AWS Compute Blog
Tag: serverless

Building well-architected serverless applications: Building in resiliency – part 1
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL2: […]

Building a serverless multiplayer game that scales: Part 2
This post shows how you can add scaling support for a game via automation. The example uses Amazon Rekognition to check images for unacceptable content and uses asynchronous architecture patterns with Step Functions and HTTP WebPush.
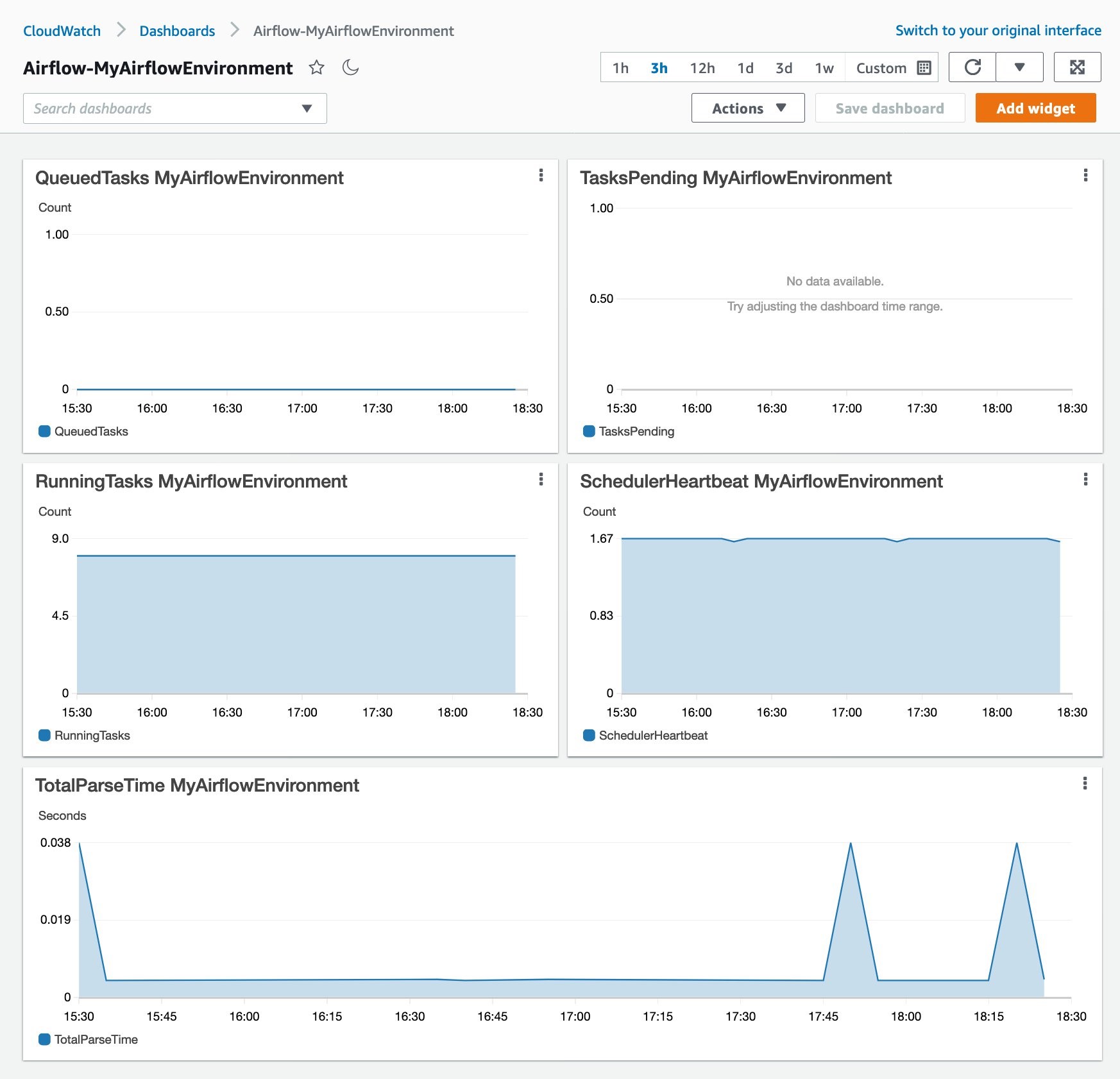
Automating Amazon CloudWatch dashboards and alarms for Amazon Managed Workflows for Apache Airflow
This article shows a serverless example that automatically creates CloudWatch dashboards and alarms for all existing and new MWAA environments. With this example, you can achieve better observability for your MWAA environments.

Building well-architected serverless applications: Regulating inbound request rates – part 2
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL1: […]

Creating a single-table design with Amazon DynamoDB
This post looks at implementing common relational database patterns using DynamoDB. Instead of using multiple tables, the single-table design pattern can use adjacency lists to provide many-to-many relational functionality.
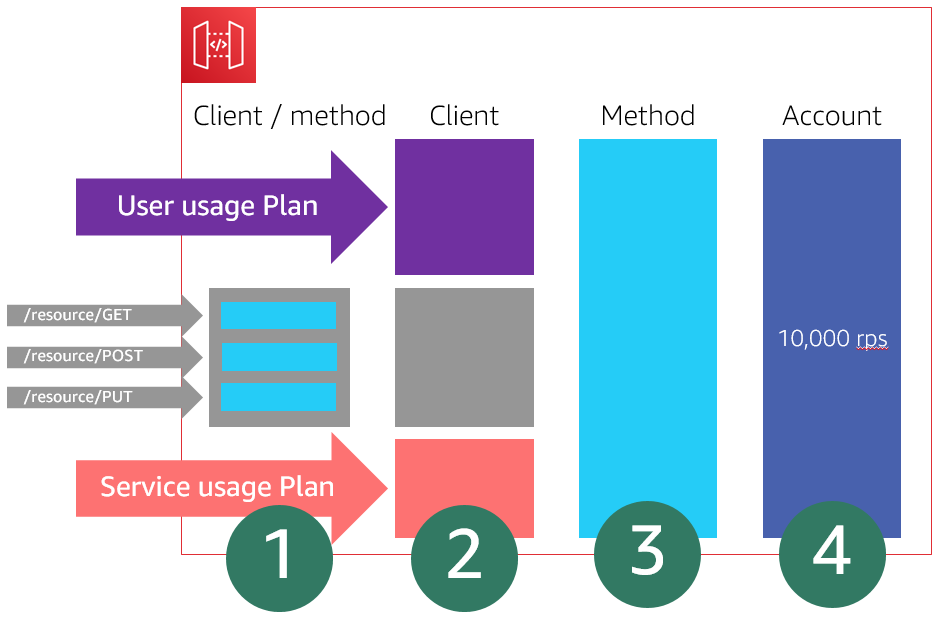
Building well-architected serverless applications: Regulating inbound request rates – part 1
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Reliability question REL1: […]

Introducing AWS SAM Pipelines: Automatically generate deployment pipelines for serverless applications
Today, AWS announces the public preview of AWS SAM Pipelines, a new capability of AWS Serverless Application Model (AWS SAM) CLI. AWS SAM Pipelines makes it easier to create secure continuous integration and deployment (CI/CD) pipelines for your organizations preferred continuous integration and continuous deployment (CI/CD) system. This blog post shows how to use AWS […]

Building well-architected serverless applications: Implementing application workload security – part 2
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application. Security question SEC3: […]

Coming soon: Expansion of AWS Lambda states to all functions
Update – December 20, 2021: We’re extending the General Update from December 5 2021 to January 31 2022. The End of Delayed Update date is now also changed to February 1 2022. Update – October 8, 2021: We’re extending the General Update from September 30 2021 to December 5 2021. The End of Delayed Update […]
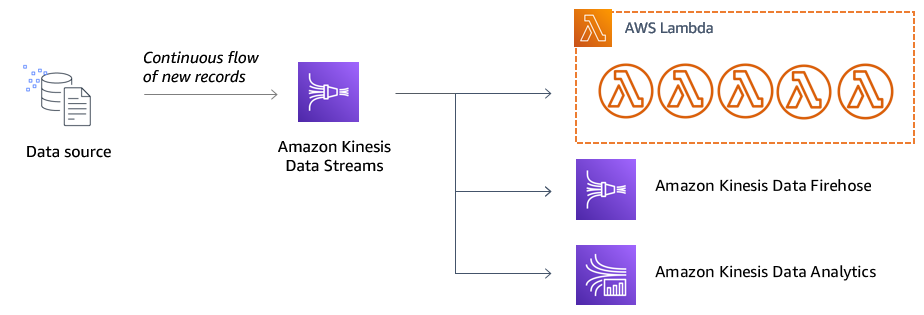
Understanding data streaming concepts for serverless applications
In this post, I introduce some of the core streaming concepts for serverless applications. I explain some of the benefits of streaming architectures and how Kinesis works with producers and consumers. I compare different ways to ingest data, how streams are composed of shards, and how partition keys determine which shard is used. Finally, I explain the payload formats at the different stages of a streaming workload, how message ordering works with shards, and why idempotency is important to handle.