AWS Database Blog
Scale your Amazon MemoryDB for Redis clusters at a lower cost with data tiering
Amazon MemoryDB for Redis is a Redis-compatible database service that delivers both in-memory performance and Multi-AZ durability. You can use MemoryDB as a primary database for use cases that require durable storage and ultra-fast performance, like user session data, message streaming between microservices, payment processing, gaming leaderboards, and Internet of Things (IoT).
Today, we announced the availability of data tiering for the AWS Graviton2-based R6gd node types in MemoryDB. When using R6gd nodes, MemoryDB automatically and transparently tiers data between DRAM and locally attached NVMe solid state drives (SSDs). SSDs provide slightly higher latencies for Redis workloads than memory, but also cost significantly less. When using clusters with data tiering, with the R6gd nodes have nearly 5x more total capacity (memory + SSD) and can help you achieve over 60% storage cost savings when running at maximum utilization compared to R6g nodes (memory only) while having minimal performance impact on applications.
Assuming 500-byte String values, you can typically expect an additional 450µs latency for read requests to data stored on SSD compared to read requests to data in memory.
With the largest data tiering node size (db.r6gd.8xlarge), you can now store up to 500 TB in a single 500 node cluster (250 TB when using one read replica). Data tiering is compatible with all Redis commands and data structures supported in MemoryDB. You don’t need any client-side changes to use this feature.
In this post, we describe how to use R6gd instances with data tiering in MemoryDB to scale capacity in a cost-optimal way.
How data tiering works
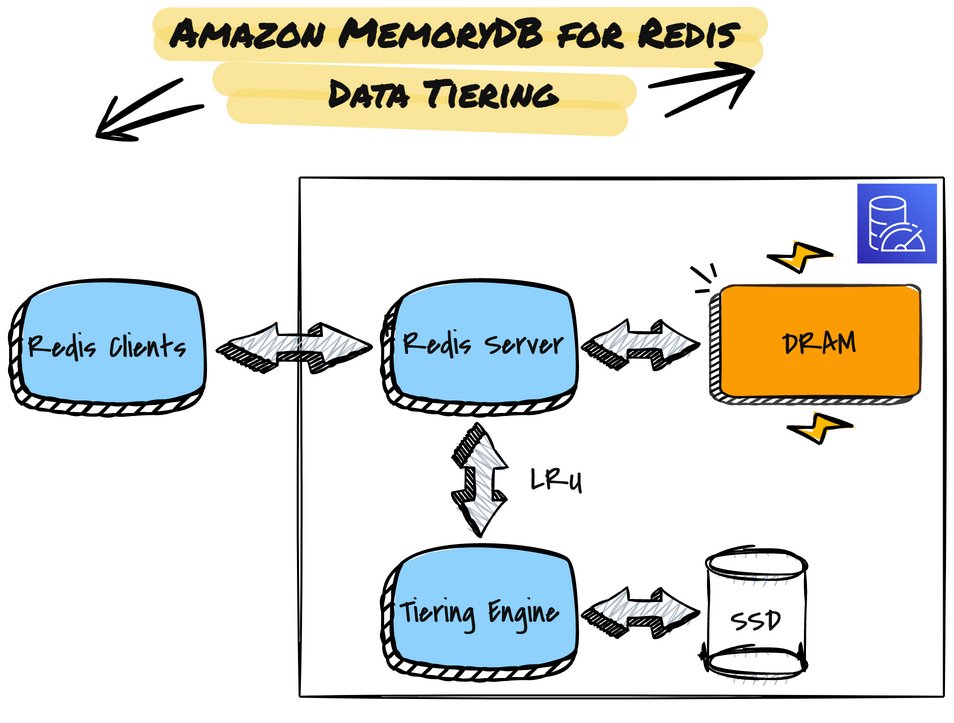
On a cluster with data tiering, MemoryDB monitors the last access time of every item it stores. When available memory (DRAM) is consumed, MemoryDB uses a least-recently used (LRU) algorithm to automatically move infrequently accessed items from memory to SSD. When data on SSD is subsequently accessed, MemoryDB automatically and asynchronously moves it back to memory before processing the request. If you have a workload that accesses only a subset of its data regularly, data tiering is a good option to scale your capacity cost-effectively, often times with no perceivable performance impact to applications.
MemoryDB stores data on NVMe SSDs using a purpose-built tiering engine, which is fine-tuned for high throughput and low latency. Security and data integrity were key areas of focus in the design of the tiering engine. Like all Graviton2-based hardware, MemoryDB R6gd nodes offer always-on 256-bit encrypted DRAM. Additionally, all items stored on NVMe SSDs are encrypted by default (even for clusters that didn’t configure encryption of data at rest) using an XTS-AES-256 block cipher implemented in a hardware module on the node. We perform data integrity validation using a crc32c checksum on each item read from NVMe SSDs.
The following diagram illustrates the high-level architecture of a MemoryDB node with data tiering.
Get started with data tiering
To start using data tiering, complete the following steps:
- On the MemoryDB console, choose Clusters in the navigation pane.
- Choose Create cluster.
This opens the cluster creation workflow. - For Redis version compatibility, choose the 6.2 engine.
- Choose a node type in the r6gd family (data tiering isn’t supported on older engine versions or other node families).
- Choose Save.


- Enter the remaining required cluster configuration parameters, such as name and subnet group, and choose Create.
After a few minutes, your cluster’s status changes to Available. You can then connect to the cluster using the Redis command line interface or any Redis client. To migrate data from an existing MemoryDB cluster, you can restore a backup into your new R6gd cluster.
Performance analysis
MemoryDB data tiering is designed to have minimal performance impact on applications that access a small portion of their data regularly. Data tiering is ideal for large workloads that access up to 20% of their data regularly and for applications that can tolerate additional latency when data on the SSD tier is accessed. For these workloads, the working set (the set of data being accessed regularly) is served fully in memory, with the remainder of the dataset served from SSD.
To measure performance, we used redis-benchmark to generate load. We tested against a single node db.r6gd.2xlarge cluster with encryption in transit enabled. We used five Amazon Elastic Compute Cloud (Amazon EC2) instances in the same Availability Zone to generate the load. The test setup used 250 million unique keys, 16-byte key length, 500-byte string values, and 100 client connections without command pipelining.
Out of the 100 client connections, 90 clients generated requests to a smaller range of the keys which are considered as hot data set, and the other 10 client generated requests to the entire key range so that about 10% of the requests were issued against items stored on NVMe SSD. We ran the benchmark continuously over multiple days.
We constructed our test this way to provide a representative sample of how MemoryDB performs with data tiering active and when infrequently accessed items are needed again. The following table summarizes our findings.
| Workload Type | Throughput (requests per second) | Latency Average (milliseconds) | Latency p50 (milliseconds) | Latency p90 (milliseconds) | Latency p95 (milliseconds) | Latency p99 (milliseconds) |
| Write only | 28,500 | 3.7 | 3.3 | 4.1 | 5.5 | 7.5 |
| Read only | 180,000 | 0.7 | 0.65 | 1.1 | 1.7 | 3.5 |
| Mixed (80% read, 20% write) | 140,000 | 1.6 | 1.3 | 2.4 | 3.6 | 6.2 |
We also tested when 20% of the requests were issued against items stored on NVMe SSD by increasing the key range for the hot data set. The result is as follows.
| Workload Type | Throughput (requests per second) | Latency Average (milliseconds) | Latency p50 (milliseconds) | Latency p90 (milliseconds) | Latency p95 (milliseconds) | Latency p99 (milliseconds) |
| Write only | 25,000 | 4.1 | 3.5 | 6.5 | 9.1 | 12.2 |
| Read only | 101,500 | 1.3 | 0.65 | 4 | 5.9 | 7 |
| Mixed (80% read, 20% write) | 85,000 | 2 | 1.3 | 4.6 | 6.3 | 8.8 |
Based on our results, we can see that MemoryDB data tiering nodes have minimal performance impact on applications that access a small portion of their data regularly.
Monitor clusters with data tiering using Amazon CloudWatch
With this launch, we’ve updated the Amazon CloudWatch metrics available for MemoryDB to reflect SSD usage on clusters with data tiering. Specifically, we’ve added four new metrics and additional metric dimensions for two of our preexisting metrics.
The new metrics come in two pairs: BytesReadFromDisk and BytesWrittenToDisk, which indicate how much data is being read from and written to the SSD tier, and NumItemsReadFromDisk and NumItemsWrittenToDisk, which indicate the volume of Redis items being read from and written to the SSD tier.
In addition to these four new metrics, we introduced the Tier metric dimension on the metrics CurrItems and BytesUsedForMemoryDB. Tier can have two values: Memory and SSD. For example, when you query the CurrItems metric, if you don’t specify any Tier, you retrieve the total number of items in your cluster, just as before. If you specify Tier=Memory or Tier=SSD, you see the total broken down by how many items are in memory vs. SSD, respectively. Note that these new metrics and metric dimensions are only available for clusters with data tiering.
Here’s a practical example of how to put the new metrics to use. Let’s say you’re observing high client-side latency—you could inspect NumItemsReadFromDisk. If its value is high (perhaps, relative to GetTypeCmds + SetTypeCmds, using CloudWatch metric math), this could indicate that the SSD is being more frequently accessed relative to memory than is ideal for data tiering. You could scale up to a larger r6gd node type or scale out by adding shards so that more RAM is available to serve your active dataset.
Conclusion
In this post, we showed how data tiering for MemoryDB provides a convenient way to scale your clusters at a lower cost to up to 500TB of data. It can provide over 60% storage cost savings while having minimal performance impact for workloads that access a subset of their data regularly.
The R6gd node type with data tiering for MemoryDB is available today in the US East (Ohio), US East (N. Virginia), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (Paris), and South America (Sao Paulo) Regions. For pricing, see Amazon MemoryDB pricing.
We’re excited to enable you to use data tiering for MemoryDB to scale your clusters at a lower cost. We’d love to hear your feedback and questions about data tiering, so please reach out to us at memorydb-help@amazon.com or in the comments.
About the authors
 Roberto Luna Rojas is an AWS In-Memory DB Specialist Solutions Architect based in NY. He works with customers from around the globe to make the best out of In-Memory Databases one bit at the time. When not in front of the computer he loves to spend time with his family, listening to music, watching movies, tv shows, and sports.
Roberto Luna Rojas is an AWS In-Memory DB Specialist Solutions Architect based in NY. He works with customers from around the globe to make the best out of In-Memory Databases one bit at the time. When not in front of the computer he loves to spend time with his family, listening to music, watching movies, tv shows, and sports.
 Karthik Konaparthi is a Senior Product Manager on the Amazon In-Memory Databases team and is based in Seattle, WA. He is passionate about all things data and spends his time working with customers to understand their requirements and building exceptional products. In his spare time, he enjoys traveling to new places and spending time with his family.
Karthik Konaparthi is a Senior Product Manager on the Amazon In-Memory Databases team and is based in Seattle, WA. He is passionate about all things data and spends his time working with customers to understand their requirements and building exceptional products. In his spare time, he enjoys traveling to new places and spending time with his family.
 Qu Chen is a senior software development engineer at Amazon ElastiCache and MemoryDB – the team responsible for building, operating and maintaining the highly scalable and performant Redis managed service at AWS. In addition, he is an active contributor to the open-source Redis project. In his spare time, he enjoys sports, outdoor activities and playing piano music.
Qu Chen is a senior software development engineer at Amazon ElastiCache and MemoryDB – the team responsible for building, operating and maintaining the highly scalable and performant Redis managed service at AWS. In addition, he is an active contributor to the open-source Redis project. In his spare time, he enjoys sports, outdoor activities and playing piano music.