Containers
The role of AWS Fargate in the container world
In 2017, we introduced a serverless service to run containers at scale called AWS Fargate. Today, customers are launching tens of millions of containers on it every week. Customers keep telling us that the reason they love Fargate is because it removes a lot of the infrastructure undifferentiated heavy lifting. For example, they no longer need to be responsible for sizing, scaling, patching, and updating their EC2 fleet or container runtime.
What we have also noticed in these past two years is that Fargate was such a novel idea that some of the same customers found and still find it difficult to box it in a particular layer of the larger AWS container portfolio. We are obsessed about building useful services that solve real problems for our customers. However, we also believe that it is important to be able to describe and position these services in a way that makes it easy for our customers and partners to understand the trajectory we are on and what we are trying to build for the long term.
We will not go deep into the Fargate architecture in this blog post. Rather, we will spend more time drawing the big picture with a focus on the difference between the Fargate “product” and the Fargate “technology” and how it fits into the larger container ecosystem. We intend to clarify some of the key aspects about AWS Fargate and particularly how this product relates to other container services such as Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS).
Where are we coming from?
There is no way we can understand where we are if we don’t have a clear picture of where we are coming from. This story goes even further back but when Docker was introduced back in 2013, it changed the way customers could leverage containers. At that time this was, for the most part, a “laptop play.” In other words, developers were using the technology on their laptops for increased personal productivity. While the technology would allow for a lot more, for the context of this blog post, we will focus on the ability to “docker run” a container on their personal computer.

As time went by, people started to realize the power of this technology and made it evolve from a “laptop play” (for personal test and development purposes) to a “cloud play” for running production applications. It also became clear that, in order to achieve that, there was a need for something that went beyond a mere “docker run” to manually start a single container on a laptop.
This is when the so called “container orchestrators” started to take shape. Amazon ECS was one of the first to emerge as an AWS managed cloud service in 2015. Kubernetes was the other technology that started to emerge as an OSS project around the same time.
What does a container orchestrator add compared to what Docker introduced in the early days? Container orchestrators have a couple of major roles:
- Container orchestrators introduced features and constructs that allowed customers to go beyond simply running a container. This includes, for example, automating the lifecycle of their containers, making sure they were associated with a higher order “service” or “deployment” and that containers could communicate inside and outside of a cluster using a specific networking model. At this time, the ECS tasks and the Kubernetes pods started to become the atomic unit of deployment.
- Container orchestrators also introduced features and constructs that allowed customers to decouple their services and deployments (see #1 above) from the capacity they would need to run containers (in the form of ECS tasks and Kubernetes pods). In other words, these orchestrators are responsible for scheduling tasks and pods, which represent a set of containers running together on a virtual machine. The orchestrators are also actively involved in (if not in charge of) managing the scaling of this capacity.
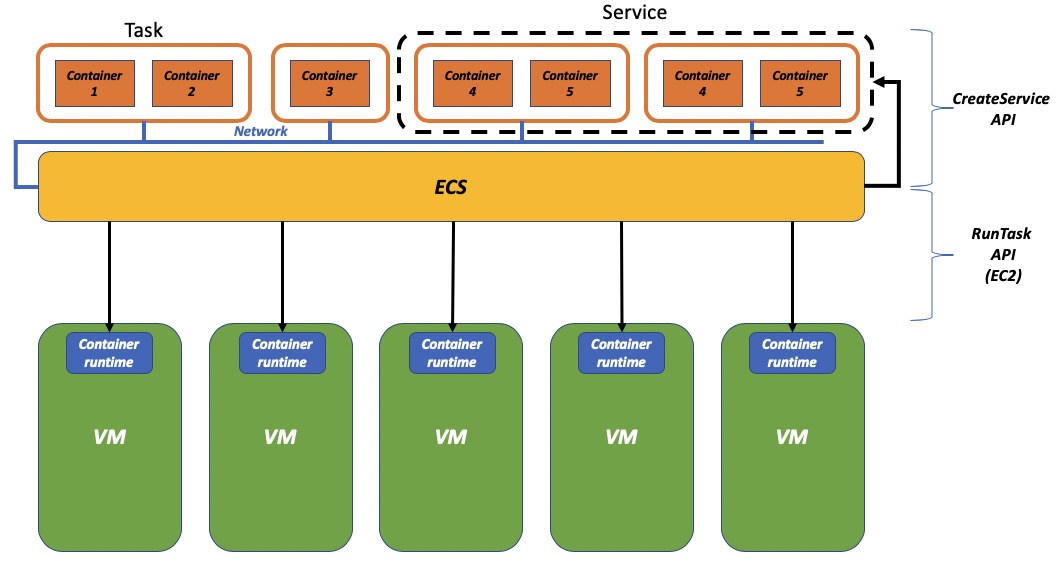
The picture below tries to capture these two dimensions associated to the container orchestrators: the higher order definition with the notion of “services” and “deployments” (north-bound) and the abstraction of the capacity with the scheduling of the tasks and pods on virtual machines (south-bound).

Services abstraction and infrastructure abstraction
As you can depict from the picture above, the orchestrator is responsible for a lot of the moving parts of a standard container deployment workflow. In the context of ECS specifically, you can think of two APIs that map the different richness of capabilities: the "RunTask" API and the "CreateService" API.
You can think of the "RunTask" API as the capability of running a task, which has one or more containers in it, on a distributed fleet of EC2 instances in your account (south-bound capability). This is the new “docker run” if you will that, instead of running a container on your laptop, runs a task on one of the available virtual machines that comprise your ECS cluster.
On the other hand, you can think of the "CreateService" API as a representation of the north-bound capabilities of grouping together a number of tasks configured to expose an application service via a load balancer. There isn’t really a Docker primitive you could map this to because the "CreateService" API is a higher-order abstraction introduced by an orchestrator. The "CreateService" API consumes the "RunTask" API to make sure that the desire state of the application is achieved.
To be crystal clear, of course ECS provides way more features and APIs. However, for the sake of this blog post, we are going to use the "CreateService" API and the "RunTask" API to represent these layers of the orchestrator: one that is closer to the higher level application abstraction and one that is closer to the lower level infrastructure abstraction.
For example, when we talk about the "CreateService" API we mean to include all the mechanisms of orchestrating the atomic tasks. This may include a directive to run a certain amount of tasks per service, a directive to run a single task on every virtual machine in the cluster or a configuration to scale in and out the tasks in the service.
On the other hand, when we talk about the "RunTask" API we mean to include the sophisticated scheduling algorithms to place a given task on a virtual machine in the cluster as well as all the mechanisms to scale in and out the number of virtual machines that comprise the cluster. It is amazing how labor intensive and configuration heavy some of these cluster scaling algorithms are.
Enter AWS Fargate
When we introduce a new AWS service, we typically do so by introducing a new API and a new console (when and if applicable). When we introduced the Fargate service, we did not introduce any new console nor a new API. This is probably something that users took a while to digest and box in their head. This is also probably where users need to start thinking about and understand the difference between the "product" and the "technology".
Fargate is a serverless environment for running containers that allows users to completely remove the need to own, run, and manage the lifecycle of a compute infrastructure. Think about it as elastic compute capacity at cloud scale against which you can run your tasks and pods without thinking about server boundaries.
In other words, Fargate provides the majority (if not all) of the south-bound capabilities that traditional container orchestrators usually solve for: how do I turn discrete virtual machines into a flat pool of resources that I can scale in and out based on specific needs and on top of which I can schedule my tasks and pods?
At this point, we were at a cross road. We had the “technology” and it looked like it had a lot of potential. How do we build the “product”? How do we make Fargate real so that customers can consume it and take advantage of the (south-bound) features it provides?
We could introduce a new dedicated Fargate API (e.g. RunFargateContainerGroup) which would be similar to the ECS RunTask API in all sense and purposes (at the high-level positioning).
Or alternatively, the RunTask API could have encompassed Fargate and become “the Fargate API.”
As you may be aware, we opted for the latter option and in fact, today, you can use the RunTask API with the "--launch-type" flag to discriminate between launching your task on the EC2 instances in your accounts or on the AWS owned and managed Fargate fleet. This is a visual representation of how you can think of Fargate:
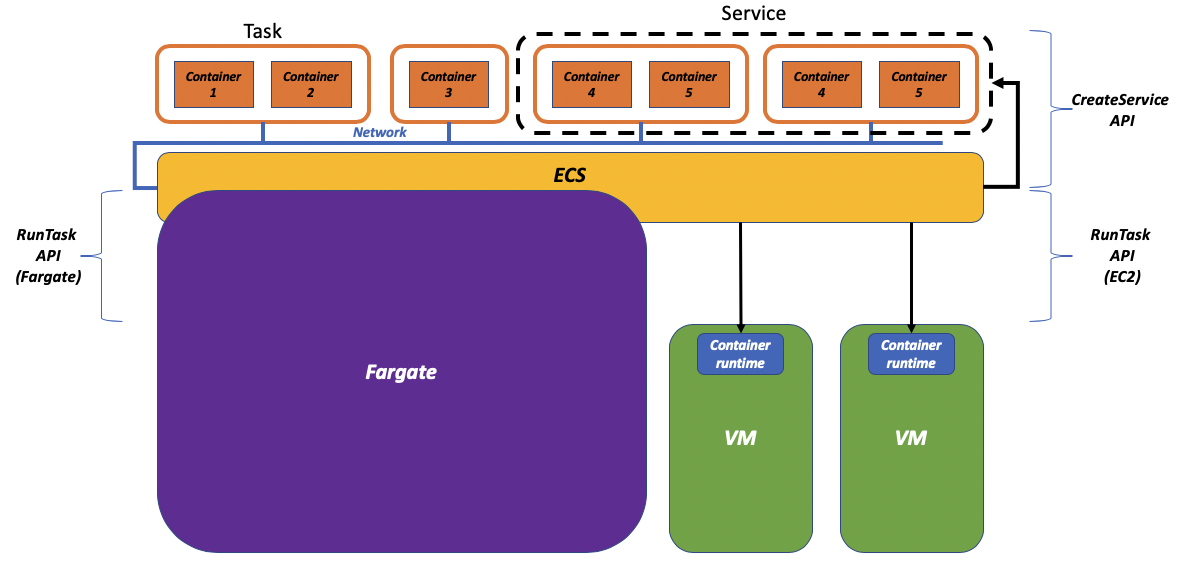
If you want to get more details about how this works behind the scene we highly encourage you to watch this re:Invent 2019 session, a deep dive on Fargate that covers in much more detail how this all works.
One of the benefits of building the Fargate "product" leveraging the RunTask API is that Fargate could take advantage, out-of-the-box, of the higher level (north-bound) features offered by ECS.
While we believe that solving customer problems is what we should care about, we also realize that this dichotomy between Fargate “the technology” and Fargate “the product” may have led to some misleading discussions.
Does it make sense to say “we are using Fargate and not ECS” or “I need to decide whether to use Fargate or ECS”? Well yes and no.
Some people tend to over-index on the Fargate "product" and on the problems it solves south-bound and perceive the higher-level north-bound application abstractions (when they use them) as a natural extension to what Fargate provides. As opposed to the mechanics of dealing with an ECS cluster comprised of discrete EC2 container instances. These customers tend to think about this stack and what they are using as “Fargate.”
However, some people tend to over-index more on the problems that the north-bound ECS service definition layer solves for them and they think of the stack they are using as “ECS.” In this case, the Fargate “technology” often becomes a discussion about an alternative to EC2 and positioned as an additional data plane on top of which running their tasks. As a side note, it is worth noting that we continue to make EC2 based clusters as easy to manage as possible. ECS has recently introduced ECS Capacity Providers that have made the management of customer managed EC2 instances a lot more efficient and integrated with ECS. If you want to know more about these functionalities, please refer to this re:Invent 2019 deep dive.
Amazon EKS and Fargate integration
At re:Invent 2019, we announced the integration between Amazon Elastic Kubernetes Service (EKS) and AWS Fargate. This has thrown an interesting curve-ball in the industry especially because users were already comparing “Fargate Vs. Kubernetes” similarly to how they were comparing “Fargate vs. ECS.”
We originally thought we could achieve this integration leveraging the virtual kubelet project, however, we soon realized we would have not been able to honor our commitment to use Kubernetes upstream if we were to go down this path. We have then decided to build this integration “by the book“ and leverage standard extension mechanisms that exist within Kubernetes. This includes mutating webhooks and custom schedulers.
In this case, because Kubernetes doesn’t have a serverless notion and always assumes there is a node, Fargate acts as a vending machine for AWS owned and managed compute capacity. Fargate becomes a container data plane for Kubernetes. Fargate vends infrastructure capacity in the form of virtual machines to the EKS cluster. These virtual machines, equipped with the various Kubernetes agents required, get connected to the cluster on-the-fly and are used to schedule the K8s pods that have been configured to run on Fargate. This is why, when you start a K8s pod on Fargate, you see the associated dedicated “worker node” vended by Fargate being made available to the EKS cluster.
Because of this, we rarely hear customers saying they use “Fargate” in this case but they’d rather say they use “EKS with a Fargate data plane.” This is a high-level visual representation of this process:
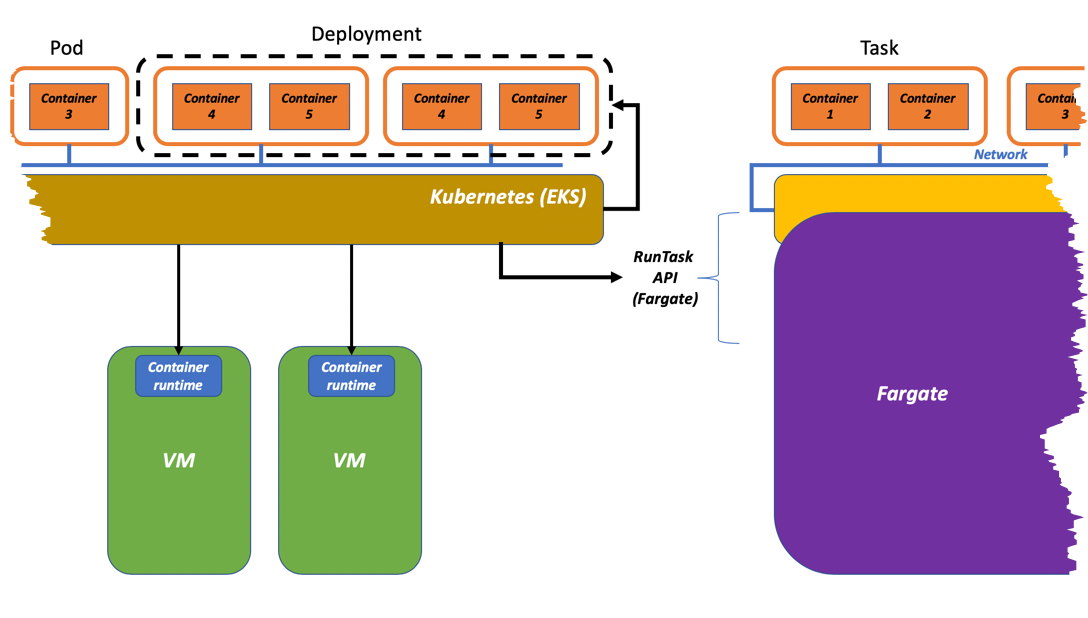
The Kubernetes custom scheduler running on EKS decouples the upstream Kubernetes cluster from the AWS specific implementation of the container serverless data plane (Fargate). As you can see from the picture above, the custom Fargate scheduler we deploy on EKS calls the "RunTask" API to schedule a pod.
The diagram below, which is part of the re:Invent 2019 deep dive on this integration, shows the details of this de-coupling. In addition to that, the diagram shows what happens when a standard pod definition is sent to the Kubernetes API endpoint where it is mutated, sent to the custom scheduler, and instantiated on Fargate.
Step #4 is when the external “RunTask” API call is being made:
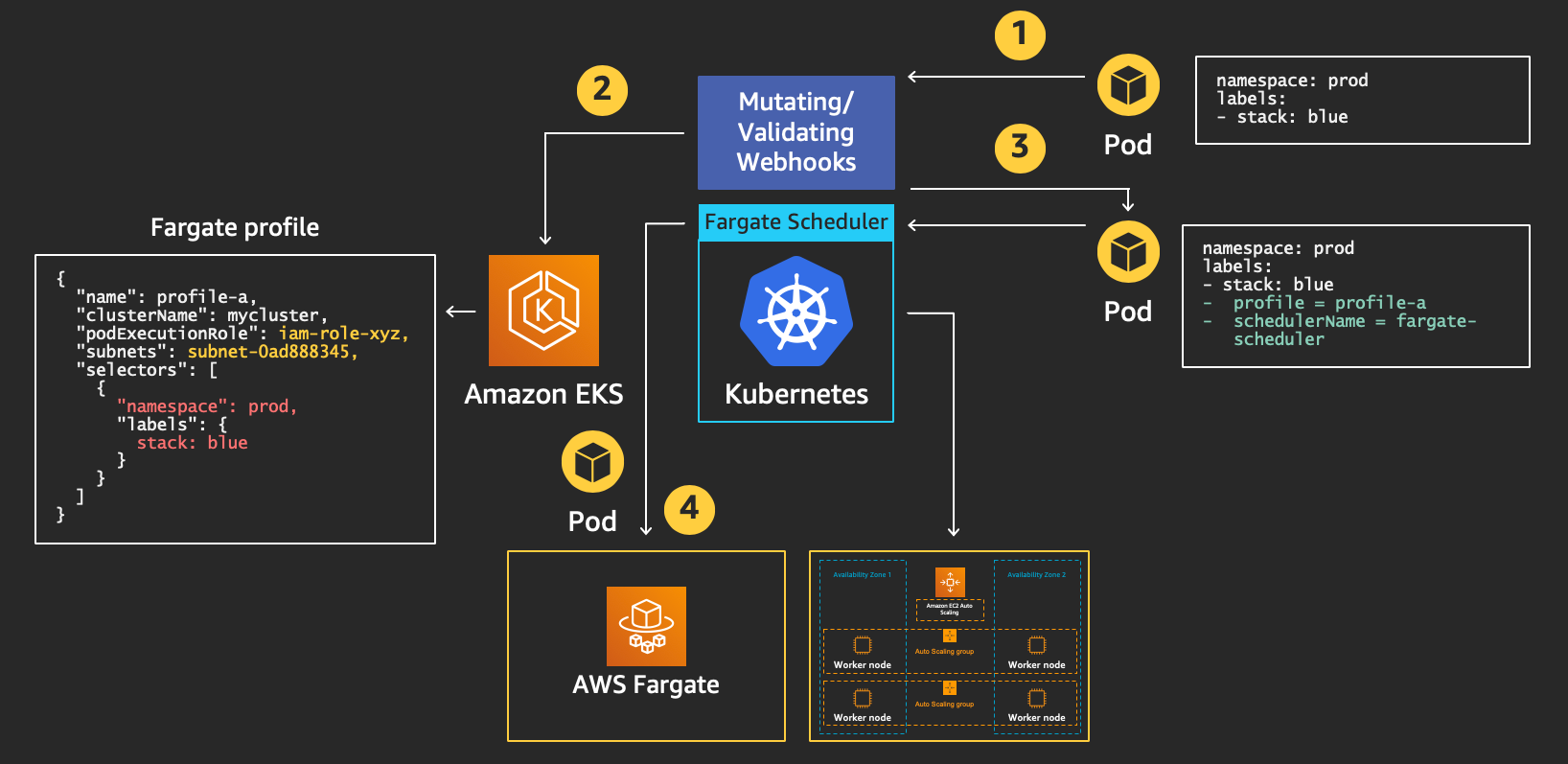
In general, the "RunTask" API remains the way builders can integrate directly with Fargate to consume core serverless container runtime functionalities as a service. This is how, for example, the EKS team is leveraging Fargate as a Kubernetes data plane in addition to EC2.
Perception is reality
As alluded to at the beginning, this blog is meant to give you some insights about how we are thinking about EKS, ECS, and Fargate. Hopefully it has cleared the air from some of the misconceptions about how to position and think about these technologies. As you may have understood by now, this is also a perception problem. This is a particular case where your very own perception of the problems and the associated solutions may drive your mental model of how you position these technologies.
We have seen people thinking of Fargate as the solution to their problems and welcoming the polyglot nature of it in supporting multiple application definition semantics (ECS and Kubernetes). These users tend to think of Fargate as the product they are using:
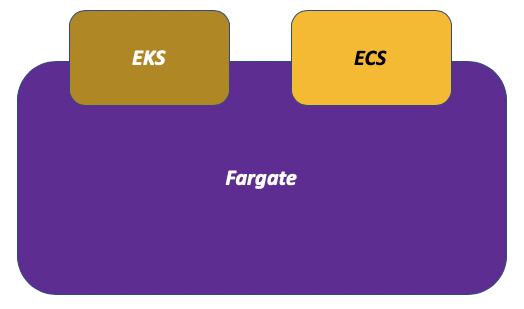
Other people instead think the north-bound functionalities of the container orchestrator are key to solve their practical problems. These users tend to think about Fargate more of an alternative data plane technology:

As they saying goes, perception is reality. The two diagrams above are two very different ways to look at the very same technology capability. And there is nothing wrong with that.
Conclusion
In this blog post, we covered at a high level some of the technology background and product choices behind AWS Fargate and in particular how it relates to the various adjacent technologies that exist in the AWS container portfolio (namely ECS and EKS). As we said, solving real problems is our priority, but it is however important to understand the underpinning details to be able to take apart a stack and be able to articulate what each part of the stack is responsible for. This is ultimately extremely important in the context of being able to re-integrate these pieces in a different way. For example, if you are an AWS technology partner (or a builder in general) it is important that you understand what Fargate is in order to be able to integrate with it. If nothing, having a common language helps these discussions and this blog post was intended to improve that clarity. If you are new to AWS Fargate, click here to get started.