AWS Compute Blog
Translating documents at enterprise scale with serverless
For organizations operating in multiple countries, helping customers in different languages is an everyday reality. But in many IT systems, data remains static in a single language, making it difficult or impossible for international customers to use. In this blog post, I show how you can automate language translation at scale to solve a number of common enterprise problems.
Many types of data are good targets for translation. For example, product catalog information, for sharing with a geographically broad customer base. Or customer emails and interactions in multiple languages, translating back to a single language for analytics. Or even resource files for mobile applications, to automate string processing into different languages during the build process.
Building the machine learning models for language translation is extraordinarily complex, so fortunately you have a pay-as-you-go service available in Amazon Translate. This can accurately translate text between 54 languages, and automatically detects the source language.
Developing a scalable translation solution for thousands of documents can be challenging using traditional, server-based architecture. Using a serverless approach, this becomes much easier since you can use storage and compute services that scale for you – Amazon S3 and AWS Lambda:

In this post, I show two solutions that provide an event-based architecture for automated translation. In the first, S3 invokes a Lambda function when objects are stored. It immediately reads the file and requests a translation from Amazon Translate. The second solution explores a more advanced method for scaling to large numbers of documents, queuing the requests and tracking their state. The walkthrough creates resources covered in the AWS Free Tier but you may incur costs for usage.
To set up both example applications, visit the GitHub repo and follow the instructions in the README.md file. Both applications use the AWS Serverless Application Model (SAM) to make it easy to deploy in your AWS account.
Translating in near real time
In the first application, the workflow is straightforward. The source text is sent immediately to Translate for processing, and the result is saved back into the S3 bucket. It provides near real-time translation whenever an object is saved. This uses the following architecture:

- The source text is saved in the Batching S3 bucket.
- The S3 put event invokes the Batching Lambda function. Since Translate has a limit of 5,000 characters per request, it slices the contents of the input into parts small enough for processing.
- The resulting parts are saved in the Translation S3 bucket.
- The S3 put events invoke the Translation function, which scales up concurrently depending on the number of parts.
- Amazon Translate returns the translations back to the Lambda function, which saves the results in the Translation bucket.
When writing objects back to the same bucket, it’s important to use different prefixes or suffixes in Lambda notification triggers to avoid recursively invoking the same Lambda function. To learn more, read more about configuring S3 notifications.
The repo’s SAM template allows you to specify a list of target languages, as a space-delimited list of supported language codes. In this case, any text uploaded to S3 is translated into French, Spanish, and Italian:
Parameters:
TargetLanguage:
Type: String
Default: 'fr es it'
Testing the application
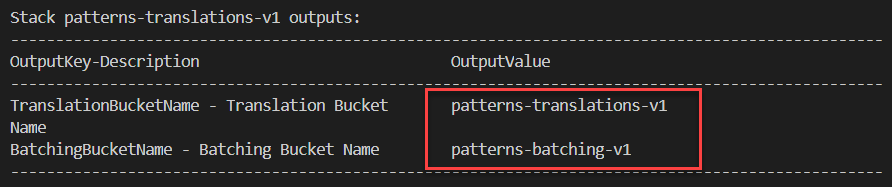
- Deploy the first application by following the README.md in the GitHub repo. Note the application’s S3 Translation and Batching bucket names shown in the output:
- The testdata directory contains several sample text files. Change into this directory, then upload coffee.txt to the S3 bucket, replacing your-bucket below with your Translation bucket name:
cd ./testdata/ aws s3 cp ./coffee.txt s3://your-bucket - The application invokes the translation workflow, and within a couple of seconds you can list the output files in the translations folder:
aws s3 ls s3://your-bucket/translations/
- Create an output directory, then download the translations to your local machine to view the contents:
mkdir output aws s3 cp s3://your-bucket/translations/ ./output/ --recursive more ./output/coffee-fr.txt more ./output/coffee-es.txt more ./output/coffee-it.txt - For the next step, translate several text files containing test data. Copy these to the Translation bucket, replacing your-bucket below with your bucket name:
aws s3 cp ./ s3://your-bucket --include "*.txt" --exclude "*/*" --recursive - After a few seconds, list the files in the translations folder to see your translated files:
aws s3 ls s3://your-bucket/translations/
- Finally, translate a larger file using the batching process. Copy this file to the Batching S3 bucket (replacing your-bucket with this bucket name):
cd ../testdata-batching/ aws s3 cp ./your-filename.txt s3://your-bucket - Since this is a larger file, the batching Lambda function breaks it apart into smaller text files in the Translation bucket. List these files in the terminal, together with their translations:
aws s3 ls s3://your-bucket aws s3 ls s3://your-bucket/translations/


In this example, you can translate a reasonable number of text files for a trivial use-case. However, in an enterprise environment where there could be thousands of files in a single bucket, you need a more robust architecture. The second application introduces a more resilient approach.
Scaling up the translation solution
In an enterprise environment, the application must handle long documents and large quantities of documents. Amazon Translate has service limits in place per account – you can request an increase via an AWS Support Center ticket if needed. However, S3 can ingest a large number of objects quickly, so the application should decouple these two services.
The next example uses Amazon SQS for decoupling, and also introduces Amazon DynamoDB for tracking the status of each translation. The new architecture looks like this:

- A downstream process saves text objects in the Batching S3 bucket.
- The Batching function breaks these files into smaller parts, saving these in the Translation S3 bucket.
- When an object is saved in this bucket, this invokes the Add to Queue function. This writes a message to an SQS queue, and logs the item in a DynamoDB table.
- The Translation function receives messages from the SQS queue, and requests translations from the Amazon Translate service.
- The function updates the item as completed in the DynamoDB table, and stores the output translation in the Results S3 bucket.
Testing the application
This test uses a much larger text document – the text version of the novel War and Peace, which is over 3 million characters long. It’s recommended that you use a shorter piece of text for the walkthrough, between 20-50 kilobytes, to minimize cost on your AWS bill.
- Deploy the second application by following the README.md in the GitHub repo, and note the application’s S3 bucket name and DynamoDB table name.

- Download your text sample and then upload it the Batching bucket. Replace your-bucket with your bucket name and your-text.txt with your text file name:
aws s3 cp ./your-text.txt s3://your-bucket/ - The batching process creates smaller files in the Translation bucket. After a few seconds, list the files in the Translation bucket (replacing your-bucket with your bucket name):
aws s3 ls s3://patterns-translations-v2/ --recursive --summarize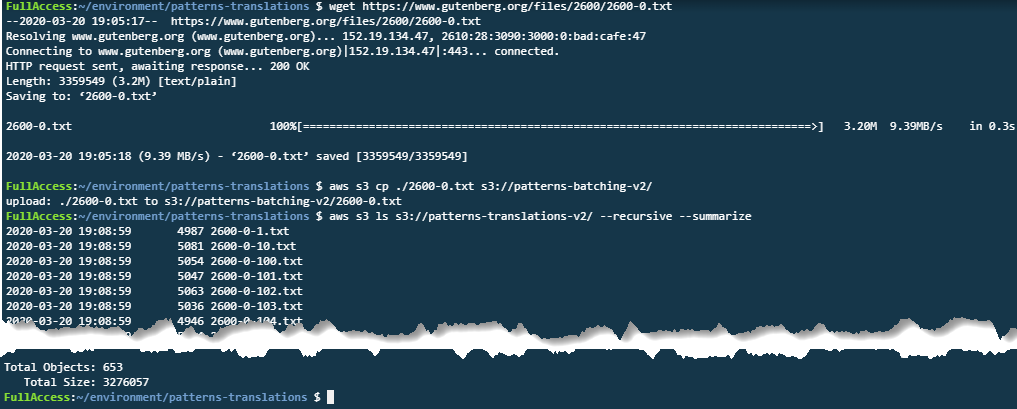
- To see the status of the translations, navigate to the DynamoDB console. Select Tables in the left-side menu and then choose the application’s DynamoDB table. Select the Items tab:
 This shows each translation file and a status of Queue or Translated.
This shows each translation file and a status of Queue or Translated. - As translations complete, these appear in the Results bucket:
aws s3 ls s3://patterns-results-v2/ --summarize

How this works
In the second application, the SQS queue acts as a buffer between the Batching process and the Translation process. The Translation Lambda function fetches messages from the SQS queue when they are available, and submits the source file to Amazon Translate. This throttles the overall speed of processing.
There are configuration settings you can change in the SAM template to vary the speed of throughput:
- Translator function: this consumes messages from the SQS queue. The BatchSize configured in the SAM template is set to one message per invocation. This is equivalent to processing one source file at a time. You can set a BatchSize value from 1 to 10, so could increase this from the application’s default.
- Function concurrency: the SAM template sets the Loader function’s concurrency to 1, using the ReservedConcurrentExecutions attribute. In effect, this means Lambda can only invoke 1 function at the same time. As a result, it keeps fetching the next batch from SQS as soon as processing finishes. The concurrency is a multiplier – as this value is increased, the translation throughput increases proportionately, if there are messages available in SQS.
- Amazon Translate limits: the service limits in place are designed to protect you from higher-than-intended usage. If you need higher soft limits, open an AWS Support Center ticket.
Combining these settings, you have considerable control over the speed of processing. The defaults in the sample application are set at the lowest values possible so you can observe the queueing mechanism.
Conclusion
Automated translation using deep learning enables you to make documents available at scale to an international audience. For organizations operating globally, this can improve your user experience and increase customer access to your company’s products and services.
In this post, I show how you can create a serverless application to process large numbers of files stored in S3. The write operation in the S3 bucket triggers the process, and you use SQS to buffer the workload between S3 and the Amazon Translate service. This solution also uses DynamoDB to help track the state of the translated files.