AWS Database Blog
Reducing Aurora PostgreSQL storage I/O costs
| June 2023: For Aurora databases where IO is greater than 25% of your costs, check out this blog post and recent announcement to see if you can save money with Aurora I/O-Optimized. |
Cost reduction is one of the biggest drivers for many IT departments to explore migration of on-premises workloads to the cloud. This post shares experiences in cost management, with a focus on Amazon Aurora PostgreSQL tuning.
History
I recently had the privilege of leading the implementation of our Auto Telematics Application in AWS. To provide some context, the Telematics application receives streaming driving data from our data providers. The data is validated, cleansed, and normalized. It is further transformed into trips, and a proprietary scoring algorithm is applied to calculate driver score. This project had the following key objectives:
- Highly available (HA) (five nines).
- Highly performant: response time should be in single-digit milliseconds.
- Reduce TCO to a fraction of the current TCO. This includes both human and machine resources.
- Pay-as-you-go model; charges mirror actual usage.
- Easy deployment and onboarding of new customers across the globe.
- Scalable and elastic, with ability to meet volume growth and demand fluctuations.
To achieve cost and HA targets, the application was rearchitected and rewritten from the ground up with a serverless/managed services architecture, to achieve minimal resource maintenance and the pay-as-you-go objective. It was a highly successful implementation, meeting all the targets except for cost. Costs were lower than on-premises, but were initially three times the estimated cost.
Overview
Like any other transformation, moving from on-premises to AWS includes the same three elements:
- People
- Process
- Technology
In my opinion, the People part is the key element. Unlike on-premises environments, infrastructure cost in AWS is not a sunk cost. The AWS operational cost varies based upon service usage. This includes not just the service runtime/elapsed time, but also the use of resources like memory, storage, I/O, etc., which varies from service to service. It can take a little while to internalize the pricing methodology in AWS. The change of work habits and automation of services is important to exploit the benefits of the AWS environment.
AWS cost reductions efforts can be grouped into the following steps:
- Understand AWS costs: To begin with, get comfortable with the billing dashboard. Understand how each service is contributing to your AWS costs. To prioritize tuning tasks, start with the top three contributors, but eventually reviewing all of them is not only important from a cost perspective, but also for finding security loopholes.
- Housekeeping: Going the serverless/managed services route does not mean you can throw away the best practices you followed on-premises for housekeeping and application maintenance. If anything, you should be enforcing them more rigorously.
- Identify application and service inefficiencies and tune.
Deep dive
In my case, the top three cost contributors and the percentage of the cost they represented were:
- Aurora PostgreSQL database: 75%
- Amazon CloudWatch Logs: 5%
- Amazon Kinesis: 5%
The three primary cost components of the Aurora PostgreSQL database and the percentage of the cost they represented were:
- Database I/O: 65%
- Instance size: 30%
- Storage: 5%
I/O
For a heavy transactional application, I/O costs are typically the largest contributor to the database cost.
Performance Insights and CloudWatch metrics provide clues to debug and isolate the issues. If you do not have Performance Insights enabled, make sure to enable it, as shown in the following screenshot.

Some of the following tips may aid in your tuning efforts:
- Check the metrics from Performance Insights. High IO: DataFileRead indicates high IO, as seen in the following screenshot. High IO:DataFilePrefetch indicates sequential scans are happening.

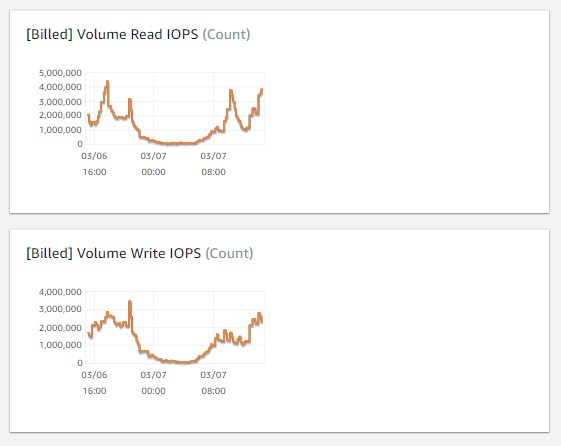
- Look at the CloudWatch metrics for Billed IOPS. Also, compare the Billed IOPS with the expected workload. This requires an understanding of the application. For example, based upon the amount of data ingestion, transformations, and query workload, database I/O is an order of magnitude higher than the estimated numbers. Note that the Billed metrics for Aurora are mislabeled. The metric shows the number of I/O operations per 5-minute interval, so for any value you see on the graph, you must divide by 300 (seconds in five minutes) to determine how many I/Os per second were executed in that 5-minute interval.
- Buffer cache hit ratio is one of the factors that can contribute to high I/O. Check the CloudWatch metrics for Buffer Cache Hit Ratio. It should be close to 99%. Lower buffer cache ratio results in more I/O.

- You can improve the buffer cache ratio by increasing the amount of memory allocated to
shared_buffers, but total memory available depends upon the database instance size. Increasing the instance size increases memory available forshared_buffers, but also increases the cost of the service, because instance size is one of the cost factors. You must find the right balance to get the cost benefit. So before increasing the instance size, we decided to take a closer look at our workload/ queries. - The SQL tab shows the impact of each SQL on IO. Start with the top three queries. If the queries are truncated in the display, then you must increase the value of the database parameter
track_activity_query_sizeto 4096 or higher depending upon the size of your queries. This requires an instance restart. - Next, run an
EXPLAINplan on these queries. If you use theANALYZEoption,EXPLAINexecutes the query and displays the true row counts and runtime. You can further enrich the runtime statistics by adding theBUFFERSoption, which provides information about the I/O impact of the query:
Check the EXPLAIN plan to ensure proper use of indexes and partitions.
- Partition pruning does not work if you use a function on a partitioning column. This can have a significant impact on your I/O and instance sizing needs. The best option is to design tables appropriately, so you do not have to use functions on a partitioned column. However, you may have already implemented partitioning on a function-based column, and it is not feasible to fix that easily in a production environment. As a workaround you can achieve the same results by changing the application logic to pick the appropriate partitions. For example:
For the test_table the partitioning column is dated, but the table data was partitioned by month. If the start_date is in January, the data would exist in partition test_table_01. February data exists in partition test_table_02, and so on. The ideal solution would be to create a month column in the table and then use that as the partitioning key. But due to environment constraints, it’s not possible to change the table design easily, so I implement a work-around: calculate the partition month before executing the query and select from the appropriate partition based upon the month in the start_date field.
- If the
QUERY EXPLAINplan is not indicating use of proper indexes, then create them. It is equally important to drop unused indexes, as redundant indexes result in unnecessary index maintenance cost and storage. Review all the indexes. The query below could be a starting point. Before dropping it in production, make sure to test it thoroughly.
- Evaluate tables that do not need to be created in the database. Common use cases could be logging tables, status tables, or any other tables that are not updated or frequently accessed at the record level. These are good candidates for storing in Amazon S3 instead of in the database, which saves expensive database I/O and storage. When deciding to persist these tables in S3, consider converting them to Parquet before writing. Amazon Kinesis Data Firehose provides an inexpensive and straightforward way to meet this need. Also, remember to partition them appropriately and catalog using AWS Glue, so you can work with the data like database tables.
I/O tuning reduces my monthly bill by more than 50%.
Database instance size:
Database instance size accounts for a considerable percentage of the cost.
- After you tune your workload and understand the load variations, buy Reserved Instances. AWS allows flexibility in applying Reserved Instances within the same instance family. For example, if you are not sure whether you need r5.large or r5.xlarge, start with your minimum needs and buy Reserved Instances for r5.large, and if you need to, increase r5.large to r5.xlarge. Reserved Instances partially cover r5.xlarge, and the rest have the On-Demand price. You can always buy more Reserved Instances to cover the gap.
- As discussed earlier, test to check if increasing instance size reduces I/O cost. Also consider that instance costs can be reduced by buying Reserved Instances, whereas there is no Reserved Instance concept for I/O.
- Do you really need the same database configuration and availability in production and non-production accounts? You can easily cut costs by reducing the instance size in non-production accounts. In addition, non-production accounts may not need to be Multi-AZ enabled.
Database storage
Storage accounts for the remaining 5% of the cost.
UPDATE [22 Oct 2020] – Starting in Aurora MySQL 2.09.0 and 1.23.0, and Aurora PostgreSQL 10.13 and 11.8, when Aurora data is removed (e.g., dropping a table or database), the overall allocated space decreases by a comparable amount. Thus, you can reduce storage charges by deleting tables, indexes, or databases that you no longer need. See the “What’s New Blog” and documentation for more details.
- In Aurora PostgreSQL, storage cost is based upon the storage high-water mark. Even after you purge data from the database, your storage cost will not go down. So, the best practice is to regularly archive older partitions, move data out to S3, and truncate partitions. It also helps with I/O as it reduces index size.
- Be careful during data migration, as temporary data storage can increase the high-water mark, so cleaning up data regularly is a good practice.
- Manage backup storage. There is no additional charge for backup of up to 100% of your total Aurora database storage for each Aurora DB cluster. Regularly purge additional manual backups, which are not needed.
Additional costs
Other common services that can cause costs to add up quickly are:
- CloudWatch logging: Following is an example of logging for API Gateway.
- In development mode, the log level is typically set at
INFO. Remember to change it back toERROR, as seen in the following screenshot. - Also, remember to uncheck the Log full requests/responses data
- In development mode, the log level is typically set at

- Kinesis stream: For the most part, this is priced on usage, except shards are provisioned, so it results in a fixed cost whether they are used or not. Consider reducing the number of Kinesis shards in non-production environments.
- S3: To keep costs for S3 down:
- Drop all temporary/redundant objects.
- Set lifecycle polices so data can be purged or moved to lower-cost storage.
- Amazon EC2: To keep costs for EC2 down:
- Drop any redundant EC2 instances.
- Size the EC2 instances appropriately.
- Drop or consolidate and stagger batch and utility jobs to fully use the EC2 instance.
- Buy Reserved Instances for the base capacity.
- Remove any unused EBS volumes.
- AWS CloudTrail: CloudTrail costs can add up quickly, especially if you have a serverless architecture executing millions of Lambda functions.
- One trail is free. If you have multiple trails, consider if you need them.
Conclusion
To summarize:
- Understand your environment
- Ask questions
- Investigate
If a service exists, ensure that you can justify the need for its duration and the resources it is using. I followed the above steps, and within a matter of weeks, I reduced costs to below the initial estimates.
If you have any questions, feel free to leave a comment.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Author
 Sundeep Sardana is the Vice President / Chief Architect of the IoT division at Verisk. Sundeep led the re-architecture of the Telematics on-premises application to a cloud native serverless application and implemented in AWS. Prior to joining Verisk, Sundeep spent 10 years with HBO as a Director of Data Integration department responsible for developing applications handling high volume and velocity of data. Sundeep is a change maker, AWS evangelist, and specializes in helping organizations in their journey to cloud. He holds a Bachelor of Mechanical Engineering. Sundeep lives and works in the NYC area.
Sundeep Sardana is the Vice President / Chief Architect of the IoT division at Verisk. Sundeep led the re-architecture of the Telematics on-premises application to a cloud native serverless application and implemented in AWS. Prior to joining Verisk, Sundeep spent 10 years with HBO as a Director of Data Integration department responsible for developing applications handling high volume and velocity of data. Sundeep is a change maker, AWS evangelist, and specializes in helping organizations in their journey to cloud. He holds a Bachelor of Mechanical Engineering. Sundeep lives and works in the NYC area.