Containers
Fluentd considerations and actions required at scale in Amazon EKS
Fluentd is a popular open source project for streaming logs from Kubernetes pods to different backends aggregators like CloudWatch. It is often used with the kubernetes_metadata filter, a plugin for Fluentd. The filter enriches the logs with basic metadata such as the pod’s namespace, UUIDs, labels, and annotations. It collects this information by querying the Kubernetes API server. While cluster and pod metadata is useful for identifying where logs originated from, frequently querying the API server can have a profound impact on the cluster, particularly when operating at scale. In this blog, we analyze the impact the plug-in has on the Kubernetes API and recommend how to optimally configure Fluentd and the kubernetes_metadata plug-in in large clusters.
Kubernetes logging and Fluentd
Metrics, logs, and traces are the three fundamental pillars of observability. Logs play a particularly crucial role because they are application/runtime specific and are frequently correlated with traces and metrics to help identify an issue’s root cause. When you run a containerized application on a Kubernetes cluster, the kubelet automatically stores logs written to stdout and stderr in the /var/log/containers directory on each worker node. However, these logs are not stored indefinitely. When a Kubernetes pod is evicted or deleted, the logs associated to that pod are permanently removed from the worker node. Since the loss of these logs can be detrimental to compliance and debugging, logs are stored outside the cluster. Elasticsearch, Amazon CloudWatch, Loki, Splunk, and SumoLogic are among the multitude of backends available for aggregating and analyzing logs emitted by containers.
There are a variety options for streaming logs from containers to an external backend like CloudWatch. For example, you can use a logging sidecar that reads logs written to a volume shared between the application and logging containers. With this approach, you can handle multiple log streams from your application container, e.g. when your application produces logs with different log formats and where the mixing different log formats would deteriorate the manageability of your logging pipeline. Another way to capture logs is with a Kubernetes DaemonSet. With a DaemonSet, only one logging agent per node is required.
Fluentd is an open source data collector that lets you unify the collection and consumption of data from your application. It is often run as a “node agent” or DaemonSet on Kubernetes. With Fluentd, you can filter, enrich, and route logs to different backends. It is popular with the community because it has broad support for various data sources and outputs such as application logs (e.g., Apache, Python), network protocols (e.g., HTTP, TCP, Syslog), and cloud APIs (e.g Amazon CloudWatch and Amazon SQS).
The configuration for Fluentd is controlled via a configuration file. The default configuration for the Kubernetes Fluentd Daemonset can be found in the kubernetes.conf file. The <source> blocks in the configuration instructs Fluentd where to find logs.
Challenges with “kubernetes_metadata” filter at scale
kubernetes_metadata is a filter used to enrich and add context to logs streamed by Fluentd. With this filter, basic metadata about the container is appended to each log record, making it easier to track the origin of a log entry. To enrich the logs, Fluentd has to interact with the Kubernetes API server to retrieve several pieces of metadatas such as:
- Namespace
- pod_name/pod_id
- Labels/Annotations
Each time a pod is created, the filter will call the get-pod method to retrieve this metadata from the Kubernetes API server. If the metadata filter is configured with a watch, it will also call the watch-pod method to keep track of updates to pods (more information at Kubernetes API Concepts). These API calls place an additional burden on the Kubernetes API, which can increase API latency and cause the cluster to become non-responsive or slow. Consider the impact of these API calls on the API server while running production workloads, especially as the number of worker nodes and pods increases.
Lab setup for testing:
In order to analyze the impact of the watch attribute, we created a lab environment with the configuration shown below. For simplicity, we used CloudWatch Logs as the destination and CloudWatch Log Insights to analyze the logs:
Kubernetes Version: 1.19
Enabled All Control Plane Logs
Worker Node Count: 200 - M5.2xlarge Instances
Max Pod Count: 1800 Pods - each pod generates ~ 100 Apache Logs/s
Fluentd Image Used : fluent/fluentd-kubernetes-daemonset:v1.12-debian-cloudwatch-1
Default FluentD Configuraitons Used - watch feature enabled by default
Fluentd is running as deamonset on each workerAnalysis and findings
During our tests, we gradually scaled our cluster up to 200 m5.2xlarge instances and ran 1,800 application pods with each pod generating roughly ~100 Apache log events per second. We also deployed FluentD as a DaemonSet.
As we increased the number nodes and pods, the first things that stood out were the increases to the “apiserver request latency” and “apiserver request rate”. As you can see from the chart below, the API request count more than doubled from initially ~100 req/s to ~220 req/s with 52 LIST, 46 GET and 41 WATCH requests:

Next, we analyzed the details of those API requests using Amazon Elastic Kubernetes Service (Amazon EKS) control plane logs and CloudWatch Log Insights. We found that Fluentd, which is identified as the “rest-client/2.1.0” user-agent, generates an excessive number of API calls against the Kubernetes API server within a relatively short period of time. We observed that it generated around ~13,283 LIST requests in aggregate.
CloudWatch Log Insight query for the top ten API talkers for “LIST”:
filter @logStream like "kube-apiserver-audit"
| filter ispresent(requestURI)
| filter verb = "list"
| filter requestURI like "/api/v1/pods"
| stats count(*) as count by userAgent
| sort count desc
# Get top ten LIST drivers
| limit 10Top ten API talkers for “LIST” calls

As we dug deeper into these requests, we found that Fluentd (rest-client/2.1.0) overwhelms the Kubernetes API server with thousands of GET (~ 36,400) and LIST (~27,800) requests without any production workloads running in the cluster as seen below:
CloudWatch Log Insight query for the request count to API server by user agent and verb:
fields userAgent, requestURI, @timestamp, @message, requestURI, verb
| filter @logStream like /kube-apiserver-audit/
| stats count(userAgent) as cnt by userAgent, verb
| sort cnt descTop verbs towards API server by userAgent:

Based on our analysis, using Fluentd with the default the configuration places significant load on the Kubernetes API server. As your cluster grows, this will likely cause API latency to increase or other control plane failures that could impact other workloads running in your cluster. We recommend that you analyze and monitor the control plane as to avoid any negative impact to your clusters. In addition to elevated latency, you may also experience control plane errors after reaching a certain scale, for example:
E0526 11:39:25.561474 1 status.go:71] apiserver received an error that is not an metav1.Status: &tls.permamentError{err:(net.OpError)(0xc05b320af0)} To decrease the load on the API server, we tried setting the watch attribute to false in our Fluentd configuration.
After disabling the watch at the 21:10 mark (see the dotted horizontal marker), the number of API requests issued against the API server per second decreased significantly while the log delivery workload remained the same.

Fluentd no longer issues an excessive number of “LIST/GET” calls to the API anymore and the number of requests comes down to reasonable levels as shown below:
Top ten API talkers for “LIST” calls after disabling watch
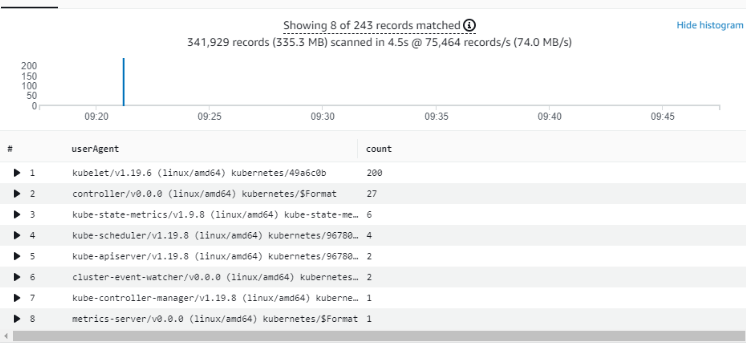
Given that disabling the watch attribute in the filter can significantly decrease the load on the API server, we recommend disabling this feature on all mid/large sized EKS clusters. We feel that disabling the watch far outweighs the benefits of detecting when changes to the metadata occur. Moreover, in EKS clusters where pods are seldom recycled/updated, there is little need for this feature.
Before changing your production configuration, we highly suggest you to test such changes in your non-production environment first and ensure you do not have any dependency for the changes in metadata after pods are created.
If, on the other hand, you still have a dependency on the watch feature, you can reduce the number of API calls against API server is setting K8S_NODE_NAME environment variable within your Fluentd DaemonSet. This configuration restricts the pod list to the worker node (more details kubernetes_metadata_filter):
env:
- name: K8S_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeNameAs also seen in the source code of the kubernetes plugin, having watch feature enabled expects you to set K8S_NODE_NAME as well and it explicitly warn/logs about its impact on Kubernetes API server as follow:
if @watch
if ENV['K8S_NODE_NAME'].nil? || ENV['K8S_NODE_NAME'].strip.empty?
log.warn("!! The environment variable 'K8S_NODE_NAME' is not set to the node name which can affect the API server and watch efficiency !!")
endIn order to evaluate impact of this optimization, we set the watch to true and defined K8S_NODE_NAME within our setup. Here are our findings:
- First, although that configuration did not stop the filter from issuing API calls, it reduced the “LIST” calls dramatically. This mitigates the risk of overloading the API server to some extent, however, it still generates a relatively high number of “GET” calls as seen below:
Top verbs towards API server by userAgent with watch Enabled and K8S_NODE_NAME:
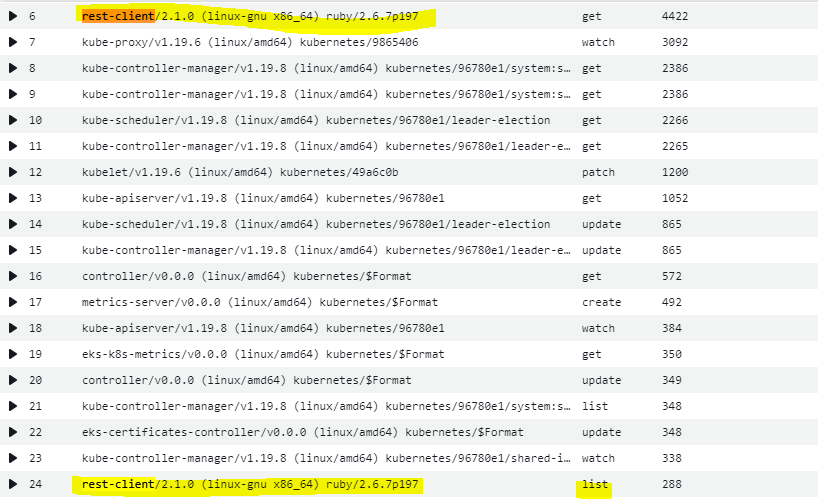
- Additionally, setting that environment variable will increase CPU utilization at pod level by 25-30% as seen below:

Note: between 11:30-11:40 where the watch enabled but K8S_NODE_NAME is not set
Migrating to from Fluentd to the AWS Fluent Bit image in Amazon EKS
Fluent Bit is another open source and multi-platform log processor and forwarder that allows you to collect data and logs from different sources. It is becoming a popular log forwarder to run on edge locations such as worker node. Compared to Fluentd, Fluent Bit has the following major advantages when it comes to log delivery at scale within large EKS/Kubernetes clusters:
- High log delivery performance and similar resource utilization footprint: At similar log volumes, Fluentd consumes over three times the CPU and four times the memory than the Fluent Bit plug-in consumes (see Fluent Bit Integration in CloudWatch Container Insights for detailed benchmarking stats)
- Minimal load on API server For metadata: Like Fluentd, the Fluent Bit Kubernetes filter talks to the Kubernetes API server to enrich logs with metadata such as the pod_id, labels, and annotations. However, Fluent Bit achieves this task using a more robust and lightweight approach that does not impact API server as much as Fluentd does.
- Being able to localize log metadata enriching at the node level rather than the API server endpoint: With the recent improvements released in the AWS for Fluent Bit image, Fluent Bit is able to retrieve metadata information directly from local Kubelet rather than querying API server. This decreases the volume of calls to the kube-apiserver and increases your ability to run Kubernetes at scale. See “Scaling the Fluent Bit Kubernetes filter in very large clusters” for more detail.
- “AWS for Fluent Bit” image: AWS provides an official container image called AWS for Fluent Bit that is supported and maintained by AWS. The image currently includes output plug-ins for CloudWatch Logs, Kinesis Firehose, and Kinesis Streams. Additional output plug-ins, such as S3, DataDog, Elasticsearch, etc are available with the upstream version of FluentBit
- Integration with Container Insights: The latest version of Container Insights uses the AWS for Fluent Bit image rather than Fluentd.
- Simpler configuration format
Considering the advantages outlined above, we highly recommend using Fluent Bit to stream logs in EKS clusters whenever possible. In case you already have Fluentd running in your EKS clusters, we encourage you to start to planning your migration from Fluentd to the AWS Fluent Bit image, at least on EKS worker nodes.
If you initially deployed Container Insights with Fluentd and are interested in transitioning to FluentBit, see FluentBit integration in CloudWatch Container Insights for EKS. For those who use Fluentd without Container Insights and want to switch to FluentBit, please visit https://github.com/aws/aws-for-fluent-bit for information about the AWS FluentBit image and the official Fluent Bit documentation.
Recommendations when using Fluentd
Admittedly, Fluentd addresses many use cases that make it a good choice for certain Kubernetes workloads. We also recognize that migrating away from Fluentd may not be feasible in the short-term. This could be due to a plug-in dependency or perhaps you simply need more time to plan your migration. In these cases, we’d like you to consider transitioning Fluent Bit by running Fluent Bit as a DeamonSet on each worker node and forwarding logs to a Fluentd service/deployment as shown in the diagram below. With this approach, you can still use Fluentd for enrichment, filtering, etc before shipping the logs to their final destination.
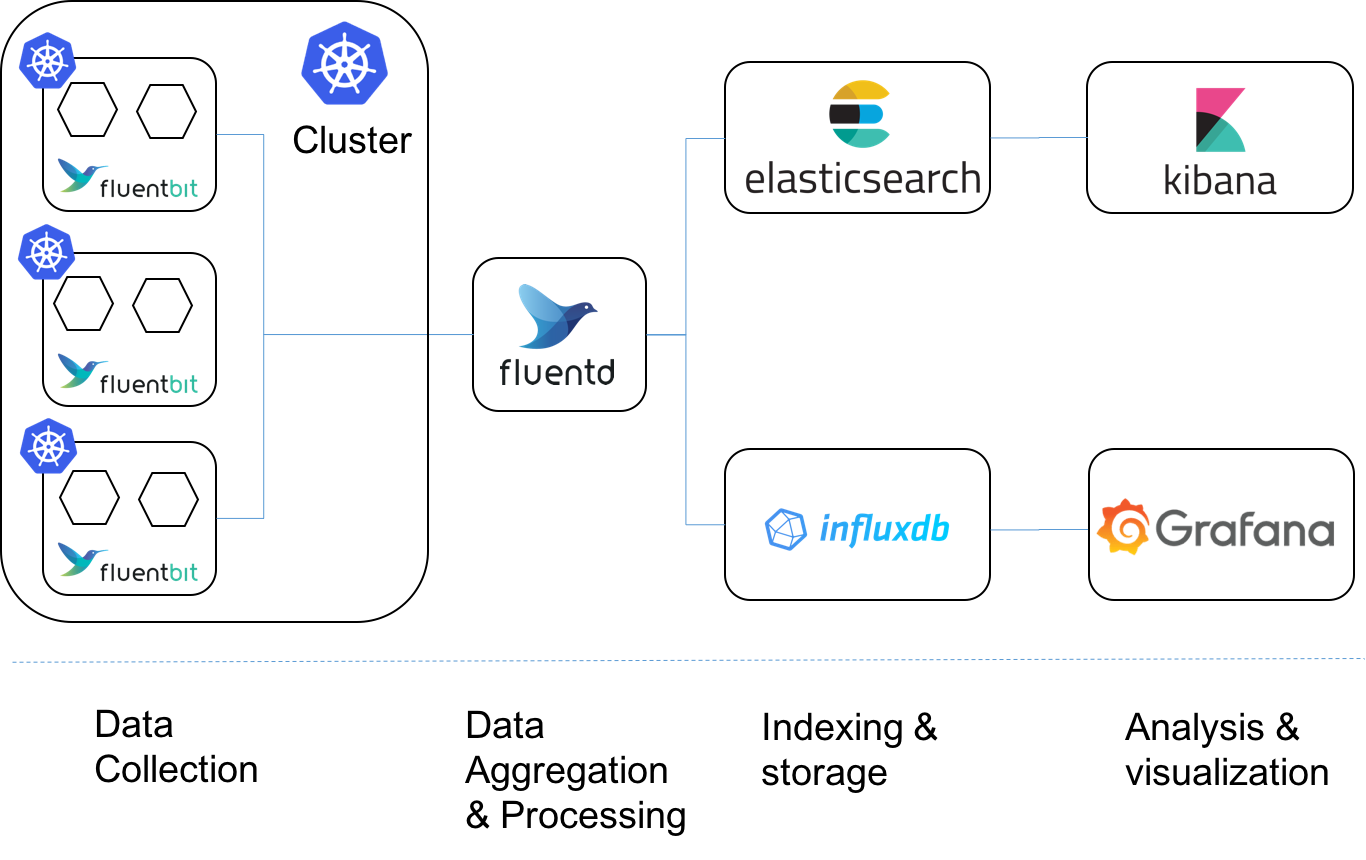
Fluentd best practices and considerations at scale
If you need to run Fluentd for any reason, we highly encourage you to review your existing configuration and verify that the following best-practices are in place:
1. Disabling watch feature in kubernetes filter, especially for the clusters that have long-running pods: In order to prevent excessive API calls, you need to set watch to false in the kubernetes_metadata filter as explained above.
2. Configuring the Fluentd DaemonSet to use K8S_NODE_NAME: If you have dependency on the watch feature, make sure that K8S_NODE_NAME environment variable is set as this will reduce the load to some extent before impacting your application’s performance. This will reduce cache misses and excessive calls to the Kubernetes API.
env:
- name: K8S_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName3. Stopping the delivery of unnecessary metadata/information at source: By default, while enriching the logs, the metadata filter appends metadata information such as annotations and labels into the log entries. This behavior not only increases log size and bandwidth consumption but also degrades performance of your log delivery pipeline. However, the Kubernetes metadata filter plugin allows you to ignore the metadata you are not interested in by configuring it with the following options:
-
skip_labels– Skip all label fields from the metadata.skip_container_metadata– Skip some of the container data of the metadata. The metadata will not contain the container_image and container_image_id fields.skip_master_url– Skip the master_url field from the metadata.skip_namespace_metadata– Skip the namespace_id field from the metadata. The fetch_namespace_metadata function will be skipped. The plugin will be faster and CPU consumption will be less
If you are sending logs into CloudWatch Logs, you can remove Kubernetes metadata from being appended to log events by adding the following line to the record_transformer section in the Fluentd configuration:
remove_keys $.kubernetes.pod_id, $.kubernetes.master_url, $.kubernetes.container_image_id, $.kubernetes.namespace_idBy keeping the log delivery constant and skipping the unnecessary collection of metadata, we saw a reduction of network bandwidth and memory utilization as shown below:
-
- Although CPU utilization per Fluentd remained similar, memory utilization per pod decreased by 60% from ~300 MB to ~140 MB
- Bandwidth usage to deliver the logs is decreased by 25 % from 1.93 MB/s to 1.43 MB/s
Impact of skipping unnecessary metadata:
| CPU Utilization | Memory Utilization | Network Utilization | |
| Without Skips in Place | 0.92 vCPU | 302 MB | 1.93 MB/s |
| With Skips Optimization | 1.00 vCPU | 131 MB | 1.43 MB/s |
4. Specifying resource requests and limits for Fluentd: As with all pods, you should set resource requests and limits to prevent containers from consuming the lion’s share of the host’s resources and starving other containers of resources. This is particularly important in large clusters where add-ons like Fluentd consume more than their default limits (250m/1Gi). If a large cluster is deployed without adjusting these values, the add-ons may get OOM killed or perform poorly. If you’re unsure of the amount of CPU/memory to allocate to the Fluentd container, consider running the VPA in “reporting” or “off” mode where VPA only recommends updates to be applied to pods. See Vertical Pod Autoscaler and https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler for further information.
5. Using cache size and cache TTL to reduce the requests to the API server: Fluentd v1.2.0 and above includes the following changes/parameters:
K8S_METADATA_FILTER_WATCH | Option to control the enabling of [metadata filter plugin watch (https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter#configuration)]. Default: `true`
K8S_METADATA_FILTER_BEARER_CACHE_SIZE | Option to control the enabling of [metadata filter plugin cache_size (https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter#configuration)]. Default: `1000`
K8S_METThe Kubernetes metadata filter outputs information about cache size, caches misses, and other data that can be useful when setting the cache size. Be aware that increasing the cache size can effect the memory requirements for Fluentd.
6. Avoiding extra computations: This is a general recommendation. It is suggested NOT TO HAVE extra computations inside Fluentd. Fluentd is flexible to do quite a bit internally, but adding too much logic to the configuration file makes it difficult to read and maintain while making it less robust. The configuration file should be as simple as possible.
Example:
de_dot – replace dots in labels and annotations with configured de_dot_separator, required for ElasticSearch 2.x compatibility (default: true)
https://docs.fluentd.org/parser/regexp
7. Watching for buffer overflow errors: A BufferOverflowError happens when output speed is slower than incoming traffic. So there are several approaches:
- Scale up/scale out destination when writing data is slow.
- Increase flush_thread_count when the write latency is lower. Launch multiple threads can hide the latency.
- Improve network setting. If network is unstable, the number of retry is increasing and it makes buffer flush slow.
- Optimize buffer chunk limit or flush_interval for the destination. For example, Kafka and MongoDB have different characteristic for data ingestion.
8. Monitor the queue length and error count: If these Prometheus metrics are increasing, it means Fluentd cannot flush the buffer to the destination. Once the buffer becomes full, you will start losing data:
# maximum buffer length in last 1min
max_over_time(fluentd_output_status_buffer_queue_length[1m])
# maximum buffer bytes in last 1min
max_over_time(fluentd_output_status_buffer_total_bytes[1m])
# maximum retry wait in last 1min
max_over_time(fluentd_output_status_retry_wait[1m])
# retry count / sec
rate(fluentd_output_status_retry_count[1m]) Summary
Considering challenges described above, we highly recommend you to consider to taking advantage of Fluent Bit for log delivery to reduce the load on your Kubernetes API server. In the event you still need to use FluentD within your cluster, consider configuring it in a way that will not impact your production workload based on the information above. For more details around using Fluent Bit with EKS Clusters, its performance advantages and recommended best practices, please see Fluent Bit Integration in CloudWatch Container Insights for EKS and to get insights around how such migration can happen with Container Insights for EKS as an example, please see Quick Start setup for Container Insights on Amazon EKS and Kubernetes
References:
https://fluentbit.io/blog/2021/01/25/Logging-Fluentd-with-Kubernetes/
https://medium.com/kubernetes-tutorials/cluster-level-logging-in-kubernetes-with-fluentd-e59aa2b6093a
https://dzone.com/articles/fluentd-vs-fluent-bit-side-by-side-comparison-logz