AWS Database Blog
Category: Advanced (300)

Reduce read I/O cost of your Amazon Aurora PostgreSQL database with range partitioning
June 2023: For Aurora databases where IO is greater than 25% of your costs, check out this blog post and recent announcement to see if you can save money with Aurora I/O-Optimized. Amazon Aurora PostgreSQL-Compatible Edition offers a SQL database with enterprise-grade speed, availability, and scale at a cost comparable to open-source databases. With Aurora, […]

Archive data from Amazon DynamoDB to Amazon S3 using TTL and Amazon Kinesis integration
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we share how you can use Amazon Kinesis integration and the Amazon DynamoDB Time to Live (TTL) feature to design data archiving. Archiving old […]

Model-driven graphs using OWL in Amazon Neptune
Amazon Neptune is a graph database service provided by AWS that you can use to build a knowledge graph of relationships among business objects. When building a knowledge graph, what is a suitable model to govern the representation of those relationships? We would prefer not to build our graph on the fly, but rather have […]

Create an Amazon CloudWatch dashboard to monitor Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL
Database performance monitoring is critical for application availability and productivity. A good monitoring practice can ensure a small issue is identified in time before it develops into a big problem and causes service disruption. In the AWS Cloud, you can use analytical and monitoring tools like Amazon RDS Performance Insights and Amazon CloudWatch metrics and […]
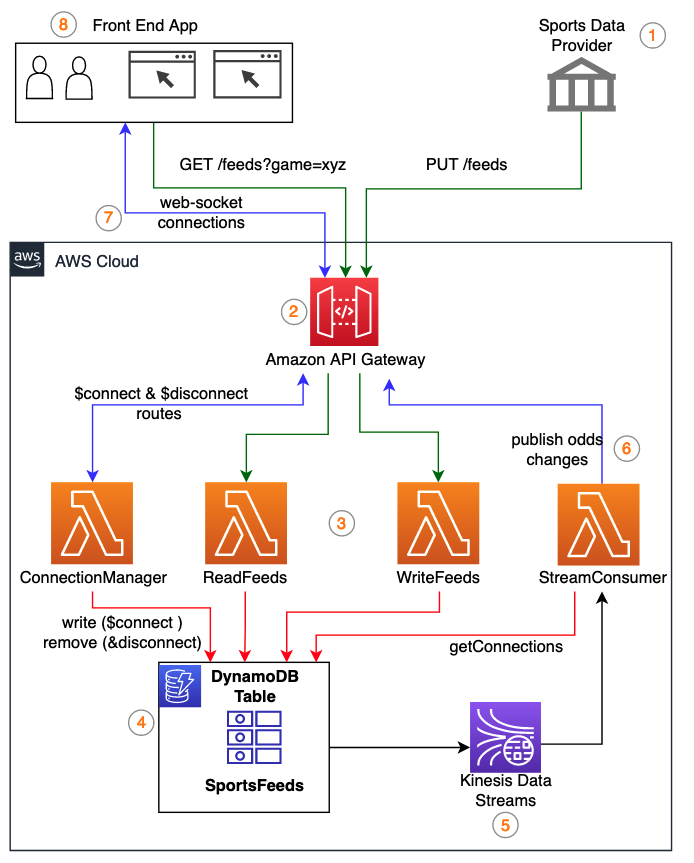
Store and stream sports data feeds using Amazon DynamoDB and Amazon Kinesis Data Streams
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Online bookmakers are innovating to offer their clients continuously updated sports data feeds that allow betting throughout the duration of matches. In this post, we walk through […]
Backup and Restore Strategies for Amazon RDS for SQL Server
Customers have asked for the right solution to safeguard their data on Amazon Relational Database Service (Amazon RDS) for SQL Server and meet their current Recovery Point Objective (RPO), the maximum acceptable amount of time since the last backup and Recovery Time Objective (RTO), the maximum acceptable delay between the interruption of service and restoration […]

Build faster with Amazon DynamoDB and PartiQL: SQL-compatible operations
In November 2020, we launched DynamoDB support for PartiQL. With PartiQL, you can codify your DynamoDB data operations using familiar SQL syntax and get the fast, consistent performance that DynamoDB customers have long depended on. In this post, we explain how DynamoDB’s PartiQL support helps new DynamoDB developers learn faster and provides existing DynamoDB developers […]

Vehicle routing optimization with Amazon Aurora PostgreSQL-Compatible Edition
Vehicle route planning with the goals of meeting customer satisfaction expectations, reducing fuel consumption, and reducing emissions can be challenging. The vehicle routing problem (VRP) goal is to find optimal routes for multiple vehicles visiting multiple locations to fulfill business-specific constraints such as cost and time. The VRP has various use cases in industries such […]

Cross-Region, cross-account disaster recovery using Amazon Aurora Global Database
Critical workloads with a global footprint have strict availability requirements and may need to tolerate a Region-wide outage. Traditionally, this required a difficult trade-off between performance, availability, cost, and data integrity, and sometimes required a considerable re-engineering effort. Due to the high implementation and infrastructure costs that are involved, some businesses are compelled to tier […]

Tune sorting operations in PostgreSQL with work_mem
Sorting is one of the most fundamental operations in databases, and optimizing this process is vital to the performance of applications. Sorting involves arranging records in a database table into some meaningful order to make it easier to understand, analyze, and visualize the data. For example, you might want to sort orders by their delivery […]