ./build.sh - ./build.sh artifacts: files: - cfn/**/* name: builds/$CODEBUILD_BUILD_NUMBER/cfn-artifacts - build.sh file appears as follows:
#!/bin/bash set -eu set -o pipefail RESOURCE_PREFIX="${RESOURCE_PREFIX:=stg}" AWS_DEFAULT_REGION="${AWS_DEFAULT_REGION:=us-east-1}" ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text 2>&1) ECR_COMMON_DATALAKE_REPO_URL="${ECR_COMMON_DATALAKE_REPO_URL:=$ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com\/$RESOURCE_PREFIX-common-datalake-library}" pids=() pids1=() PROFILE='new-profile' aws configure --profile $PROFILE set credential_source EcsContainer aws --version $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) BUILD_TAG=build-$(echo $CODEBUILD_BUILD_ID | awk -F":" '{print $2}') IMAGE_TAG=${BUILD_TAG:=COMMIT_HASH:=latest} cd dockerfiles; mkdir ../logs function pwait() { while [ $(jobs -p | wc -l) -ge $1 ]; do sleep 1 done } function build_dockerfiles() { if [ -d $1 ]; then directory=$1 cd $directory echo $directory echo "---------------------------------------------------------------------------------" echo "Start creating docker image for $directory..." echo "---------------------------------------------------------------------------------" REPOSITORY_URI=$ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$RESOURCE_PREFIX-$directory docker build --build-arg ECR_COMMON_DATALAKE_REPO_URL=$ECR_COMMON_DATALAKE_REPO_URL . -t $REPOSITORY_URI:latest -t $REPOSITORY_URI:$IMAGE_TAG -t $REPOSITORY_URI:$COMMIT_HASH echo Build completed on `date` echo Pushing the Docker images... docker push $REPOSITORY_URI cd ../ echo "---------------------------------------------------------------------------------" echo "End creating docker image for $directory..." echo "---------------------------------------------------------------------------------" fi } for directory in *; do echo "------Started processing code in $directory directory-----" build_dockerfiles $directory 2>&1 1>../logs/$directory-logs.log | tee -a ../logs/$directory-logs.log & pids+=($!) pwait 20 done for pid in "${pids[@]}"; do wait "$pid" done cd ../cfn/ function build_cfnpackages() { if [ -d ${directory} ]; then directory=$1 cd $directory echo $directory echo "---------------------------------------------------------------------------------" echo "Start packaging cloudformation package for $directory..." echo "---------------------------------------------------------------------------------" aws cloudformation package --profile $PROFILE --template-file template.yaml --s3-bucket $S3_BUCKET --output-template-file packaged-template.yaml echo "Replace the parameter 'pEcrImageTag' value with the latest built tag" echo $(jq --arg Image_Tag "$IMAGE_TAG" '.Parameters |= . + {"pEcrImageTag":$Image_Tag}' parameters.json) > parameters.json cat parameters.json ls -al cd ../ echo "---------------------------------------------------------------------------------" echo "End packaging cloudformation package for $directory..." echo "---------------------------------------------------------------------------------" fi } for directory in *; do echo "------Started processing code in $directory directory-----" build_cfnpackages $directory 2>&1 1>../logs/$directory-logs.log | tee -a ../logs/$directory-logs.log & pids1+=($!) pwait 20 done for pid in "${pids1[@]}"; do wait "$pid" done cd ../logs/ ls -al for f in *; do printf '%s\n' "$f" paste /dev/null - < "$f" done cd ../
The function build_dockerfiles() loops through each directory within the dockerfiles directory and runs the docker build command in order to build the docker image. The name for the docker image and then the ECR repository is determined by the directory name in which the DockerFile is used from. For example, if the DockerFile directory is routing-lambda and the environment variables take the below values,
ACCOUNT_ID=0123456789
AWS_DEFAULT_REGION=us-east-2
RESOURCE_PREFIX=dev
directory=routing-lambda
REPOSITORY_URI=$ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$RESOURCE_PREFIX-$directoryThen REPOSITORY_URI becomes 0123456789.dkr.ecr.us-east-2.amazonaws.com/dev-routing-lambda
And the docker image is pushed to this resolved REPOSITORY_URI. Similarly, docker images for all other directories are built and pushed to Amazon ECR.
Important Note: The ECR repository names match the directory names where the DockerFiles exist and was already created as part of the CloudFormation template codepipeline.yaml that was deployed in step 3. In order to add more Lambda Functions to the microservices architecture, make sure that the ECR repository name added to the new repository in the codepipeline.yaml template matches the directory name within the AppCode repository dockerfiles directory.
Every docker image is built in parallel in order to save time. Each runs as a separate operating system process and is pushed to the Amazon ECR repository. This also controls the number of processes that could run in parallel by setting a value for the variable pwait within the loop. For example, if pwait 20, then the maximum number of parallel processes is 20 at a given time. The image tag for all docker images used for Lambda Functions is constructed via the CodeBuild BuildId, which is available via environment variable $CODEBUILD_BUILD_ID, in order to ensure that a new image gets a new tag. This is required for CloudFormation to detect changes and update Lambda Functions with the new container image tag.
Once every docker image is built and pushed to Amazon ECR in the CodeBuild project, it builds every CloudFormation package by uploading all local artifacts to Amazon S3 via AWS Cloudformation package CLI command for the templates available in its own directory within the cfn directory. Moreover, it updates every parameters.json file for each directory with the ECR image tag to the parameter value pEcrImageTag. This is required for CloudFormation to detect changes and update the Lambda Function with the new image tag.
After this, the CodeBuild project will output the packaged CloudFormation templates and parameters files as an artifact to AWS CodePipeline so that it can be deployed via AWS CloudFormation in further stages. This is done by first creating a ChangeSet and then deploying it at the next stage.
Testing the microservices architecture
As stated above, the sample application utilized for microservices architecture involving multiple Lambda Functions is a modified version of the Serverless Data Lake Framework. The microservices architecture CodePipeline deployed every AWS resource required to run the SDLF application via AWS CloudFormation stages. As part of SDLF, it also deployed a set of DynamoDB tables required for the applications to run. I utilized the meteorites sample for this, thereby the DynamoDb tables should be added with the necessary data for the application to run for this sample.
Utilize the AWS console to write data to the AWS DynamoDb Table. For more information, refer to this documentation. The sample json files are in the utils/DynamoDbConfig/ directory.
1. Add the record below to the octagon-Pipelines-dev DynamoDB table:
{
"description": "Main Pipeline to Ingest Data",
"ingestion_frequency": "WEEKLY",
"last_execution_date": "2020-03-11",
"last_execution_duration_in_seconds": 4.761,
"last_execution_id": "5445249c-a097-447a-a957-f54f446adfd2",
"last_execution_status": "COMPLETED",
"last_execution_timestamp": "2020-03-11T02:34:23.683Z",
"last_updated_timestamp": "2020-03-11T02:34:23.683Z",
"modules": [
{
"name": "pandas",
"version": "0.24.2"
},
{
"name": "Python",
"version": "3.7"
}
],
"name": "engineering-main-pre-stage",
"owner": "Yuri Gagarin",
"owner_contact": "y.gagarin@",
"status": "ACTIVE",
"tags": [
{
"key": "org",
"value": "VOSTOK"
}
],
"type": "INGESTION",
"version": 127
}2. Add the record below to the octagon-Pipelines-dev DynamoDB table:
{
"description": "Main Pipeline to Merge Data",
"ingestion_frequency": "WEEKLY",
"last_execution_date": "2020-03-11",
"last_execution_duration_in_seconds": 570.559,
"last_execution_id": "0bb30d20-ace8-4cb2-a9aa-694ad018694f",
"last_execution_status": "COMPLETED",
"last_execution_timestamp": "2020-03-11T02:44:36.069Z",
"last_updated_timestamp": "2020-03-11T02:44:36.069Z",
"modules": [
{
"name": "PySpark",
"version": "1.0"
}
],
"name": "engineering-main-post-stage",
"owner": "Neil Armstrong",
"owner_contact": "n.armstrong@",
"status": "ACTIVE",
"tags": [
{
"key": "org",
"value": "NASA"
}
],
"type": "TRANSFORM",
"version": 4
}3. Add the record below to the octagon-Datsets-dev DynamoDB table:
{
"classification": "Orange",
"description": "Meteorites Name, Location and Classification",
"frequency": "DAILY",
"max_items_process": 250,
"min_items_process": 1,
"name": "engineering-meteorites",
"owner": "NASA",
"owner_contact": "nasa@edu.org",
"pipeline": "main",
"tags": [
{
"key": "cost",
"value": "meteorites division"
}
],
"transforms": {
"stage_a_transform": "light_transform_blueprint",
"stage_b_transform": "heavy_transform_blueprint"
},
"type": "TRANSACTIONAL",
"version": 1
}
If you want to create these samples using AWS CLI, please refer to this documentation.
Record 1:
aws dynamodb put-item --table-name octagon-Pipelines-dev --item '{"description":{"S":"Main Pipeline to Merge Data"},"ingestion_frequency":{"S":"WEEKLY"},"last_execution_date":{"S":"2021-03-16"},"last_execution_duration_in_seconds":{"N":"930.097"},"last_execution_id":{"S":"e23b7dae-8e83-4982-9f97-5784a9831a14"},"last_execution_status":{"S":"COMPLETED"},"last_execution_timestamp":{"S":"2021-03-16T04:31:16.968Z"},"last_updated_timestamp":{"S":"2021-03-16T04:31:16.968Z"},"modules":{"L":[{"M":{"name":{"S":"PySpark"},"version":{"S":"1.0"}}}]},"name":{"S":"engineering-main-post-stage"},"owner":{"S":"Neil Armstrong"},"owner_contact":{"S":"n.armstrong@"},"status":{"S":"ACTIVE"},"tags":{"L":[{"M":{"key":{"S":"org"},"value":{"S":"NASA"}}}]},"type":{"S":"TRANSFORM"},"version":{"N":"8"}}'Record 2:
aws dynamodb put-item --table-name octagon-Pipelines-dev --item '{"description":{"S":"Main Pipeline to Ingest Data"},"ingestion_frequency":{"S":"WEEKLY"},"last_execution_date":{"S":"2021-03-28"},"last_execution_duration_in_seconds":{"N":"1.75"},"last_execution_id":{"S":"7e0e04e7-b05e-41a6-8ced-829d47866a6a"},"last_execution_status":{"S":"COMPLETED"},"last_execution_timestamp":{"S":"2021-03-28T20:23:06.031Z"},"last_updated_timestamp":{"S":"2021-03-28T20:23:06.031Z"},"modules":{"L":[{"M":{"name":{"S":"pandas"},"version":{"S":"0.24.2"}}},{"M":{"name":{"S":"Python"},"version":{"S":"3.7"}}}]},"name":{"S":"engineering-main-pre-stage"},"owner":{"S":"Yuri Gagarin"},"owner_contact":{"S":"y.gagarin@"},"status":{"S":"ACTIVE"},"tags":{"L":[{"M":{"key":{"S":"org"},"value":{"S":"VOSTOK"}}}]},"type":{"S":"INGESTION"},"version":{"N":"238"}}'Record 3:
aws dynamodb put-item --table-name octagon-Pipelines-dev --item '{"description":{"S":"Main Pipeline to Ingest Data"},"ingestion_frequency":{"S":"WEEKLY"},"last_execution_date":{"S":"2021-03-28"},"last_execution_duration_in_seconds":{"N":"1.75"},"last_execution_id":{"S":"7e0e04e7-b05e-41a6-8ced-829d47866a6a"},"last_execution_status":{"S":"COMPLETED"},"last_execution_timestamp":{"S":"2021-03-28T20:23:06.031Z"},"last_updated_timestamp":{"S":"2021-03-28T20:23:06.031Z"},"modules":{"L":[{"M":{"name":{"S":"pandas"},"version":{"S":"0.24.2"}}},{"M":{"name":{"S":"Python"},"version":{"S":"3.7"}}}]},"name":{"S":"engineering-main-pre-stage"},"owner":{"S":"Yuri Gagarin"},"owner_contact":{"S":"y.gagarin@"},"status":{"S":"ACTIVE"},"tags":{"L":[{"M":{"key":{"S":"org"},"value":{"S":"VOSTOK"}}}]},"type":{"S":"INGESTION"},"version":{"N":"238"}}'Now upload the sample json files to the raw s3 bucket. The raw S3 bucket name can be obtained in the output of the common-cloudformation stack deployed as part of the microservices architecture CodePipeline. Navigate to the CloudFormation console in the region where the CodePipeline was deployed and locate the stack with the name common-cloudformation, navigate to the Outputs section, and then note the output bucket name with the key oCentralBucket. Navigate to the Amazon S3 Bucket console and locate the bucket for oCentralBucket, create two path directories named engineering/meteorites, and upload every sample json file to this directory. Meteorites sample json files are available in the utils/meteorites-test-json-files directory of the previously cloned repository. Wait a few minutes and then navigate to the stage bucket noted from the common-cloudformation stack output name oStageBucket. You can see json files converted into csv in pre-stage/engineering/meteorites folder in S3. Wait a few more minutes and then navigate to the post-stage/engineering/meteorites folder in the oStageBucket to see the csv files converted to parquet format.
Cleanup
Navigate to the AWS CloudFormation console, note the S3 bucket names from the common-cloudformation stack outputs, and empty the S3 buckets. Refer to Emptying the Bucket for more information.
Delete the CloudFormation stacks in the following order:
1. Common-Cloudformation
2. stagea
3. stageb
4. sdlf-engineering-meteorites
Then delete the infrastructure CloudFormation stack datalake-infra-resources deployed using the codepipeline.yaml template. Refer to the following documentation to delete CloudFormation Stacks: Deleting a stack on the AWS CloudFormation console or Deleting a stack using AWS CLI.
Conclusion
This method lets us use CI/CD via CodePipeline, CodeCommit, and CodeBuild, along with other AWS services, to automatically deploy container images to Lambda Functions that are part of the microservices architecture. Furthermore, we can build a common layer that is equivalent to the Lambda layer that could be built independently via its own CodePipeline, and then build the container image and push to Amazon ECR. Then, the common layer container image Amazon ECR functions as a source along with its own CodeCommit repository which holds the code for the microservices architecture CodePipeline. Having two sources for microservices architecture codepipeline lets us build every docker image. This is due to a change made to the common layer docker image that is referred to in other docker images, and another source that holds the code for other microservices including Lambda Function.
About the Author
 |
Kirankumar Chandrashekar is a Sr.DevOps consultant at AWS Professional Services. He focuses on leading customers in architecting DevOps technologies. Kirankumar is passionate about DevOps, Infrastructure as Code, and solving complex customer issues. He enjoys music, as well as cooking and traveling. |